本文简单谈一谈关于DDD的认知、思考

建立心智
关于领域模型的认知
抽象领域模型时,通常会遇到下述问题
- 如何进行合适的抽象?
- 抽象不出来怎么办?
- 过于抽象,是否会存在过度设计?使简单问题复杂化?
领域模型反映的是对问题空间的理解、认知,而对问题本质的认知本身就是渐进式的的过程。所以,需要适应认知规律,对领域模型进行持续探索、场景检验、演进沉淀。所以,不能要求一开始就能够构建出高质量、深层次、有共识的领域模型,也不存在所谓绝对正确的领域模型
建立、使用统一语言
如何建立统一语言,简单来说:
- 任何在需求描述中出现的概念,也都必须出现在模型中
- 如果需求描述中存在概念之间的关系,则模型中也必须有这种关系
如何使用统一语言:
- 将模型作为语言的中心。在团队交流活动(包括但不限于说话沟通、写文档、画图等)、代码中坚持使用这种语言
- 修改、消除模型与交流表达之间 不自然的地方。包括修改相应代码(模块名、类名、方法等)
使用统一语言的价值:
让领域模型真正发挥作用、价值,达成一致共识。而非仅仅是PPT概念
PRD 产品需求文档
关于PRD,需要注意的是写文档本身的过程不产生认知,结构化的梳理才会产生认知
问题空间
需求分析之方法论
Event Storming 事件风暴作为DDD中经常使用的需求分析、建模手段,其主要面向复杂业务领域,挖掘业务场景。具体地:
- 通过探索、识别、分析系统中发生的事件(所谓的领域事件,即从业务视角出发的关键、重要事件),来尽可能发现潜在、遗漏的业务场景、异常场景
- 通过协作让各方形成、建立对业务概念、场景的共识
- 通过梳理业务概念、场景发现、产出领域模型
- 发现领域边界、系统边界
其他常用的方法论有:
- Example Mapping 实例化需求:其是一种对需求分析、澄清的实践方法。通过使用具体的例子来阐述需求,从而解决自然语言的歧义性问题
- User Story Mapping 用户故事地图:将User Story用户故事按照不同的层次、时间顺序排列,形成产品的功能地图。在业务目标比较清晰的情况下,探索渐进的业务解法,并据此规划迭代
- Impact Mapping 影响地图:面向业务目标,从功能影响、业务价值的角度出发探索业务解法
- Use Case Analysis用例分析:结构化的展开、分析业务场景
- User Journey Mapping 用户旅程地图:又被称之为用户体验地图。其聚焦的是用户在产品使用、交互层面上的体感
领域划分
其是对问题空间的分解。需要从业务视角出发来划分领域,期望要求领域具备、体现出内聚的业务能力。需要注意的是,领域划分不是一蹴而就的,而是渐进式的。前期过程中由于信息不充分、认知不够、规模复杂度不足,领域划分可以不用非常到位、准确;但要保持持续演化的心智,在后期信息增加、认知提升、业务发展复杂度扩大时,对领域的划分进行重新思考、调整演进
领域划分的价值在于:
- 减少认知过程中的心智负担
- 减轻耦合、隔离变化
- 发现、分辨、提炼出最具业务价值的核心域 与 通用子域,同时重点聚焦于核心域
解决方案空间
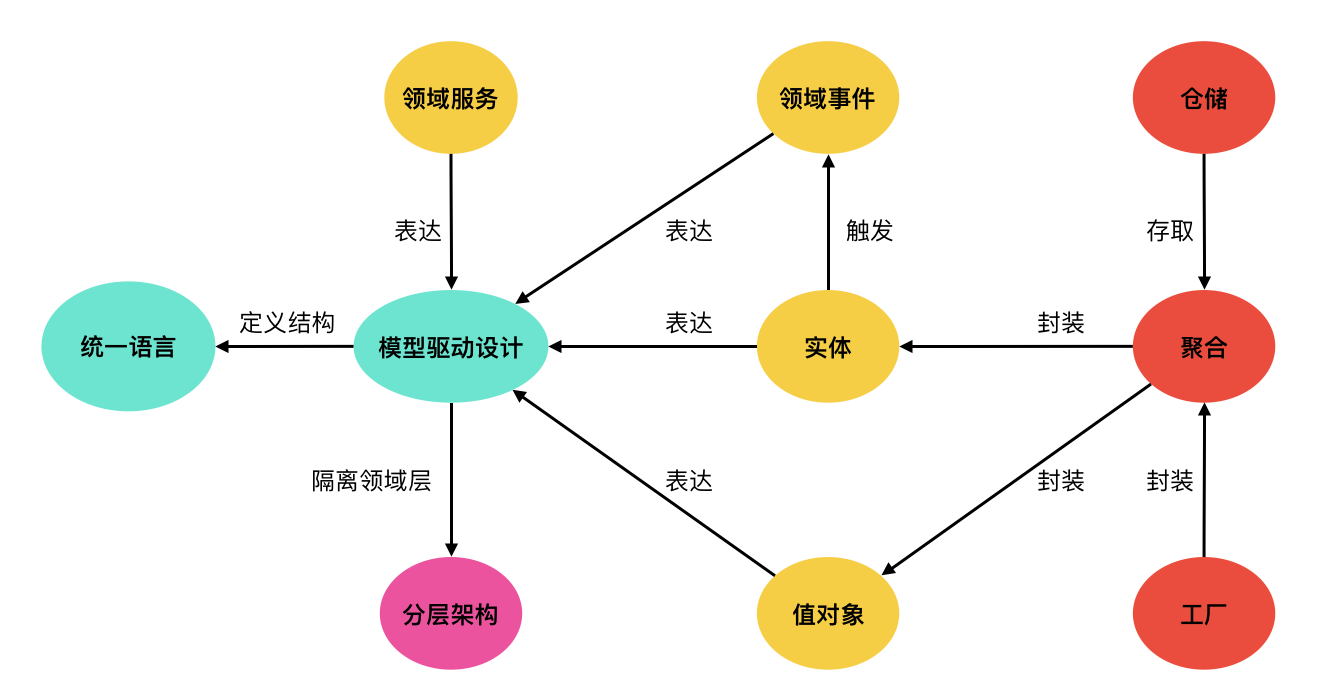
领域对象之Entity实体
这里的Entity实体与ORM框架中的实体不是同一个概念。DDD中的Entity实体,首先是具有重要业务含义的对象,同时该对象实例会随着业务变化发生状态、属性的变更(即是一个可变对象),为此我们需要有一个唯一的标识对专门其进行跟踪。例如,对于两个员工而言,就算他们的姓名相同(恰好重名了)、年龄也相同,我们也知道这是两个不同的员工。因为这两个员工的工号并不一样。所以我们通常会将员工视为实体
领域对象之Value Object值对象
值对象只是用来描述特征的,其属性值就可以完全可以用来表示自身了,并不需要一个专门唯一标识符来表示自己。换言之,只要两个值对象的属性值完全一样,我们就认为二者其实是同一个东西。故通常,值对象是不可变对象,即某个对象实例一旦被创建后,其属性值就不能再改变。如有需要,则需要使用另外一个具有相应属性值的对象实例了。而对于实体对象来说,即使两个实体对象的属性值完全一样,但二者的唯一标识符不同,我们也不能认为二者是相同的。大多数情况下,我们应该尽可能考虑使用值对象来建模而不是实体。例如,对于两个颜色来说,如果都是红色。我们显然认为这两个颜色都是同一种颜色;如果一个颜色是红色、另一个颜色是蓝色,那显然这两个颜色不是同一个东西
实现值对象的不可变性也很简单,只需保证对象通过构造器来创建后,没有任何办法来修改其属性值即可(例如,将属性全部设置为private,同时不提供setter方法等)。Java下可以直接利用枚举来实现
Entity实体 VS Value Object值对象
像员工这样有单独的标识,理论上可以改变的对象,就叫做Entiy实体;而像员工状态(例如,在职/离职)、颜色(例如,红色/蓝色/绿色)、货币(由面值、币种两个属性构成)这样没有单独的标识,并且不可改变的对象,就叫Value Object值对象。简单来说,从字面上理解,实体是一个“东西”;而值对象仅仅是一个“值”,往往用作描述实体的属性
Aggregate 聚合
选择一个实体作为聚合根,然后将相关的实体、值对象划分到聚合内来定义边界。由聚合统一封装相关逻辑并对外提供知识丰富的行为、方法,即所谓的充血模型。外部对象只能通过持有聚合这个整体的引用来对其进行操作;而不允许外部对象越过聚合,直接去持有聚合内的元素(实体、值对象等)并对其操作。因为后者会极容易导致聚合内各种元素(实体、值对象等)的数据发生不一致的情形。使用聚合的好处显而易见,提升了对象系统的颗粒度,保证了业务逻辑的完整性
DDD中领域对象间具有下述特征时,就可以考虑使用Aggregate聚合来实现。这里以员工、工作经历两个领域对象来举例说明
- 两个领域对象间存在整体-部分的关系。例如,员工是一个整体,而工作经历则是员工信息的一部分
- 业务规则在并发的时候可能会被破坏。例如,员工的多条工作经历的时间段不能存在交叉、重叠。为了防止该业务规则不被破坏,我们必须将该员工和其所有的工作经历作为一个整体锁住才能解决
同时,在划分聚合时,优先考虑的小聚合原则:即在不破坏业务逻辑完整性的基础上,使用更小的聚合范围会产生多个聚合。相比较于更大的聚合范围只会有少数几个聚合而言,前者可以带来更大的灵活性。作为一个Aggregate聚合而言,其最基本的作用就是为一组具有整体-部分关系的对象维护业务规则。通常具有如下一些特点:
- 在一个聚合中,代表整体的实体就是Aggregate Root聚合根(例如,上文的员工);而该聚合中的其他对象则被称为(聚合中的)非聚合根对象(例如,上文的工作经历)。显然,一个聚合只有一个聚合根
- 代表部分的实体,只能属于一个聚合根对象,不可能属于多个聚合根对象。例如,某段工作经历只能属于张三,不能既属于张三又属于李四
- 某个聚合的一部分,不能再变成其他聚合的一部分。例如,工作经历作为员工这个聚合的一部分后,就不能考虑将其再作为合同这个聚合的一部分了
- 当一个聚合根对象被删除,那么聚合中的所有对象都将会被删除。即所谓的生命周期一致性原则。事实上,这一点也可以用于帮助我们思考两个领域对象是否适合放在一起作为一个聚合
聚合的实现:
- 实现聚合时,对于 聚合根对象 和 (聚合中的)非聚合根对象 的关联,推荐直接使用对象关联,而非ID关联。因为使用对象关联的方式时,聚合根对象内部直接持有非聚合根对象的引用,此时大部分领域逻辑就可以直接在聚合根对象中实现了;而如果使用ID关联的方式,聚合根对象内部只持有非聚合根对象的ID,此时聚合就需要搭配、借助自己的领域服务来实现领域逻辑了
- 在聚合根对象中实现并对外提供了关于(聚合中的)非聚合根对象的创建、修改、访问等方法。(聚合中的)非聚合根对象不能由外界(即,聚合外部的对象)直接创建、修改,外界必须通过聚合根对象对外提供的方法才能对(聚合中的)非聚合根对象进行操作。为了保证外界不绕过规则的校验,可将一个聚合中的聚合根类、非聚合根类都放在同一个Java Package包下,然后将非聚合根类中的属性的setter方法设置为包访问权限(即不带任何访问修饰符,该模式下只允许在同一个包中进行访问)。这样外界对于(聚合中的)非聚合根对象的属性就只能读、不能写
Factory 工厂
在DDD中,领域对象的创建逻辑通常也会被视为领域层的一部分。所以如果创建领域对象的逻辑比较简单,可以直接通过构造器来实现;但如果创建领域对象的逻辑比较复杂时(创建时的校验规则复杂、领域对象的结构复杂等),为了保证聚合内的各种元素(实体、值对象等)数据的一致性、完整性。就应该把领域对象的创建逻辑维护到工厂Factory中,来保证领域对象的简洁、聚焦。这里的工厂Factory是广义上的,具体实现可以是工厂类/工厂方法、工厂模式、建造者模式等手段,甚至可以直接是个静态方法
Repository 仓储
Repository是聚合的仓储机制,其将聚合作为一个整体来进行管理的。外部世界能够也只能通过仓储来完成对聚合的访问。具体地,一个聚合只能有一个Repository仓储对象,同时该Repository仓储对象以聚合根命名。而且除了聚合外,其他对象都不应该有相应Repository仓储对象。这里需要注意的是,Repository仓储并不等价于持久化!更不是传统MVC架构下的DAO数据库访问层。因为Repository仓储在实现上时允许存在多种方案、技术手段,比如DB数据库、MQ消息队列、RPC接口等
Domain Service 领域服务
一般来说,领域逻辑最好是放到领域对象类当中。不过对于有些逻辑而言,当其不适合放到领域对象类时(例如,某个领域逻辑需要访问数据库,但为了保持领域对象与数据库之间的解耦。我们又不希望在该领域对象类内直接对数据库进行访问)。就可以考虑将它们放到一些只有方法、没有状态的类里面。此时,这个类就可以称之为Domain Service领域服务。通常领域服务描述的是某种业务规则或计算策略等。同时由于领域服务本身不持有数据,故其自身是无状态的。这里补充说明下,如何鉴别、区分某个逻辑是领域层的领域逻辑,还是应用层的应用逻辑?一个可以参考的思路是判断该逻辑是否需要和业务领域专家拉齐、敲定。如果需要则说明其是领域逻辑;反之,如果业务领域专家并不care,则说明其是应用逻辑
Domain Event 领域事件
其指的是在业务领域下发生的结果、事件。所以,对于系统宕机、网络通信故障这种非业务性的事件就不能认为是一个领域事件。当然Domain Event领域事件本身也是一种特殊的值对象。通常当聚合的状态发生变化即会产生领域事件。例如,订单聚合的状态由已支付变为已发货
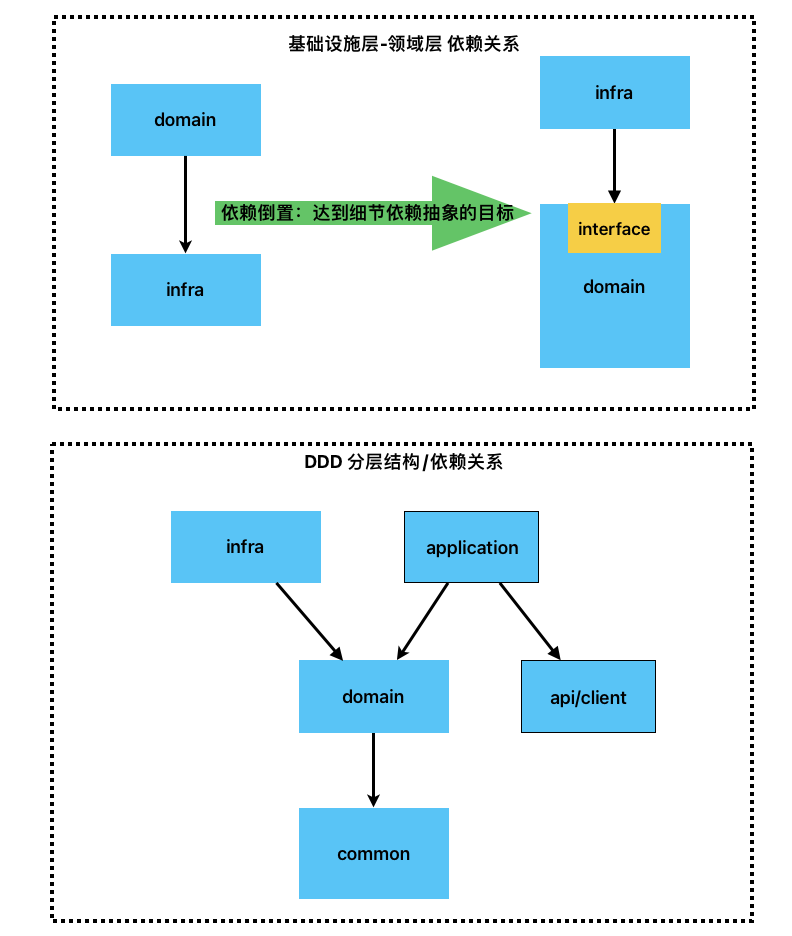
分层架构
DDD中基本分层有:api/client接口层、application应用层、domain领域层、infrastructure基础设施层、common公共通用层等。这里需要需要注意的是:直观上,domain领域层是依赖于infrastructure基础设施层。但我们可以把Repository 仓储的接口定义放到domain领域层中,而在infrastructure基础设施层中通过实现类的方式来实现domain领域层所定义的相关接口。这样我们就调整了domain领域层和infrastructure基础设施层之间的依赖关系。使得infrastructure基础设施层去依赖domain领域层。即所谓的依赖倒置原则。这样我们保证了领域层不会依赖任何具体的技术框架,而是以接口的方式进行隔离
Bounded Context 限界上下文
DDD认为面对大规模的系统,保证全局的概念一致性从根本上是不可能的。这时要把大系统分解成若干子系统,每个子系统对应一个领域模型。然后在每个子系统的内部保证概念的严格一致性,而不同子系统之间则没有必要完全一致。换言之,不再追求全局一致性,而是追求局部一致性。DDD中就把这样的一个子系统称之为Bounded Context限界上下文。之所以称之为Context上下文也很好理解,因为统一语言是针对某个特定Context上下文而言的,一个上下文对应一套统一语言。脱离了Context上下文来谈统一语言是没有意义的;同时,为了强调不同上下文之间的边界,故就将其称之为Bounded Context限界上下文。Bounded Context限界上下文其是对解决方案空间的分解。理想情况下,解决方案空间的分解应该尽量与问题空间保持一致。同时,界限上下文的划分也可以用于指导微服务的划分
在不同限界上下文之间进行映射、集成时,常用的模式、手段:
- 公开发布语言/开放主机服务 模式
- ACL防腐层 模式
- 共享内核 模式
- 客户-供应商 模式
- 追随者 模式
CQRS 命令查询职责分离
CQRS 命令查询职责分离(Command Query Responsibility Segregation),是指将增、删、改的功能称为Command命令,而把查的功能称为Query查询。这两种功能的职责不同,应该采用不同的方式来处理。实现CQRS的原则简单来说就是,命令走领域模型;而查询则不走领域模型,直接用SQL、DTO数据传输对象。该理论的底层逻辑是对于命令的场景而言,如果绕过了领域模型,一方面,无法保证数据的完整性、一致性;另一方面,其也会导致领域逻辑、数据散落在各个地方,不利于后期维护。而对于查询场景而言,由于其不会改变数据,所以即使绕过了领域模型,也不会造成数据的不完整和不一致
这里需要强调下,CQRS中的Q(查询)指的是来自客户端的查询。换言之,只有客户端的操作目的就是查询,才可以认为是CQRS里的Q;如果客户端的操作目的是命令(增、删、改),此时在这个执行命令的过程中所发生的查询操作,一般不认为是CQRS里的Q。因为后者的查询是为了实现命令而进行的,其在查出领域对象需要进一步执行领域逻辑。而不是直接返回给客户端来使用的
实现方式:代码结构分离
最简单的一种实现CQRS的方式是:针对查询的场景,application应用层的service业务服务直接调用仓储接口,仓储里将通过执行SQL(可以是复杂的跨领域对象的连表查询SQL)得到的数据直接回填到DTO数据传输对象中(而不是像命令场景一样将数据回填到领域对象当中)。然后直接将DTO数据传输对象返回给应用层,应用层的service业务服务再进行一定加工后就可以直接返回客户端了。这里,我们也将这些DTO数据传输对象称之为Query Model查询模型
实现方式:数据库结构分离
针对连表查询的场景,为了更好的保证性能问题,直接为查询功能单独创建一套DB表。通过引入冗余字段,使相应的表结构和查询模型吻合,从而减少、避免连表查询。这样就将数据库里的表就分成了两套,Command Model命令模型中的表是根据领域模型来设计的,由命令功能来访问;而Query Model查询模型中的表则是根据查询需求进行设计的,由查询功能来访问
这里需要注意的是,由于我们为查询模型单独建立了相应的数据表。所以在命令对命令模型里的表进行增、删、改操作后,需要把相应的数据、变更同步到查询模型的表当中。可选的数据同步手段有:命令模型相应的仓储方法同时写命令模型和查询模型两边的数据表、异步的消息通知机制、CDC变更数据捕获等
该实现方式的缺陷也很明显:
- 两种数据模型间的数据同步会带来更多的复杂性、出错概率
- 数据同步会增加一定的性能损耗
- 数据存储会占用更多的空间
参考文献
- 实现领域驱动设计 Vaughn Vernon 著
- 微服务架构设计模式 Chris Richardson著
