这里介绍机器学习中用于聚类的DBSCAN算法

基本原理
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法是一种基于密度的无监督学习的聚类算法。其可将数据集根据分布的密度划分为若干个簇。该算法有两个模型参数:
- 邻域半径 ϵ:以样本为中心的搜索半径
- 最小点数 MinPts:如果将某样本视为核心点,则在以该样本为中心、半径为ε的搜索范围内样本数(含该样本自身)的最小阈值
这里先介绍下该算法的核心概念:
- ϵ-邻域:对于某个样本p而言,在以样本p为中心、ε为半径的范围内的子样本集合。显然样本p的ϵ-邻域包含自身,因为距离为0
- 核心点:对于某个样本p而言,在以样本p为中心、ε为半径的范围内包含至少MinPts个样本(含样本p自身)。换言之,如果 样本p的ϵ-邻域中的样本数 >= MinPts,则样本p即为核心点
- 边界点:对于某个样本而言,虽然其不是核心点,但其在某个核心点的ϵ-邻域内
- 噪声点:对于某个样本而言,其既不是核心点,也不在任何核心点的ϵ-邻域内
- 密度直达:样本p是一个核心点,且样本q在样本p的ϵ-邻域内,则称:样本q由样本p密度直达
- 密度可达:对于样本序列p(1),p(2),p(3),…,p(n)而言,若对于任意i(1≤i<n),都有:样本p(i+1)由样本p(i)密度直达。则称:样本p(n)由样本p(1)密度可达。显然这里的p(1),p(2),p(3),…,p(n-1)样本都必须是核心点,而p(n)样本则可以是 边界点 或 核心点
DBSCAN算法的本质就是先找出数据集中的所有核心点,然后将所有密度可达的样本划分为一个簇。具体流程如下:
- 对数据集中的每个样本计算ϵ-邻域。若ϵ-邻域中的样本数满足MinPts最小点数的要求,则该样本标记为核心点。其中,距离的度量方式可根据实际需求选择欧式距离、曼哈顿距离 或 余弦距离等
- 将数据集中的所有样本全部标记为未访问
- 随机挑选一个未访问的核心点T
A. 将该核心点T加入到空集合S中。同时,该核心点T标记为已访问
B. 从集合S中随机取出一个样本。如果该样本为核心点,则将其ϵ-邻域中未访问的样本全部加入到集合S中。相应的,将这些加入到集合S中的样本全部标记已访问
C. 重复步骤B,直到集合S为空。显然,步骤A~步骤C过程中访问的所有样本都可以由样本T密度可达。故,将这些样本全部划分到一个簇当中即可。至此,该簇就确定了 - 重复步骤3,进行下一个簇的划分,直到所有核心点全部被访问后停止
- 将数据集中未被任何簇包含的样本标记为噪声点。噪声点的簇编号通常用-1表示
从上述流程不难看出,如果某个边界点在多个核心点的ϵ-邻域内,则其会被分配到第一个处理该边界点的核心点所在的簇中。换言之,该边界点的归属是由核心点的遍历顺序决定的,而这种顺序的依赖性可能会导致聚类结果的不稳定
实践
基于Python的实现
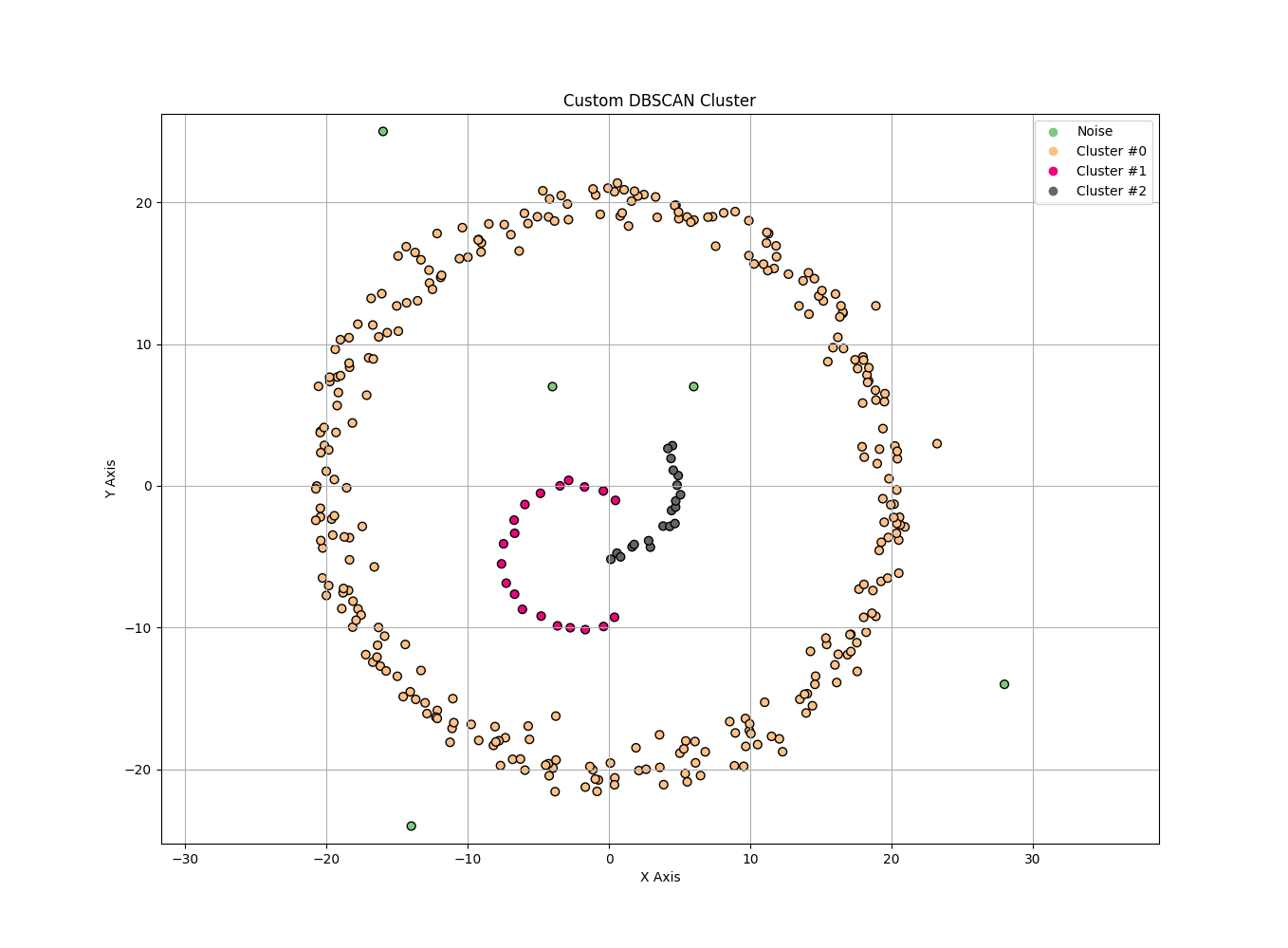
这里基于NumPy提供DBSCAN算法的Python实现,更好的诠释该算法的过程、细节、原理。不过,这里对领域的计算做了一定的优化。并不是一开始就计算所有点的领域,而是按需计算。在一定程度上减少了领域的计算量
1 | import numpy as np |
聚类效果如下所示
基于SKlearn的使用
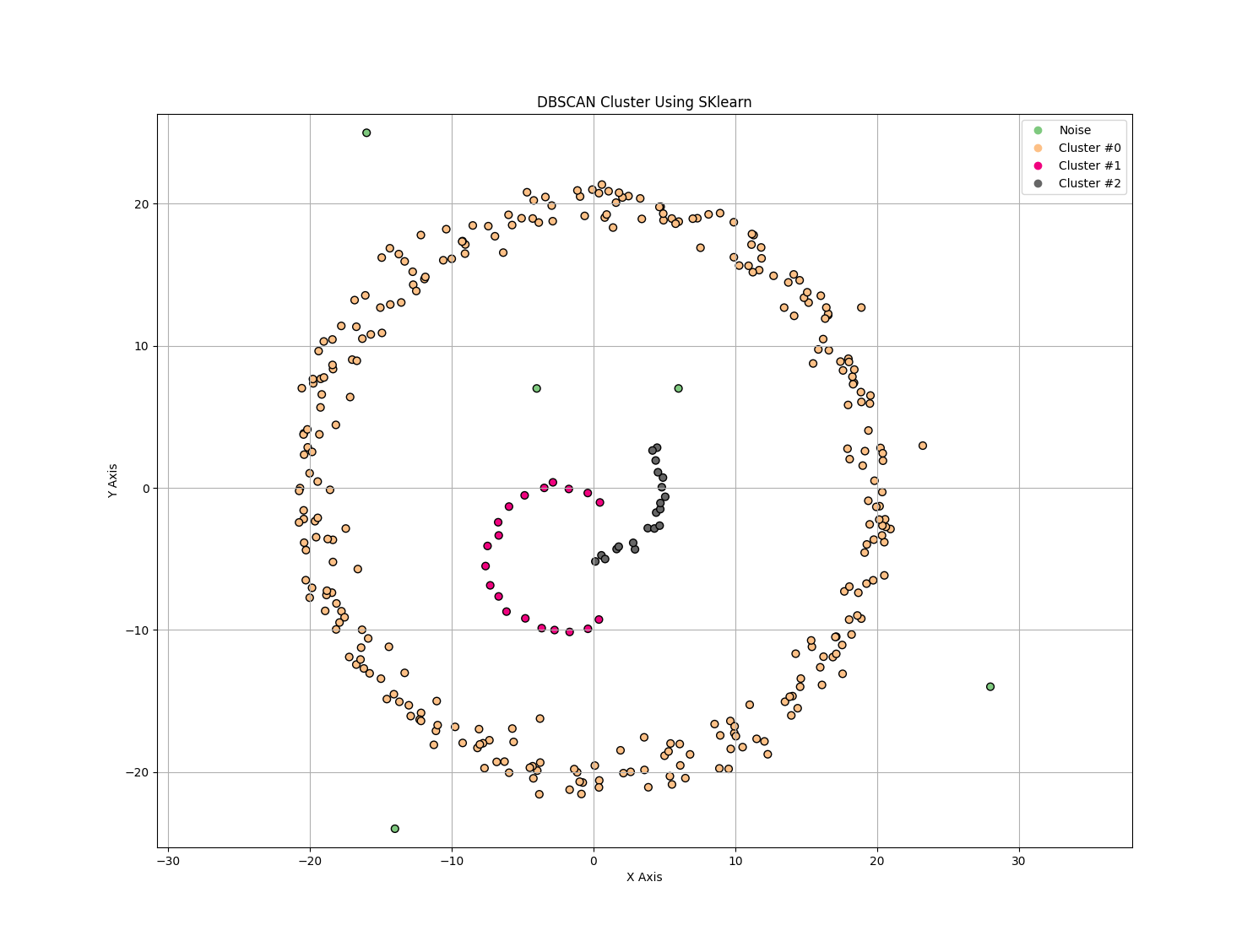
实际开发中可直接使用SKlearn提供的DBSCAN算法实现
1 | import numpy as np |
聚类效果如下所示
特点
优点
- 无监督学习算法,无需训练集
- 该算法基于密度进行聚类,不依赖于簇的形状。故可适用于任意形状、大小的簇
- 与K-Means算法不同,DBSCAN算法不需要事先指定簇的数量
- 对异常值、噪声不敏感,该算法能够自动识别、处理
缺点
- 数据集较大时,该算法的计算量较大
- 模型参数ε、MinPts对最终的聚类结果影响很大,不合适的参数甚至会导致聚类错误
参考文献
- 机器学习 周志华著
- 机器学习公式详解 谢文睿、秦州著
