grep是Linux中常用的文本搜索命令。它用于搜索文件中匹配指定模式的行

命令格式
其可用于搜索文件里符合条件的文本,并匹配的行进行打印输出。该命令的形式如下
1 | grep [options] pattern [file] |
高频用法
正向匹配
1 | # 匹配a.txt文件中包含thr的行 |
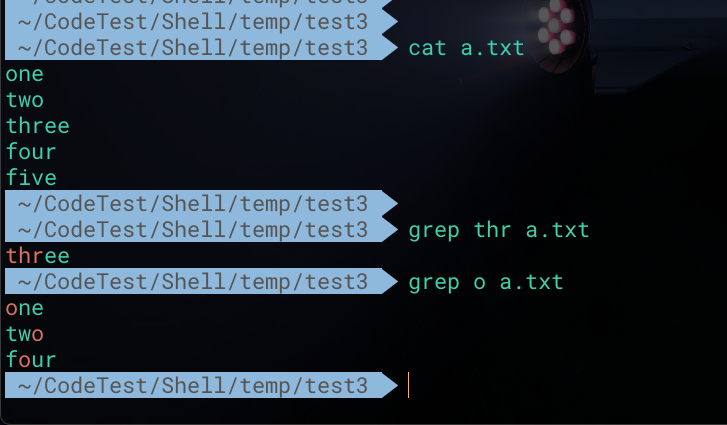
当有多个匹配模式时,使用 -e 选项依次指定。显然各模式之间的逻辑关系是或
1 | # 搜索a.txt文件中包含thr的行 |
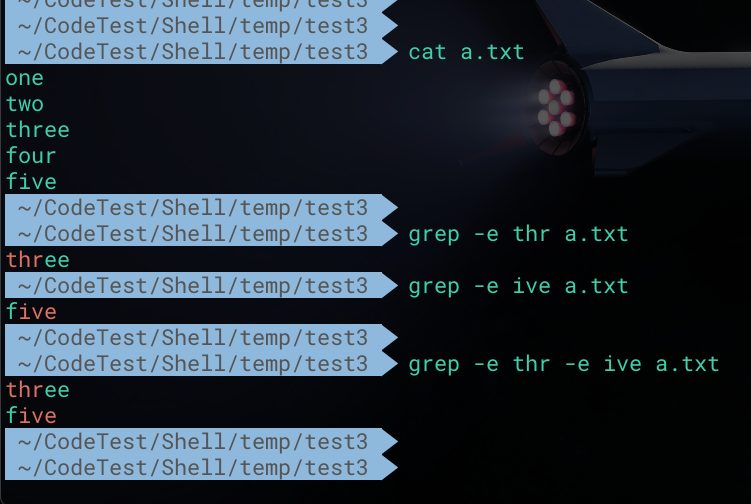
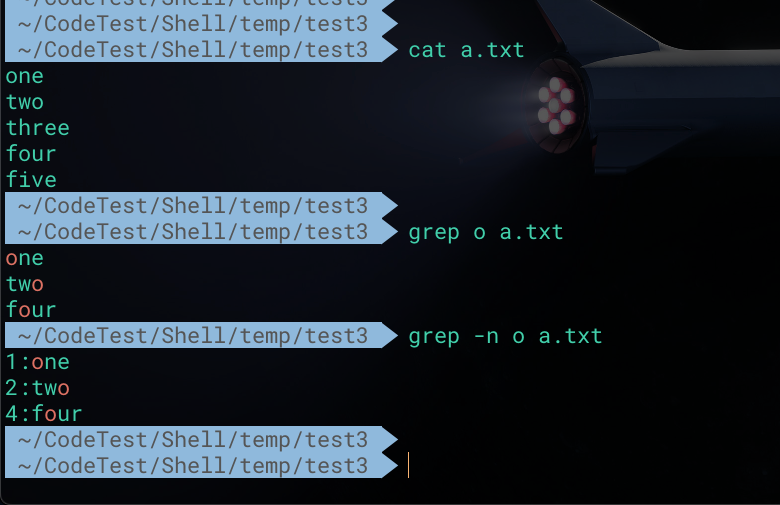
此外,添加 -n 选项后,可以在搜索结果中展示相应的行号
1 | # 搜索a.txt文件中包含o的行,并输出行号 |
反向匹配
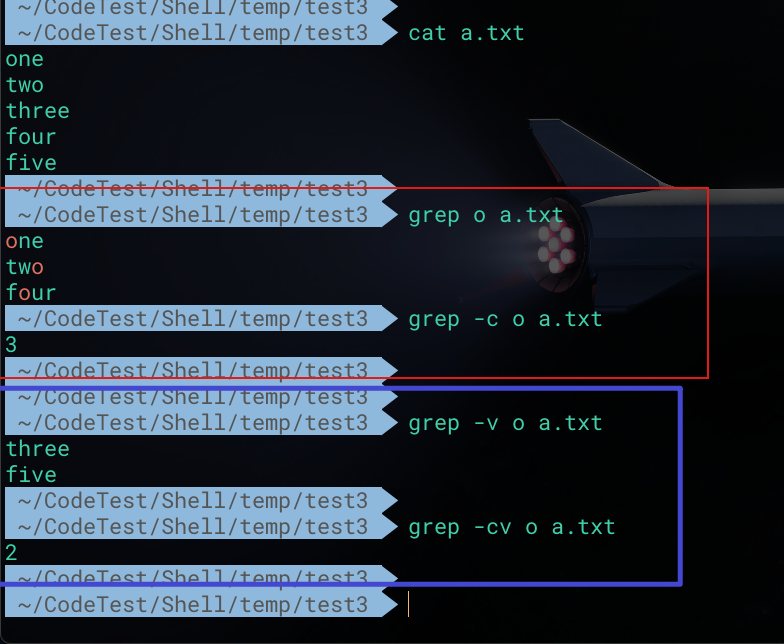
通过 -v 选项即可实现反向匹配。即输出不匹配指定模式的行
1 | # 匹配a.txt文件中不包含thr的行 |
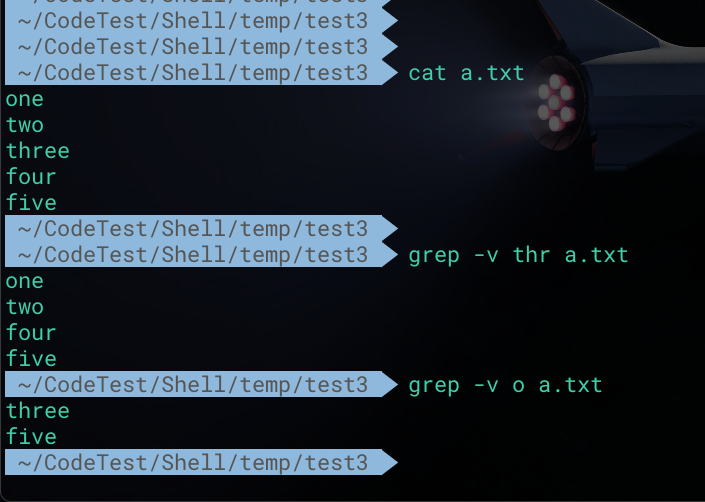
支持正则表达式
grep之所以提供了强大的搜索功能,正是基于正则表达式的原因。可利用 -E 选项指定正则表达式
1 | # 搜索a.txt文件,正则表达式为 o[un] |
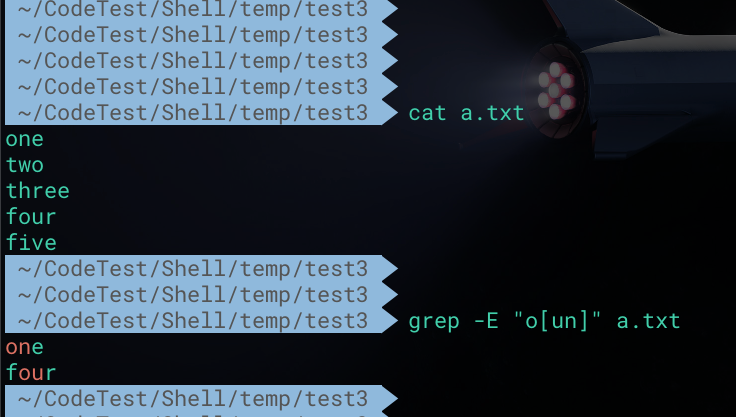
统计搜索结果数目
使用 -c 选项即可统计搜索结果的数目
1 | # 统计 grep o a.txt 命令搜索结果的数目信息 |
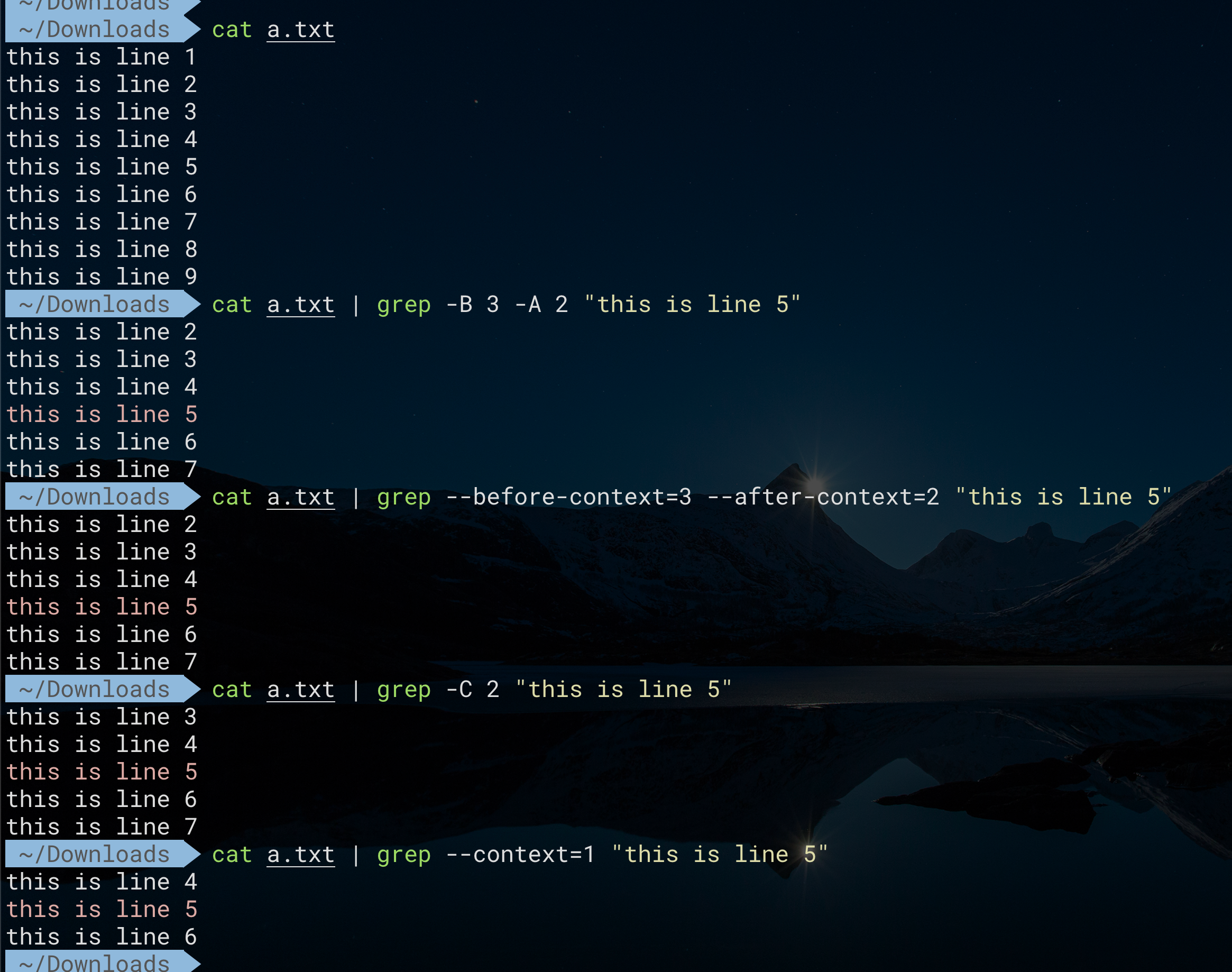
查看匹配行的上下文
常用于查看日志中多行的堆栈信息
1 | # 查看匹配行及相应的后面num行 |
处理二进制文件
通常grep命令不会将日志文件视作二进制文件。但当日志文件中包含特殊字符数据时,grep可能会判定错误,将其视作为二进制文件。在这种情况下,可以使用 -a选项。这样即使文件包含二进制数据,grep 也会尝试以文本方式处理它们,而不是将它们视为二进制文件。以便搜索、匹配
参考文献
- Linux命令行与shell脚本编程大全·第4版 Richard Blum、Christine Bresnahan著
