Java 8开始支持Stream流,Stream不同于IO流,它是对数据集合的一种高级抽象,配合Lambda通过函数式编程可以高效方便地对集合元素进行操作。这里通过具体的实例来讲解如何使用Java Stream

简介
一般地,可通过集合、数组来创建Stream数据流,数据元素在Stream的管道中单向流动。数据在流动的过程中通常会进行若干个诸如过滤、排序、映射之类的 Intermediate(中间)操作,并最终通过一个 Terminal(最终)操作来结束关闭这个数据流。通过Stream流对集合进行操作,较之传统的通过迭代器来遍历的方式可以大大地简化代码,十分优雅简洁
创建流
创建流的方式很简单,可通过如下几种方式来获取数组、集合的数据流。特别地,对于集合来说,其还可创建并行流,来提供流的操作速度
1
2
3
4
5
6
7
8
|
Arrays.stream(T[] array);
Stream.of(T... values);
stream();
parallelStream();
|
这里我们来演示下串行流Stream和并行流parallelStream的区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| public class StreamDemo {
public static void testParallelStream() {
List<GoodPerson> list = getList();
System.out.println("串行流 Demo");
List<GoodPerson> list1 = list.stream()
.peek(e ->{
System.out.println("Thread: " + Thread.currentThread() + "--- Before Filter: " + e);
} )
.filter(e -> e.getAge()>18)
.peek(e -> System.out.println("Thread: " + Thread.currentThread() + "After Filter: " + e))
.collect(Collectors.toList());
System.out.println("\nlist1: ");
list1.forEach(System.out::println);
System.out.println("\n并行流 Demo");
List<GoodPerson> list2 = list.parallelStream()
.peek(e ->{
System.out.println("Thread: " + Thread.currentThread() + "--- Before Filter: " + e);
} )
.filter(e -> e.getAge()>18)
.peek(e -> System.out.println("Thread: " + Thread.currentThread() + "After Filter: " + e))
.collect(Collectors.toList());
System.out.println("\nlist2: ");
list2.forEach(System.out::println);
}
private static List<GoodPerson> getList() {
List<GoodPerson> list = new LinkedList<>();
GoodPerson gp1 = new GoodPerson("Bob", 32, DateUtil.parse("2020-04-14"));
GoodPerson gp2 = new GoodPerson("Tony", 12, DateUtil.parse("2020-03-14"));
GoodPerson gp3 = new GoodPerson("Aaron", 52, DateUtil.parse("2020-03-24"));
GoodPerson gp4 = new GoodPerson("Kevin", 30, DateUtil.parse("2019-01-03"));
list.add(gp1);
list.add(gp2);
list.add(gp3);
list.add(gp4);
return list;
}
}
...
@Data
@AllArgsConstructor
@NoArgsConstructor
public class GoodPerson {
private String name;
private Integer age;
private Date birthday;
public GoodPerson(String name) {
this.name = name;
}
public GoodPerson(String name, Integer age) {
this.name = name;
this.age = age;
}
}
|
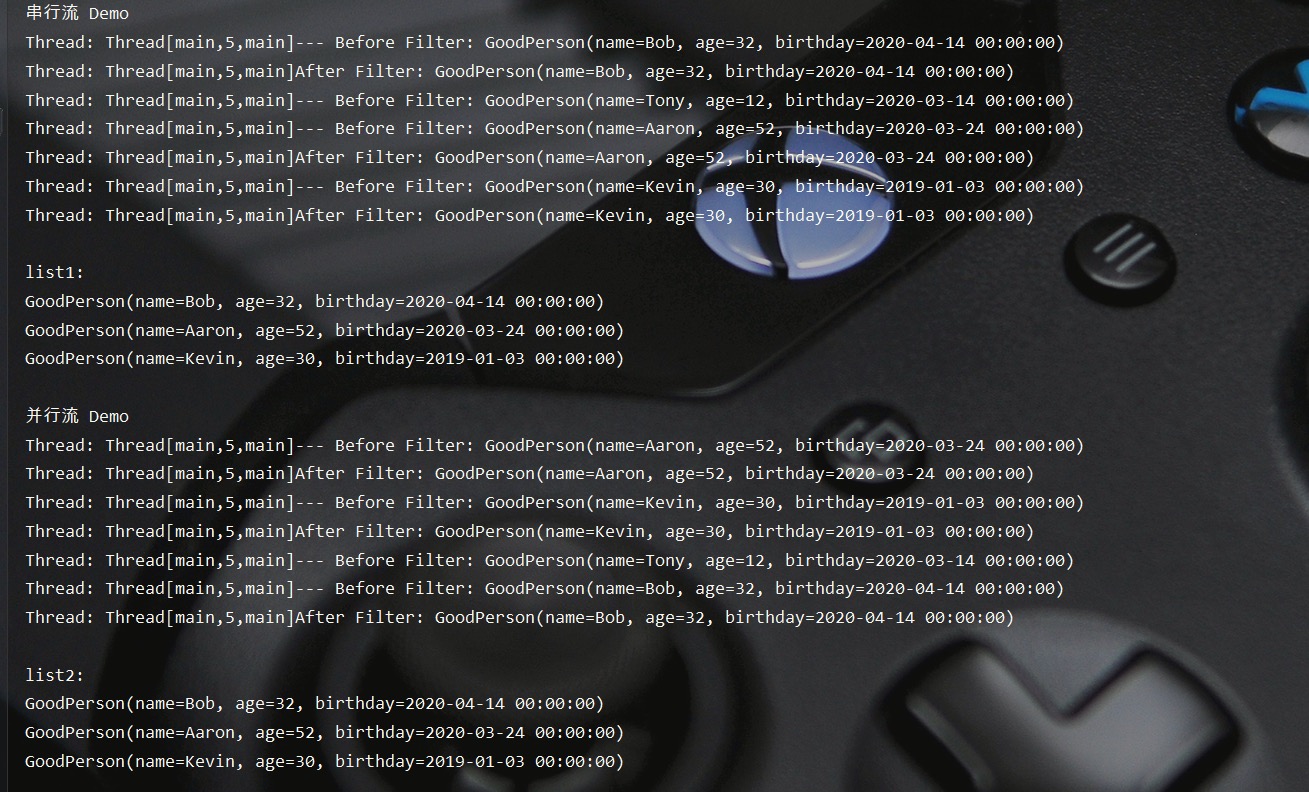
测试结果如下所示,可以看到串行流是在一个线程中进行操作的,而并行流则是通过多个线程并行处理
获取到数据流后,最重要的就是根据实际需要来对数据流中的数据进行一些处理。为此Java 8提供很多Intermediate(中间)方法以供我们使用,这里将对日常开发中高频使用的一些方法的使用进行介绍。值得一提的是,由于Intermediate方法的返回结果亦是一个Stream流,故在一个数据流中可通过链式调用的方式来调用若干个Intermediate方法
filter
该方法用于过滤掉我们不需要元素,当其中的lambda返回false则过滤掉该元素。这里我们过滤掉年龄不大于18的数据元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public class StreamDemo {
public static void testFilter() {
GoodPerson[] array = getArray();
Set<GoodPerson> set = Arrays.stream(array)
.filter( goodPerson -> {
if(goodPerson.getAge()>18) {
return true;
}
return false;
} )
.collect(Collectors.toSet());
set.forEach( System.out::println );
}
private static GoodPerson[] getArray() {
GoodPerson[] array = new GoodPerson[4];
GoodPerson gp1 = new GoodPerson("Bob", 32, DateUtil.parse("2020-04-14"));
GoodPerson gp2 = new GoodPerson("Tony", 12, DateUtil.parse("2020-03-14"));
GoodPerson gp3 = new GoodPerson("Aaron", 52, DateUtil.parse("2020-03-24"));
GoodPerson gp4 = new GoodPerson("Kevin", 30, DateUtil.parse("2019-01-03"));
array[0] = gp1;
array[1] = gp2;
array[2] = gp3;
array[3] = gp4;
return array;
}
}
|
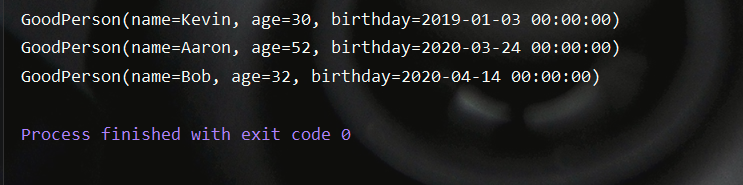
测试结果如下所示:
map
该方法可将流中的元素X映射为Y,实例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public class StreamDemo {
public static void testMap() {
GoodPerson[] array = getArray();
System.out.println("----------- demo1 -----------");
List<Integer> list1 = Stream.of(array)
.map(GoodPerson::getAge)
.collect(Collectors.toList());
list1.forEach(System.out::println);
System.out.println("----------- demo2 -----------");
List<GoodPerson> list2 = Stream.of(array)
.map(goodPerson -> {
goodPerson.setName( goodPerson.getName().toUpperCase() );
int oldAge = goodPerson.getAge();
goodPerson.setAge( oldAge*2 );
return goodPerson;
})
.collect(Collectors.toList());
list2.forEach(System.out::println);
}
}
|
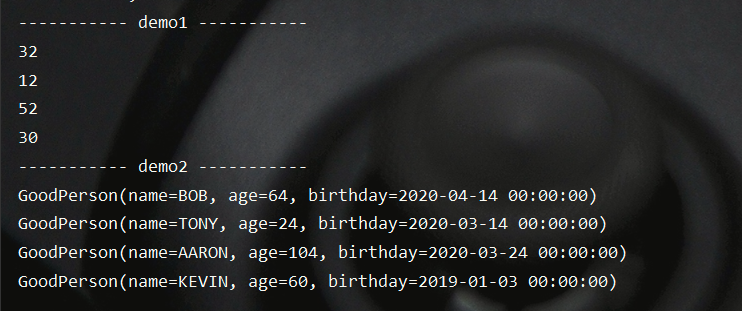
测试结果如下所示:
flatMap
如果数据流中的元素是集合、数组等类型,可通过该方法将数据流中的集合、数组等类型数据分别转换为一个个的数据流,然后再将这些流扁平化为一个流。实例如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class StreamDemo {
public static void testFlatMap() {
GoodPerson[] array1 = getArray();
GoodPerson[] array2 = getArray();
List<GoodPerson[]> list = Arrays.asList(array1, array2);
List<GoodPerson> list2 = list.stream()
.flatMap(array -> Stream.of(array))
.collect(Collectors.toList());
list2.forEach( System.out::println );
}
}
|
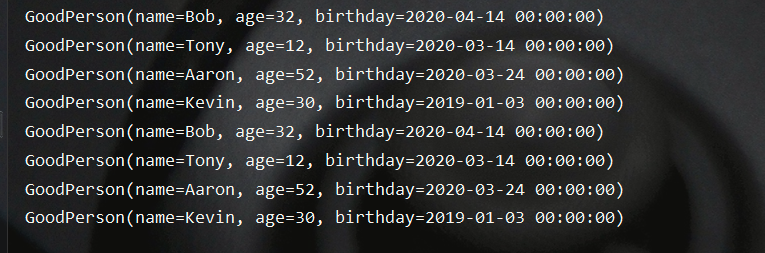
测试结果如下所示:
sorted
该方法签名如下,其通过接收一个比较器来实现对流中的元素进行升序排序
1
| Stream<T> sorted(Comparator<? super T> comparator);
|
相信大家对于利用lambda来创建一个比较器的方式已经很熟悉了,这里着重介绍下如何Comparator接口的静态方法comparing来创建比较器。其JDK实现如下,可以看到其创建一个指定排序键的比较器。由于该比较器默认是升序的,故若需要降序的比较器,可通过Comparator接口的默认方法reversed来实现
1
2
3
4
5
6
7
8
9
10
11
12
| public static <T, U extends Comparable<? super U>> Comparator<T> comparing(Function<? super T, ? extends U> keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));
}
...
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
|
实例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public class StreamDemo {
public static void testSort() {
List<GoodPerson> list = getList();
System.out.println("----------- demo1 -----------");
List<GoodPerson> list2 = list.stream()
.sorted( (o1, o2) -> o1.getAge().compareTo(o2.getAge()) )
.collect(Collectors.toList());
list2.forEach(System.out::println);
System.out.println("----------- demo2 -----------");
List<GoodPerson> list3 = list.stream()
.sorted( Comparator.comparing(GoodPerson::getName) )
.collect(Collectors.toList());
list3.forEach(System.out::println);
System.out.println("----------- demo3 -----------");
List<GoodPerson> list4 = list.stream()
.sorted( Comparator.comparing(GoodPerson::getAge).reversed() )
.collect(Collectors.toList());
list4.forEach(System.out::println);
}
}
|
测试结果如下所示:
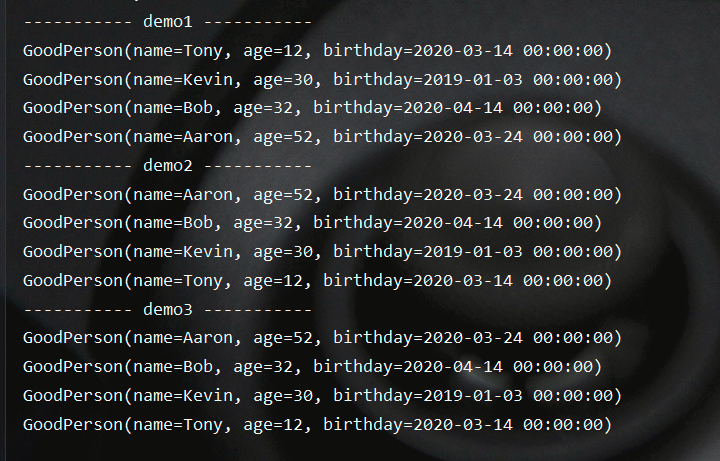
limit
该方法用于取数据流中的前n个元素,实例如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| public class StreamDemo {
public static void testLimit() {
List<GoodPerson> list = getList();
System.out.println("----------- demo1 -----------");
List<GoodPerson> list1 = list.stream()
.limit(2)
.collect(Collectors.toList());
list1.forEach(System.out::println);
System.out.println("----------- demo2 -----------");
List<GoodPerson> list2 = list.stream()
.limit(10)
.collect(Collectors.toList());
list2.forEach(System.out::println);
System.out.println("----------- demo3 -----------");
List<GoodPerson> list3 = list.stream()
.limit(0)
.collect(Collectors.toList());
list3.forEach(System.out::println);
}
}
|
测试结果如下所示:
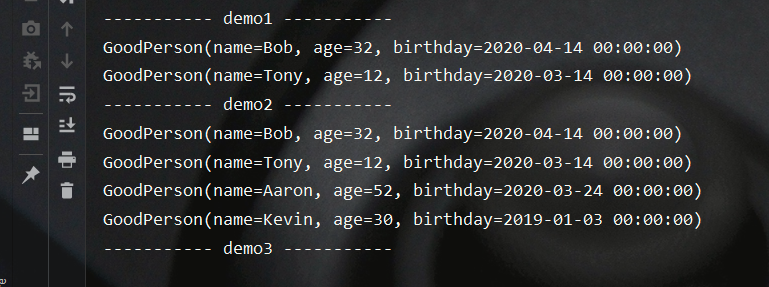
skip
该方法用于跳过数据流中的前n个元素,实例如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| public class StreamDemo {
public static void testSkip() {
List<GoodPerson> list = getList();
System.out.println("----------- demo1 -----------");
List<GoodPerson> list1 = list.stream()
.skip(2)
.collect(Collectors.toList());
list1.forEach(System.out::println);
System.out.println("----------- demo2 -----------");
List<GoodPerson> list2 = list.stream()
.skip(10)
.collect(Collectors.toList());
list2.forEach(System.out::println);
System.out.println("----------- demo3 -----------");
List<GoodPerson> list3 = list.stream()
.skip(0)
.collect(Collectors.toList());
list3.forEach(System.out::println);
}
}
|
测试结果如下所示:
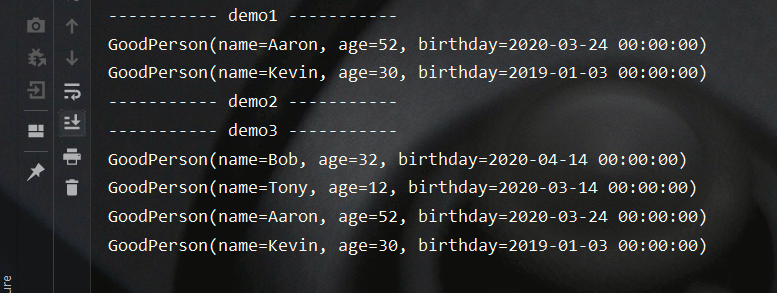
distinct
该方法用于对数据流中的重复元素进行去重,实例如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class StreamDemo {
public static void testDistinct() {
List<GoodPerson> list = new LinkedList<>(getList());
list.addAll(getList());
System.out.println("----------- 去重前 -----------");
list.forEach(System.out::println);
List<GoodPerson> list1 = list.stream()
.distinct()
.collect(Collectors.toList());
System.out.println("----------- 去重后 -----------");
list1.forEach(System.out::println);
}
}
|
测试结果如下所示:
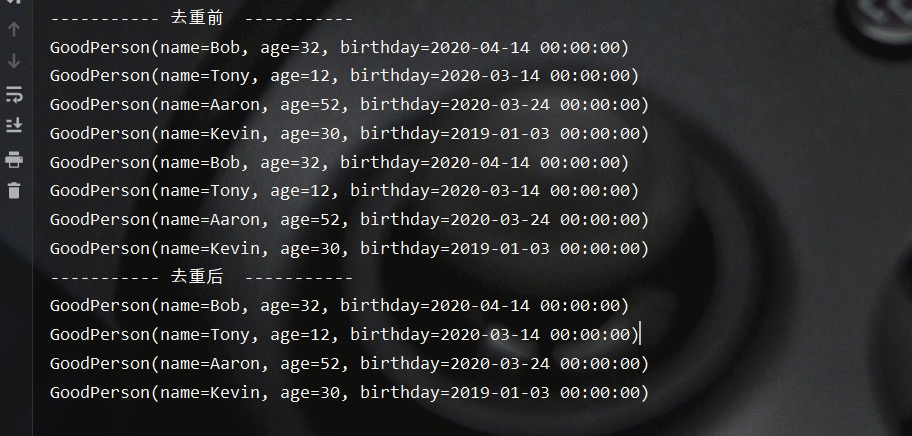
peek
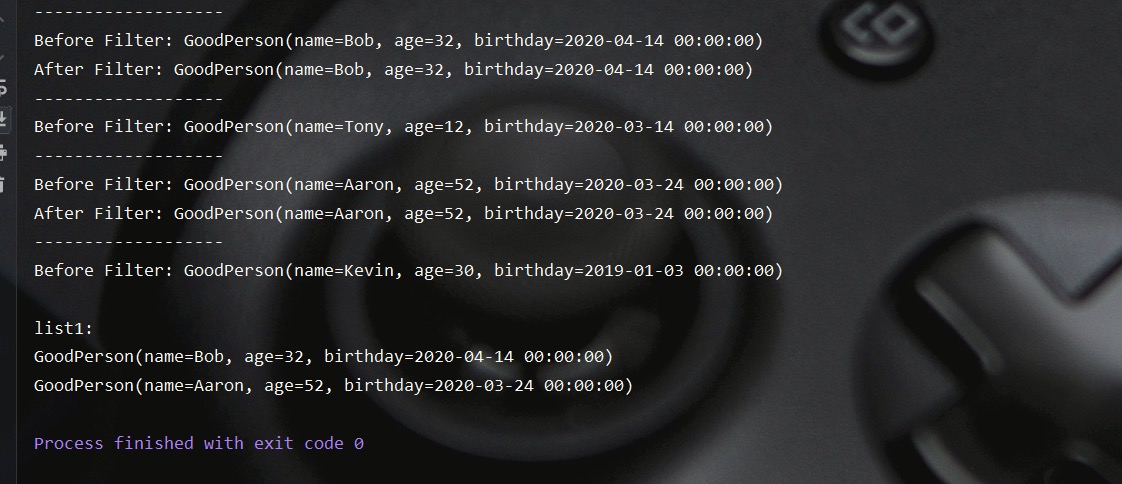
现在大家可能已经看到Stream大大方便了对集合元素的操作处理,但是你会发现一个新的问题没办法观察流中的数据的流动情况,而窥视方法peek则可以通过打印当前流元素的信息来帮助我们了解数据的流动情况。示例代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class StreamDemo {
public static void testPeek() {
List<GoodPerson> list = getList();
List<GoodPerson> list1 = list.stream()
.peek(e ->{
System.out.println("-------------------");
System.out.println("Before Filter: " + e);
} )
.filter(e -> e.getAge()>30)
.peek(e -> System.out.println("After Filter: " + e))
.collect(Collectors.toList());
System.out.println("\nlist1: ");
list1.forEach(System.out::println);
}
}
|
测试结果如下所示,通过输出信息,我们还可以发现Stream对于元素的处理是将元素一个一个的垂直流动,而非我们以为的将全部元素先执行操作一再执行操作二这样的水平流动
Terminal(最终)操作
当数据流经过若干个Intermediate中间操作后,还需要通过一个Terminal(最终)操作来关闭这个流。故在一个Stream,有且只有一个Terminal操作
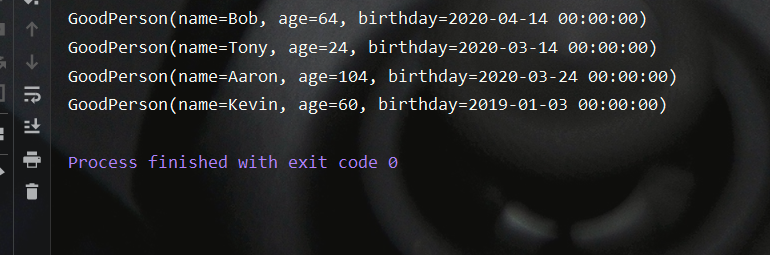
forEach
该方法遍历流中的元素,并同时关闭这个流
1
2
3
4
5
6
7
8
9
10
11
12
| public class StreamDemo {
public static void testForEach() {
List<GoodPerson> list1 = getList();
list1.stream()
.forEach( e -> {
Integer oldAge = e.getAge();
e.setAge(oldAge*2);
System.out.println(e);
});
}
}
|
测试结果如下:
toArray
该方法可以将流中的元素转为数组,示例如下:
1
2
3
4
5
6
7
8
9
10
| public class StreamDemo {
public static void testToArray() {
List<GoodPerson> list = getList();
GoodPerson[] array = list.stream()
.filter(e -> e.getAge()>18)
.toArray(GoodPerson[]::new);
System.out.println("array: " + Arrays.toString(array));
}
}
|
测试结果如下:

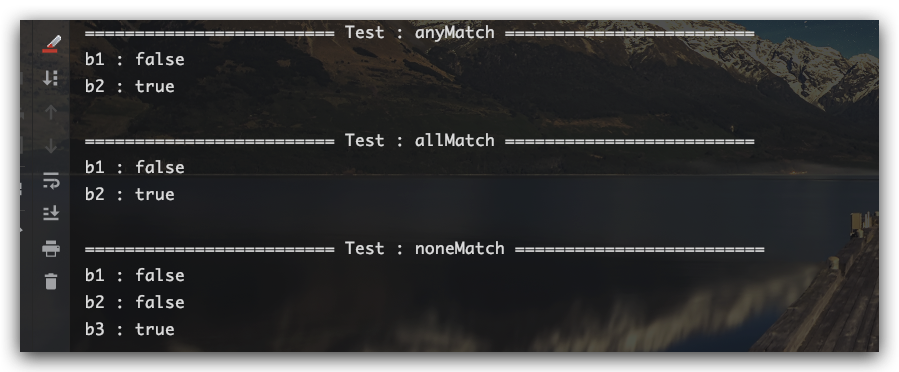
匹配
匹配操作具体包括anyMatch存在任一匹配、allMatch全部匹配、noneMatch没有匹配。示例如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| public static void testMatch() {
List<GoodPerson> goodPersonList = new LinkedList<>();
goodPersonList.add( new GoodPerson("Bob", 32, DateUtil.parse("2020-04-14")) );
goodPersonList.add( new GoodPerson("Tony", 12, DateUtil.parse("2020-03-14")) );
goodPersonList.add( new GoodPerson("Aaron", 52, DateUtil.parse("2020-03-24")) );
goodPersonList.add( new GoodPerson("Kevin", 30, DateUtil.parse("2019-01-03")) );
System.out.println("========================= Test : anyMatch =========================");
boolean b1 = goodPersonList.stream()
.anyMatch( goodPerson -> goodPerson.getAge()>9999 );
boolean b2 = goodPersonList.stream()
.anyMatch( goodPerson -> goodPerson.getAge()>20 );
System.out.println("b1 : " + b1 );
System.out.println("b2 : " + b2 );
System.out.println("\n========================= Test : allMatch =========================");
b1 = goodPersonList.stream()
.allMatch( goodPerson -> goodPerson.getAge()>20 );
b2 = goodPersonList.stream()
.allMatch( goodPerson -> goodPerson.getAge()>2 );
System.out.println("b1 : " + b1 );
System.out.println("b2 : " + b2 );
System.out.println("\n========================= Test : noneMatch =========================");
b1 = goodPersonList.stream()
.noneMatch( goodPerson -> goodPerson.getAge()>20 );
b2 = goodPersonList.stream()
.noneMatch( goodPerson -> goodPerson.getAge()>2 );
boolean b3 = goodPersonList.stream()
.noneMatch( goodPerson -> goodPerson.getAge()>2222 );
System.out.println("b1 : " + b1 );
System.out.println("b2 : " + b2 );
System.out.println("b3 : " + b3 );
}
|
测试结果如下:
collect
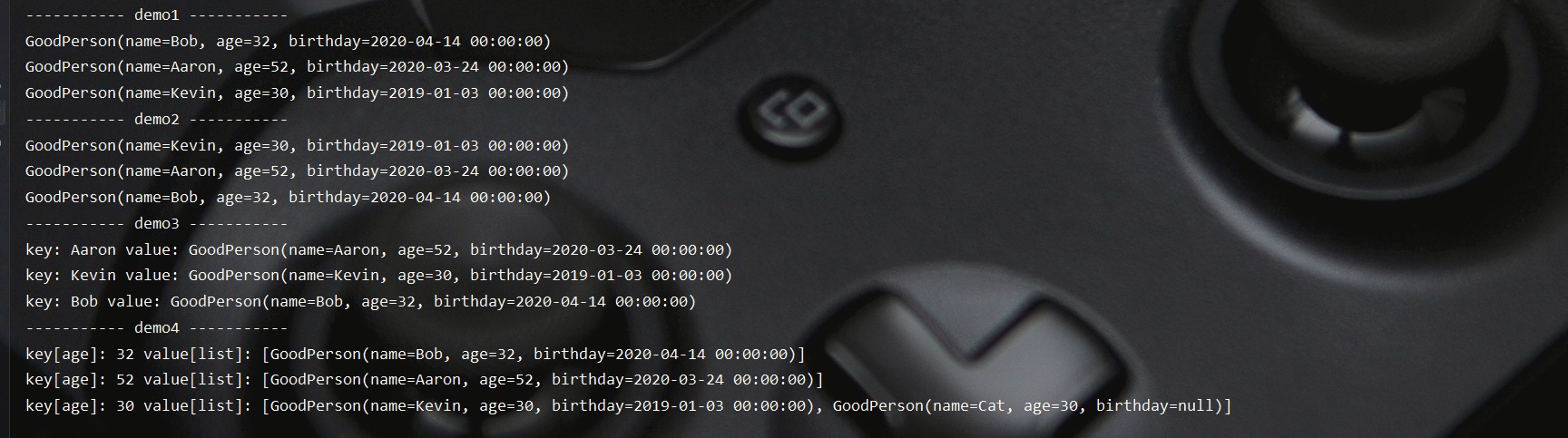
该方法将接收一个收集器来收集流中的元素数据,毕竟我们将集合转为流处理之后通常还是期望将处理后的元素再转回为集合,以供我们后续使用。故Java直接在Collectors类内置了很多收集器,例如上文代码中大量出现的Collectors.toSet()、Collectors.toList(),相信大家也能猜出来这些收集器的作用了,其就是把流里的数据转到Set、List集合中去。类似地,Collectors.toMap() 收集器(Function.identity() 可用于表示元素本身 )可用于将流转为Map,Collectors.groupingBy()可将流中元素按指定键进行分组,并将该键作为所生成Map的key。示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| public class StreamDemo {
public static void testCollect() {
List<GoodPerson> list = getList();
System.out.println("----------- demo1 -----------");
List<GoodPerson> list1 = list.stream()
.filter(e -> e.getAge()>18)
.collect(Collectors.toList());
list1.forEach(System.out::println);
System.out.println("----------- demo2 -----------");
Set<GoodPerson> set1 = list.stream()
.filter(e -> e.getAge()>18)
.collect(Collectors.toSet());
set1.forEach(System.out::println);
System.out.println("----------- demo3 -----------");
Map<String, GoodPerson> map = list.stream()
.filter(e -> e.getAge()>18)
.collect( Collectors.toMap(GoodPerson::getName, Function.identity()) );
map.forEach((age, value) ->{
System.out.println("key: " + age + " value: " + value);
} );
System.out.println("----------- demo4 -----------");
list.add( new GoodPerson("Cat", 30) );
Map<Integer, List<GoodPerson>> mapByAge = list.stream()
.filter(e -> e.getAge()>18)
.collect( Collectors.groupingBy(GoodPerson::getAge) );
mapByAge.forEach((age, value) ->{
System.out.println("key[age]: " + age + " value[list]: " + value);
} );
}
}
|
测试结果如下所示:
前面提到Collectors.toList()、Collectors.toSet()等,其使用的都是特定实现类型的集合,如果期望指定集合的具体类型,则可以通过Collectors.toCollection()方法,只需传入相应的构造器即可
1
2
3
|
List<String> list = set.stream()
.collect( Collectors.toCollection(LinkedList::new) );
|
这里补充说明下在使用Collectors.toMap时,如果姿势不当则有可能导致异常出现。例如下面的示例代码,会因为Map中出现重复的Key而导致异常发生
1
2
3
4
5
6
7
8
9
10
11
12
13
| public static void main(String[] args) {
List<GoodPerson> goodPersonList = new LinkedList<>();
goodPersonList.add( new GoodPerson("Aaron", 24) );
goodPersonList.add( new GoodPerson("Bob", 18) );
goodPersonList.add( new GoodPerson("Aaron", 34) );
goodPersonList.add( new GoodPerson("Bob", 28) );
goodPersonList.add( new GoodPerson("Aaron", 44) );
Map<String, Integer> map = goodPersonList.stream()
.collect( Collectors.toMap( GoodPerson::getName, GoodPerson::getAge) );
System.out.println( map );
}
|
测试结果如下所示
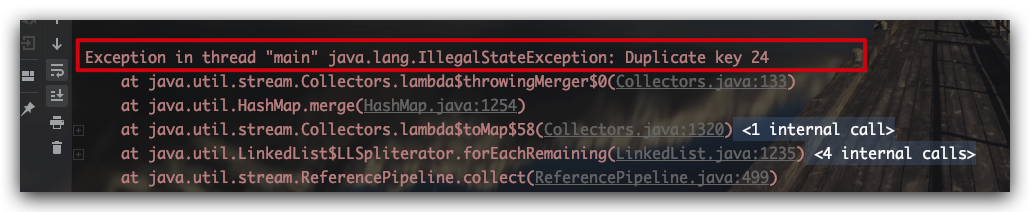
针对此种情况,我们可以在Collectors.toMap方法中指明,当出现两个重复Key时是选择使用旧的Value值还是新的Value值,示例代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public static void main(String[] args) {
List<GoodPerson> goodPersonList = new LinkedList<>();
goodPersonList.add( new GoodPerson("Aaron", 24) );
goodPersonList.add( new GoodPerson("Bob", 18) );
goodPersonList.add( new GoodPerson("Aaron", 34) );
goodPersonList.add( new GoodPerson("Bob", 28) );
goodPersonList.add( new GoodPerson("Aaron", 44) );
Map<String, Integer> map1 = goodPersonList.stream()
.collect( Collectors.toMap( GoodPerson::getName, GoodPerson::getAge, (oldValue, newValue)->oldValue ) );
Map<String, Integer> map2 = goodPersonList.stream()
.collect( Collectors.toMap( GoodPerson::getName, GoodPerson::getAge, (oldValue, newValue)->newValue ) );
System.out.println("map1 : " + map1 );
System.out.println("map2 : " + map2 );
}
|
测试结果如下所示:
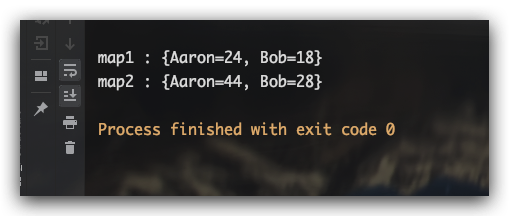
常用地,还可以通过分区收集器Collectors.partitioningBy()将元素划分为两类。示例如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public static void main(String[] args) {
List<GoodPerson> list = new LinkedList<>();
list.add( new GoodPerson("Aaron", 42) );
list.add( new GoodPerson("Bob", 18) );
list.add( new GoodPerson("Tony", 99) );
list.add( new GoodPerson("David", 25) );
Map<Boolean, List<GoodPerson>> map = list.stream()
.collect( Collectors.partitioningBy( person -> person.getAge()>35 ) );
map.forEach( (k,v) -> {
System.out.println("<key>: " + k + " <value>: " + v);
});
}
|
测试结果如下所示:
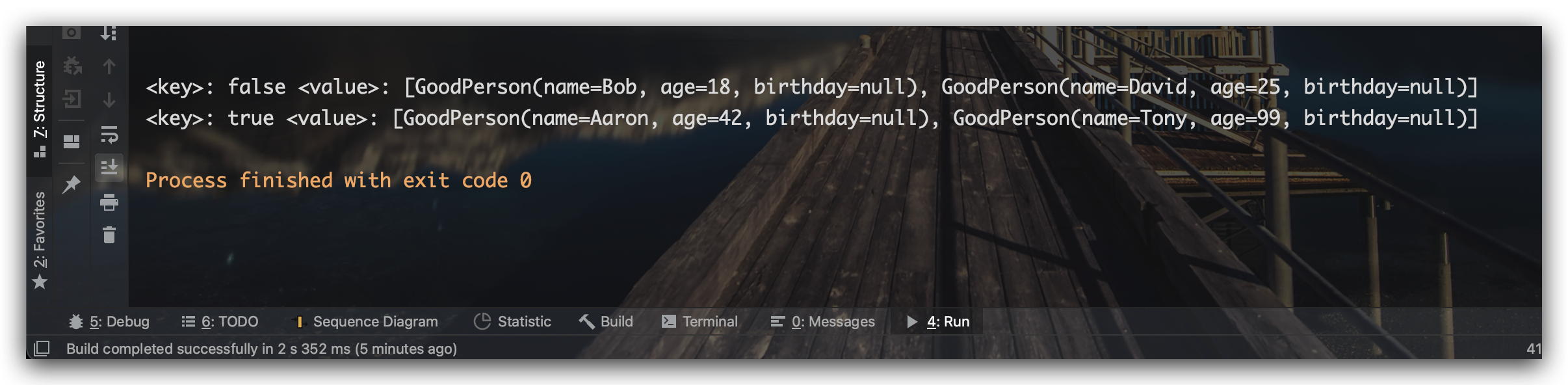
这里再将介绍一种通过 Collectors.joining() 收集器来优雅地实现字符串拼接,该收集器可以指定拼接的分隔符及拼接后的前后缀,示例如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| public class StreamDemo {
public static void testCollect2() {
List<GoodPerson> list = getList();
System.out.println("----------- demo1 -----------");
String result1 = list.stream()
.map(GoodPerson::getName)
.collect( Collectors.joining() );
System.out.println("result1: " + result1);
System.out.println("----------- demo2 -----------");
String result2 = list.stream()
.map(GoodPerson::getName)
.collect( Collectors.joining("~") );
System.out.println("result2: " + result2);
System.out.println("----------- demo3 -----------");
String result3 = list.stream()
.map(GoodPerson::getName)
.collect( Collectors.joining("~","<",">") );
System.out.println("result3: " + result3);
}
}
|
测试结果如下所示:
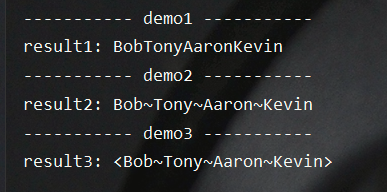
有时候我们还期望对收集的结果再进行一次操作,这时候就可以Collectors.collectingAndThen来进行实现。其接受两个参数,分别用于定义如何收集操作、对收集结果如何映射。其方法签名如下所示
1
| public static<T,A,R,RR> Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream, Function<R,RR> finisher);
|
下面即是一个该方法的实例,我们期望通过Collectors.joining进行收集,并将收集结果全部转为大写
1
2
3
4
5
6
7
8
9
10
11
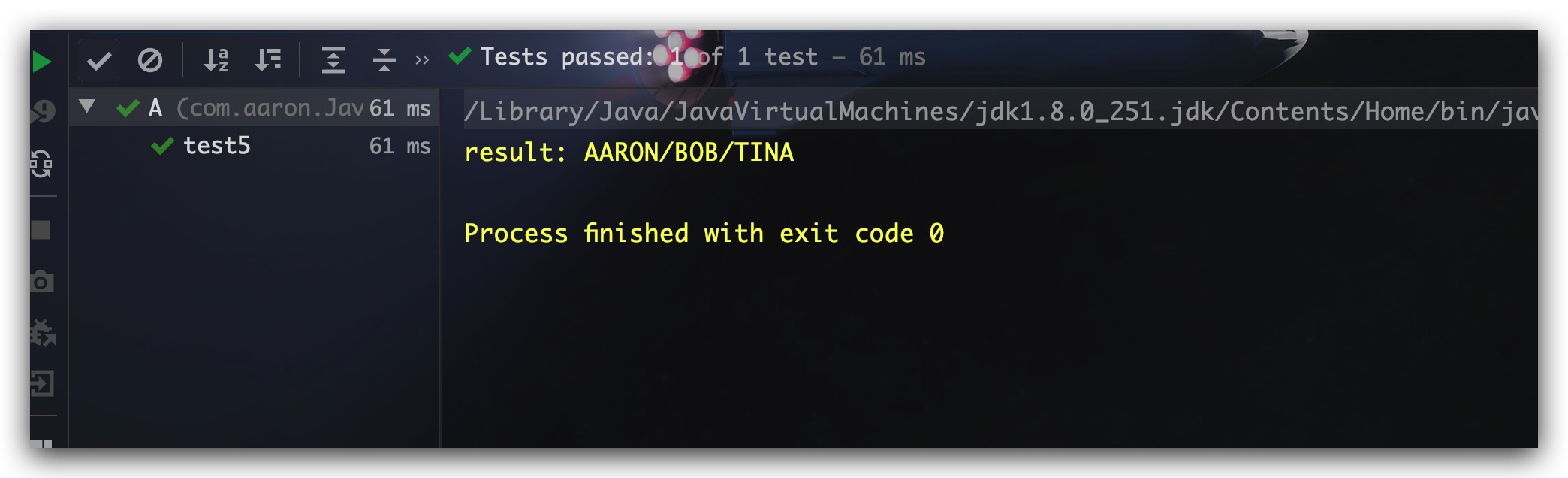
| @Test
public void test5() {
List<String> names = Arrays.asList("Aaron","Bob","Tina");
String result = names.stream()
.collect(
Collectors.collectingAndThen( Collectors.joining("/"), String::toUpperCase )
);
System.out.println("result: " + result);
}
|
测试结果如下,符合预期
下游收集器
我们知道分组Collectors.groupingBy会生成一个Map,其每个值是含有若干个元素的结果列表。但有时候我们期望能够对结果列表再进行处理,比如统计列表大小等操作。容易想到的一个方案是先使用Collectors.groupingBy进行分组,然后再对Map进行遍历处理各个value。事实上,通过下游收集器我们可以一次性完成上述两个操作。分组收集器有一个重载的形式,方法签名如下所示。可以看到我们只需传入第二参数——下游收集器,即可实现对结果列表进行处理
1
2
3
| public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream);
|
示例代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
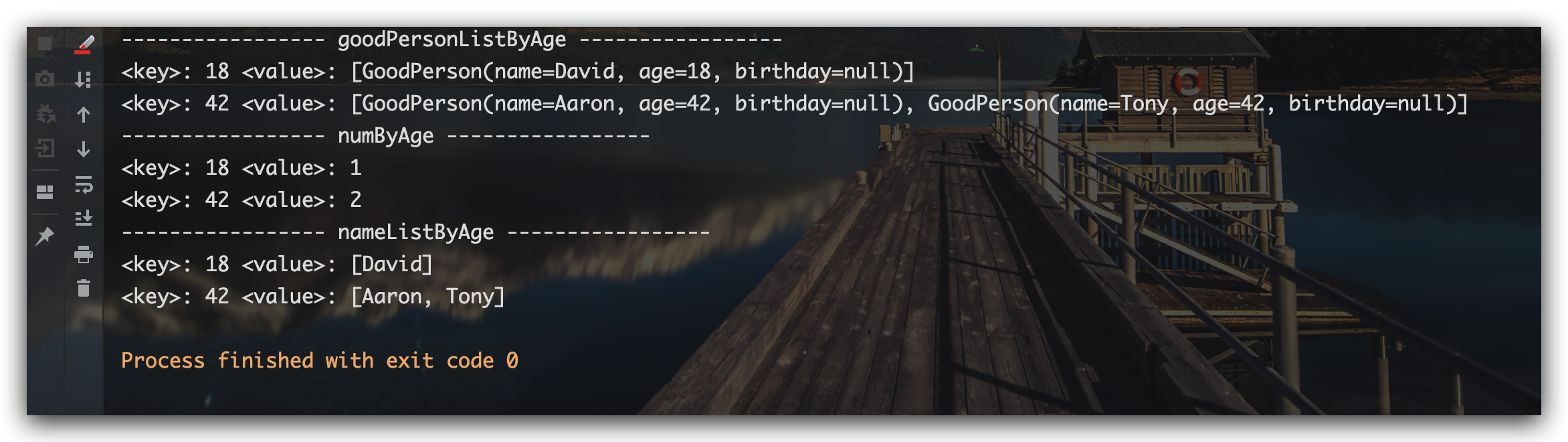
| public static void main(String[] args) {
List<GoodPerson> list = new LinkedList<>();
list.add( new GoodPerson("Aaron", 42) );
list.add( new GoodPerson("Tony", 42) );
list.add( new GoodPerson("David", 18) );
Map<Integer, List<GoodPerson>> goodPersonListByAge = list.stream()
.collect( Collectors.groupingBy( GoodPerson::getAge ) );
System.out.println("----------------- goodPersonListByAge -----------------");
goodPersonListByAge.forEach( (k,v) -> {
System.out.println("<key>: " + k + " <value>: " + v);
});
Map<Integer, Long> numByAge = list.stream()
.collect( Collectors.groupingBy( GoodPerson::getAge, Collectors.counting() ) );
System.out.println("----------------- numByAge -----------------");
numByAge.forEach( (k,v) -> {
System.out.println("<key>: " + k + " <value>: " + v);
});
Map<Integer, List<String>> nameListByAge = list.stream()
.collect( Collectors.groupingBy(GoodPerson::getAge,
Collectors.mapping(GoodPerson::getName, Collectors.toList())
));
System.out.println("----------------- nameListByAge -----------------");
nameListByAge.forEach( (k,v) -> {
System.out.println("<key>: " + k + " <value>: " + v);
});
}
|
测试结果如下所示:
reduce
该方法可以从Stream流中计算生成一个值,其常用的两种重载形式如下,accumulator参数是一个函数式接口,identity参数则为计算初值。乍一看会觉得reduce方法很复杂,不知如何使用。下面我们来结合具体示例进行说明就会发现虽然看起来复杂但实际用起来还是比较方便简单的
1
2
| Optional<T> reduce(BinaryOperator<T> accumulator);
T reduce(T identity, BinaryOperator<T> accumulator);
|
accumulator参数接收一个含有两个参数的lambda表达式 (param1, param2) ->expression,其中param1参数为上一次expression计算结果,param2参数是从Stream流遍历时中获取的元素,expression表达式计算的结果将会传递并用于下一次计算的param1当中去。对于reduce(BinaryOperator accumulator)方法而言,第一次计算时,param1为Stream流中的第一个元素,param2为Stream流中的第二个元素,示例代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
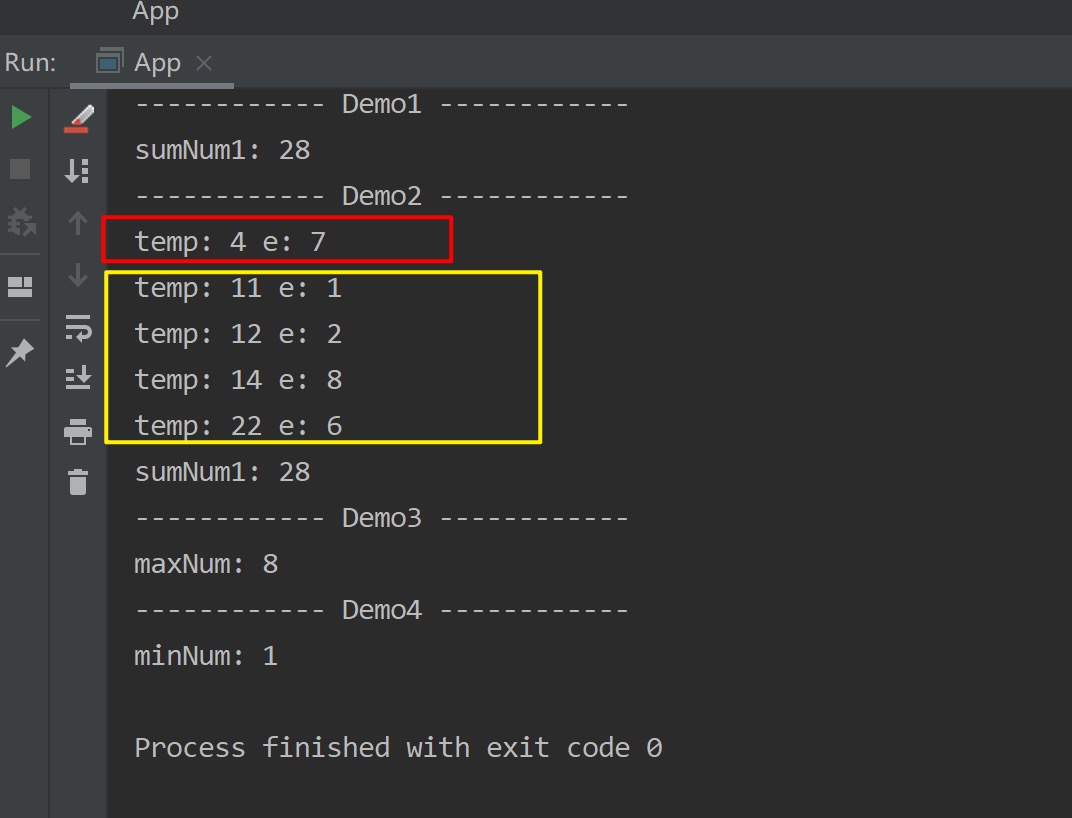
| public static void testReduce1() {
Integer[] array = new Integer[]{4,7,1,2,8,6};
List<Integer> list = Arrays.asList(array);
System.out.println("------------ Demo1 ------------ ");
Integer sumNum1 = list.stream()
.reduce( (temp, e) -> temp + e )
.get();
System.out.println("sumNum1: " + sumNum1 );
System.out.println("------------ Demo2 ------------ ");
Integer sumNum2 = list.stream()
.reduce( (temp, e)->{
System.out.println("temp: " + temp + " e: " + e);
return temp + e ;
} )
.get();
System.out.println("sumNum1: " + sumNum2 );
System.out.println("------------ Demo3 ------------ ");
Integer maxNum = list.stream()
.reduce( Integer::max )
.get();
System.out.println("maxNum: " + maxNum );
System.out.println("------------ Demo4 ------------ ");
Integer minNum = list.stream()
.reduce( Integer::min )
.get();
System.out.println("minNum: " + minNum);
}
|
测试结果如下所示,从demo2中的运行结果,我们也可以看出, 第一次计算(红框)时lambda参数分别取了流中的第一、二个元素,之后计算(黄框)时lambda参数是上次计算结果和从流中遍历获取的元素
另外一种重载形式reduce(T identity, BinaryOperator accumulator),其可通过identity参数来指定accumulator中lambda第一次计算时param1参数的初值,而不是用流中的第一个元素作为初值。示例代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
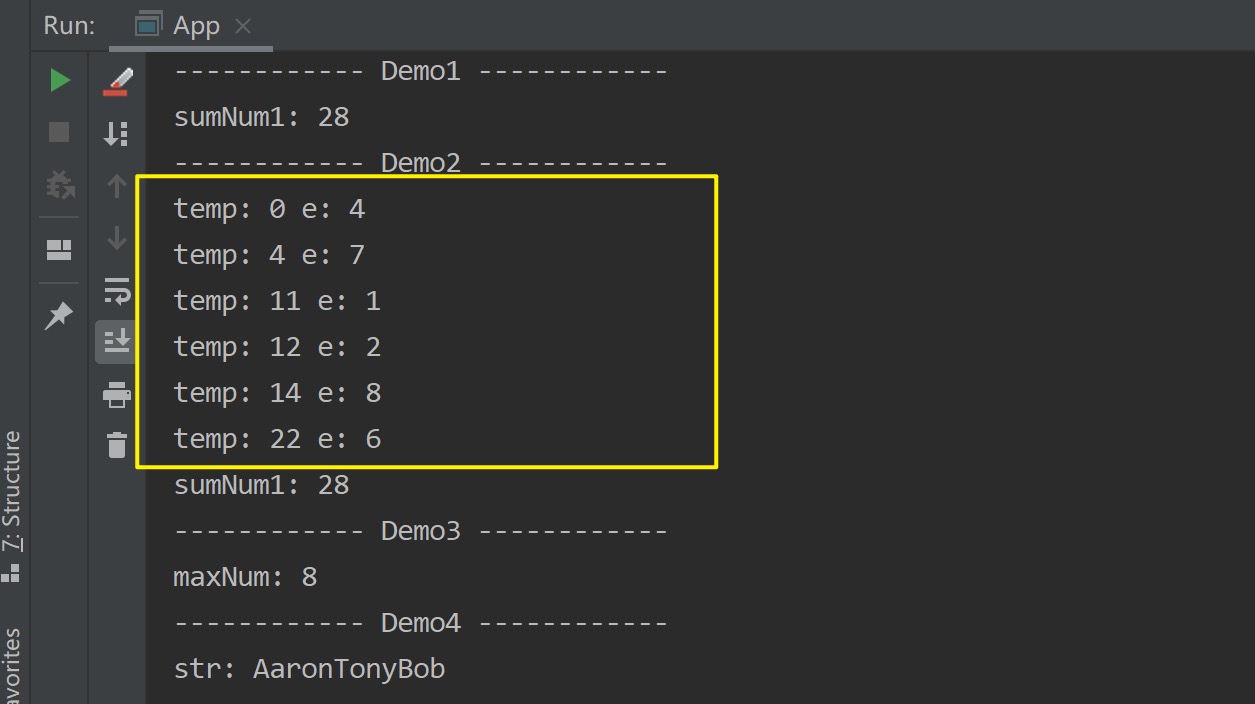
| public static void testReduce2() {
Integer[] array = new Integer[]{4,7,1,2,8,6};
List<Integer> list = Arrays.asList(array);
System.out.println("------------ Demo1 ------------ ");
Integer sumNum1 = list.stream()
.reduce(0, (temp, e) -> temp + e );
System.out.println("sumNum1: " + sumNum1 );
System.out.println("------------ Demo2 ------------ ");
Integer sumNum2 = list.stream()
.reduce( 0, (temp, e)->{
System.out.println("temp: " + temp + " e: " + e);
return temp + e ;
} );
System.out.println("sumNum1: " + sumNum2 );
System.out.println("------------ Demo3 ------------ ");
Integer maxNum = list.stream()
.reduce(Integer.MIN_VALUE, Integer::max );
System.out.println("maxNum: " + maxNum );
System.out.println("------------ Demo4 ------------ ");
String str = Stream.of("Aaron","Tony","Bob")
.reduce("", String::concat );
System.out.println("str: " + str);
}
|
测试结果如下所示:
特性
如上文所言,在Stream中Intermediate 操作允许有零个或若干个,但 Terminal 操作有且只有一个。在一个流中不可有多个Terminal操作,相信大家已经知道了,因为 Terminal 操作会关闭结束流,所以如果存在多个的话,会导致后面的 Terminal 方法出现无流操作的情况。而之所以要求流中必须要有 Terminal 操作,实际上是因为Intermediate操作的Laziness特性所导致的。换句话说,流中的Intermediate操作实际上不是立刻执行生效,只有当Terminal 操作存在后,这个流才开始遍历工作
Stream是从原始数据(数组、集合等)创建的一个新流,我们对流的这个的各种操作都不会影响原始的数组、集合数据
参考文献
- Java核心技术·卷II 凯.S.霍斯特曼著
- Java 8函数式编程 Richard Warburton著
- Java实战·第2版 拉乌尔-加布里埃尔·乌尔玛、马里奥·富斯科、艾伦·米克罗夫特著
