这里来介绍COW(Copy-on-write)写时复制技术,并阐述其在Java中的应用

基本原理
这里以Java集合为场景来解释所谓的写时复制COW(Copy-on-write)机制。当向集合添加、移除元素时,并不是直接操作当前集合,而是首先对原集合进行拷贝、复制到一个新集合中。然后对该新集合进行添加、移除元素的操作。最后,再将对原集合的引用指向新集合即可。该机制的好处就在于当我们访问、读取集合是不需要加锁的,即COW机制是读写分离思想的具体体现。当然其弊端也是显而易见的,一方面由于写操作需要复制操作,所以对于较大规模的集合而言,其耗费的内存也是较为可观的;另一方面,由于读操作访问的是原集合,即使写操作在此期间已经完成。对于前者(读操作)而言也是不可见的,即其保证的是最终一致性
应用实践
Java的ArrayList大家都很熟悉,其是线程不安全的。当多个线程对其进行操作时,由于fail-fast快速失败机制的存在,其会尽可能抛出ConcurrentModificationException并发修改异常。为此针对数组列表,Java提供了一个线程安全的版本——Vector。其通过synchronized关键字实现了线程安全,故效率较低一般较少使用。为此Java还提供了一个基于COW机制的数组列表——CopyOnWriteArrayList。具体来说,该集合在进行读操作时是无锁的。在进行写操作时,则通过ReentrantLock可重入锁来保证当前最多只有一个写线程可以对其进行复制、修改的操作
此外Java还提供了另外一个基于COW机制的并发容器——CopyOnWriteArraySet。具体来说,其首先是一个Set,元素的唯一性与HashSet类似,也是通过元素的equals方法来实现的。其次,其底层数据结构使用的是CopyOnWriteArrayList,即通过数组来存储元素
源码分析
CopyOnWriteArrayList的源码实现还是比较简单的。其一方面,通过ReentrantLock可重入锁来保证当前最多只有一个写线程可以对其进行复制、修改的操作;另一方面,通过volatile保障可见性,使得在写线程结束后,后续的读线程可以立即读取到最新的数据。但在set(int index, E element)方法中,如果发现指定索引处的原数据与新数据一样时,其却存在一行看似没必要的代码——setArray(elements)。原数组的内容虽然没有发生变化,但却依然让volatile变量array再次指向原数组。但本来array也是指向该数组的啊,为什么要多此一举呢?
1 | public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable { |
在解答上述问题之前,我们需要先深刻理解下volatile关键字。在早期的Java内存模型(JMM)中,虽然不允许volatile变量之间进行重排序,但却允许普通变量与volatile变量之间的重排序。由此导致程序发生让人非常难以理解的现象及Bug,故在JSR 133中对volatile的内存语义作了进一步增强,限制了普通变量与volatile变量之间重排序的场景。下面是一个普通变量与volatile变量重排序的例子。假设线程A调用writer方法,线程B调用reader方法。当线程B看到volatile变量v为true时,则后续访问普通变量x一定可以保证其是42。换言之,在线程A执行writer方法过程中,(1)处代码一定先于(2)处代码执行。而在早期的JMM中由于允许普通变量与volatile变量之间的重排序,会导致(2)处代码会被重排序到(1)处代码前面进而先执行。进一步会导致线程B虽然已经看到volatile变量v为true了,但访问变量x值却为0
1 | class VolatileDemo { |
现在回归正题,我们看到在CopyOnWriteArrayList类上的注释对Memory Consistency Effects内存一致性影响所做出的保证:一个线程中放置一个元素到CopyOnWriteArrayList时其之前的动作 happen-before先行发生于 另外一个线程从CopyOnWriteArrayList访问、删除该元素时其之后的动作
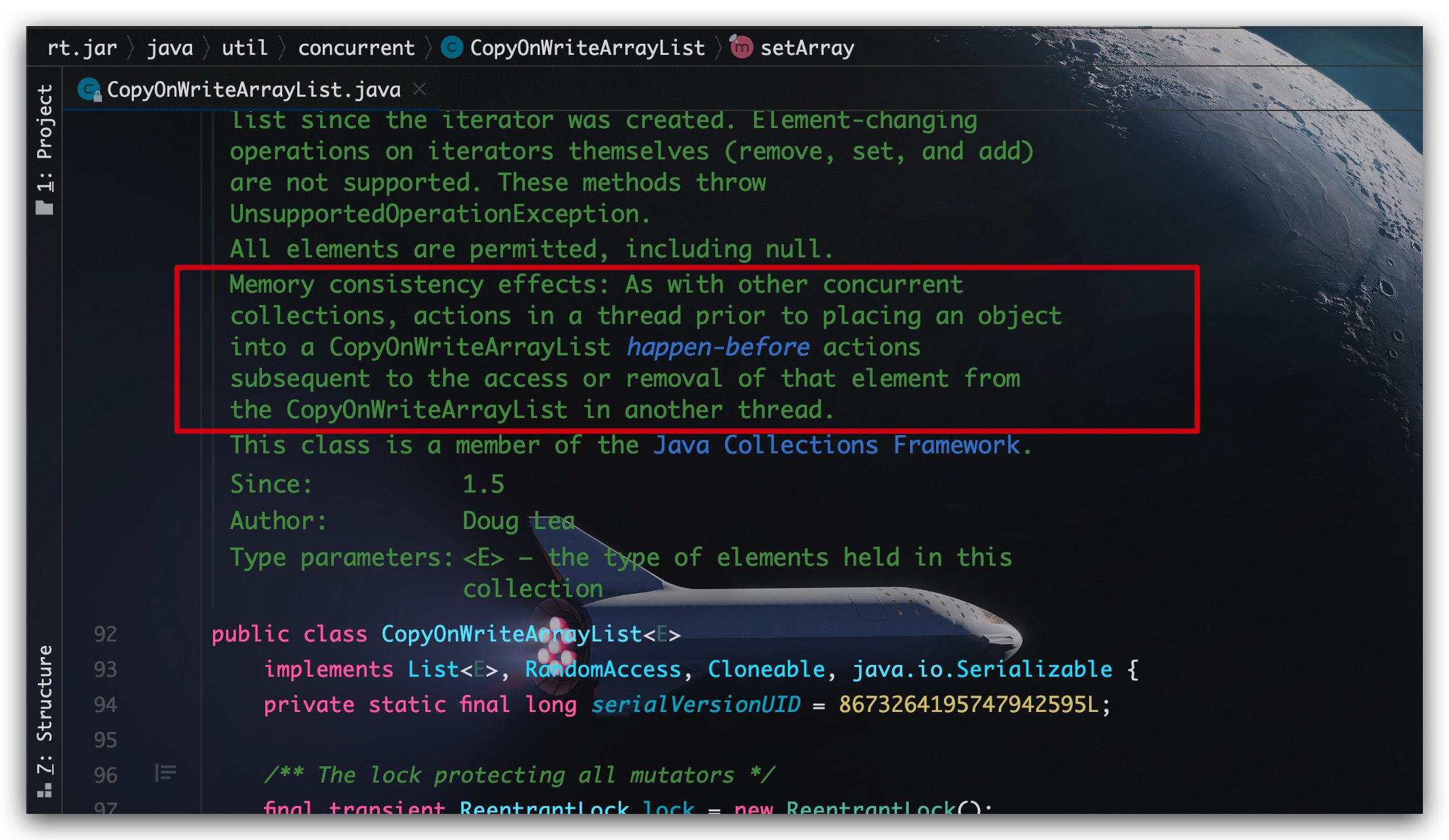
假设现在有个普通变量nonVolatileField其初值为0,有一个CopyOnWriteArrayList实例,其在0位置的元素为x。如果线程1、2分别按如下代码执行。按CopyOnWriteArrayList类的Memory Consistency Effects说明进行分析,则当线程2执行到(4)处代码时,线程1的(1)处代码必然要已经执行完成了,即线程2需要看到普通变量nonVolatileField已经为1了。那如何保证(1)、(2)处的代码不会发生重排序,以避免出现(2)先执行、(1)后执行的局面呢?答案自然是让(2)处代码执行对volatile变量的写。这也就是为什么在set(int index, E element)方法中,即使原数组的内容虽然没有发生变化,但却依然让volatile变量array再次指向原数组。其目的是用于保证volatile变量的写语义
1 | // 初始条件 |
参考文献
- Java并发编程之美 翟陆续、薛宾田著
- 深入理解Java虚拟机·第2版 周志明著
- JSR-133: Java Memory Model and Thread Specification
