前面我们介绍了MySQL下单表查询的相关内容,这里我们来了解下MySQL的多表连接查询

连接查询
就MySQL而言,其连接查询主要有内连接查询、外连接查询两种。具体地就外连接查询而言,又可分为左外连接查询、右外连接查询。这里为了方便介绍各种连接查询的语法、作用。我们先来建立一张学生的信息表stu_info,并向其中插入一些数据,以便于我们后面的演示
1 | -- 创建学生信息表 |
然后,再来建立一张学生的成绩表stu_score,并插入记录数据
1 | create table stu_score( |
至此两张表中的数据如下所示。可以看到两张表中的记录是通过学号字段来进行联系、关联的
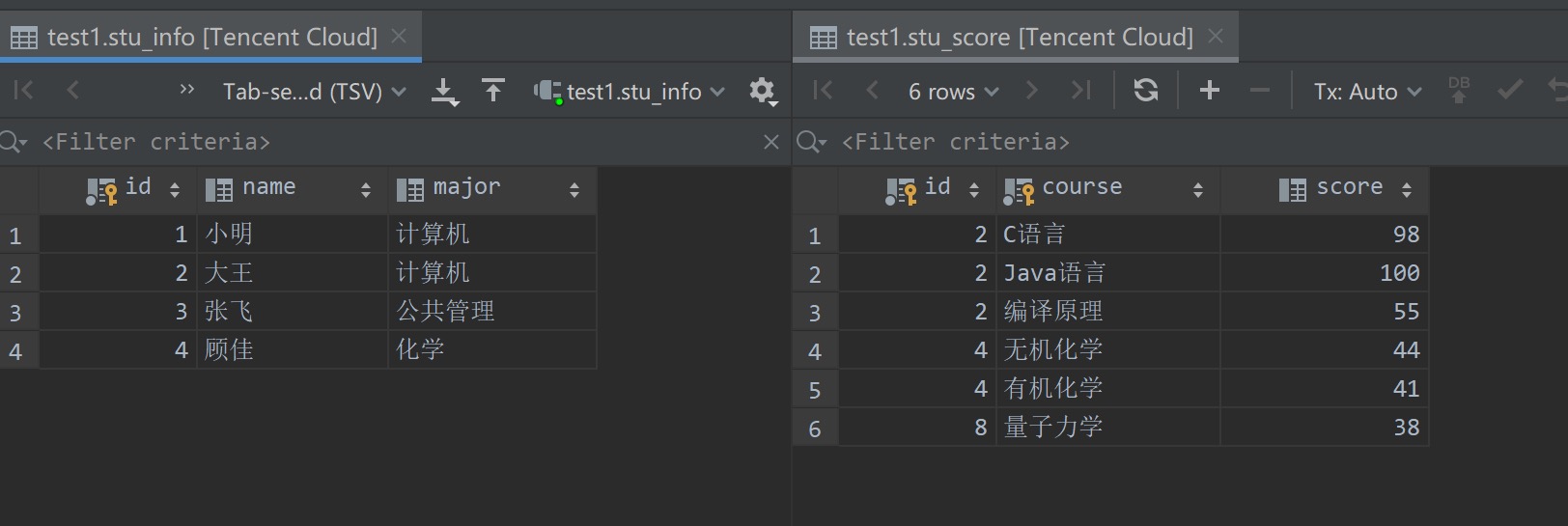
内连接
内连接查询的SQL语法如下所示。其可在on子句中指定两表的连接条件、在where子句中设置查询条件。之所以称之为内连接查询,是因为其只会查询出连接条件在两张表中均能找到的记录
1 | select <欲查询的字段名> from <表1的表名> [inner] join <表2的表名> |
现在,我们期望把学生信息与其对应的各科目成绩查询出来。则SQL语句如下
1 | -- 内连接查询 |
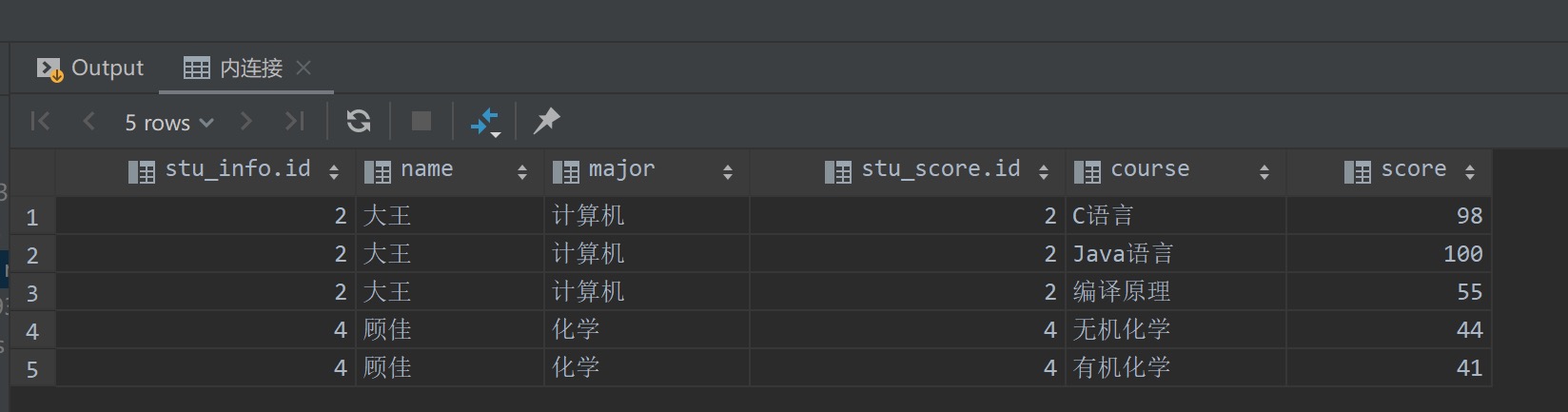
则查询结果如下所示。可以看到信息表stu_info中的小明同学(id学号为1)、张飞同学(id学号为3)的信息并没有查询出来,同理成绩表stu_score中id学号为8的同学信息也没查询出来。因为,上述id学号并没有在另外一种表有相应的记录。即所谓的内连接,实际上相当于查询两张表的交集部分
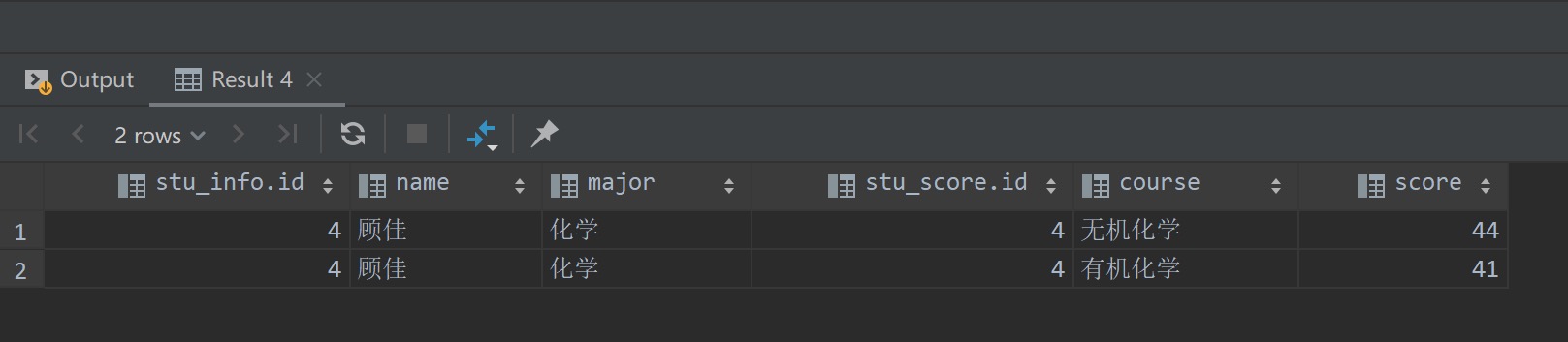
同时还可以在where子句来对连接查询结果作进一步过滤
1 | select * from stu_info inner join stu_score |
查询结果如下所示
左(外)连接
左外连接,又称作左连接。其SQL语法如下所示。其与内连接不同的地方在于,对于左边的表(即表1)而言,即使根据连接条件在右边的表(即表2)找不到匹配的记录,也会查询出来,只不过在结果中涉及表2的字段值会用NULL值来填充
1 | select <欲查询的字段名> from <表1的表名> left join <表2的表名> |
现在让我们来实际验证下,查询SQL如下所示
1 | -- 左外连接查询 |
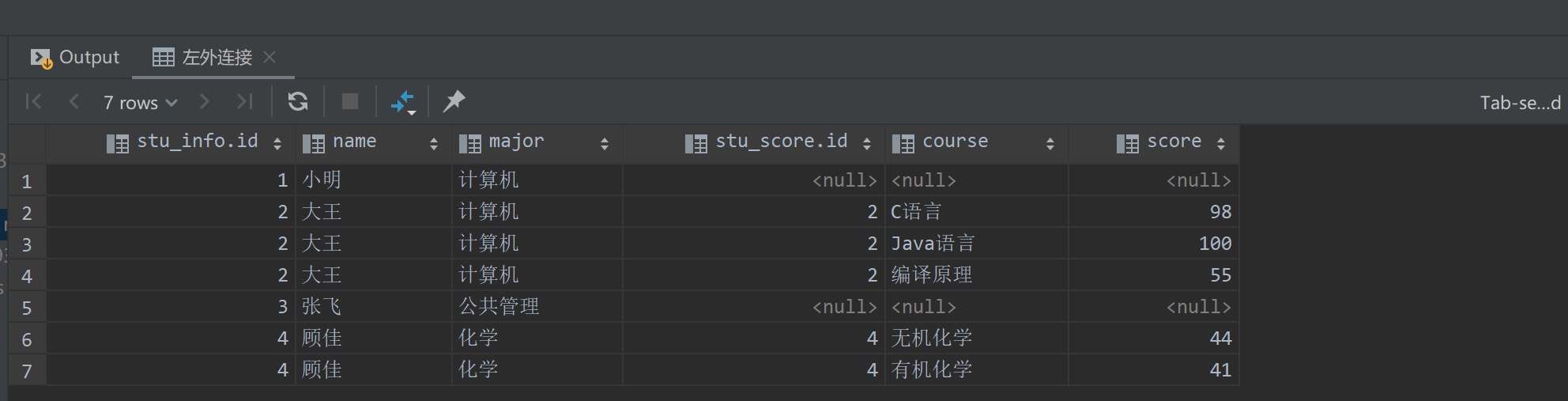
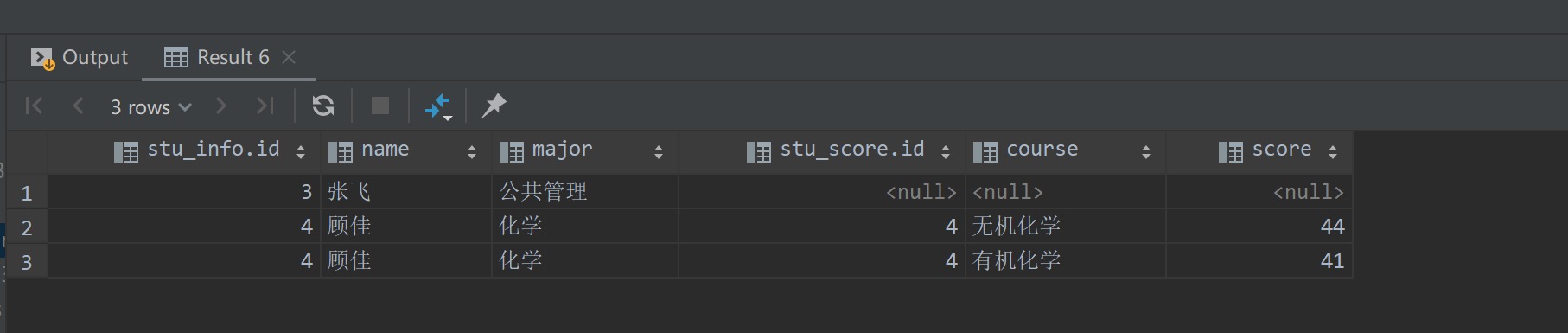
查询结果如下所示,可以看到小明同学(id学号为1)在stu_score中无相应的成绩记录,但是查询结果依然会将其显示出来,只不过使用NULL值来填充stu_score表的字段
对于where子句,其作用与内连接并无区别,均是用于对连接查询的结果作进一步的过滤
1 | select * from stu_info left join stu_score |
查询结果如下所示,符合预期
右(外)连接
对于右外连接而言,其和左外连接很相似。对于右边的表(即表2)而言,即使根据连接条件在左边的表(即表1)找不到匹配的记录,也会查询出来,只不过在结果中涉及表1的字段值会用NULL值来填充。即所谓的方向相反,可以看到实际上左连接查询与右连接查询是可以互相进行转化的,只不过表名的位置正好相反。其SQL语法如下所示
1 | select <欲查询的字段名> from <表1的表名> right join <表2的表名> |
现在让我们来实际验证下,查询SQL如下所示
1 | -- 右外连接查询 |
查询结果如下所示,可以看到虽然右边的stu_score表中id学号为8的记录无法在左边的表中找到相应的学生信息记录,但是依然会显示在最终的查询结果中
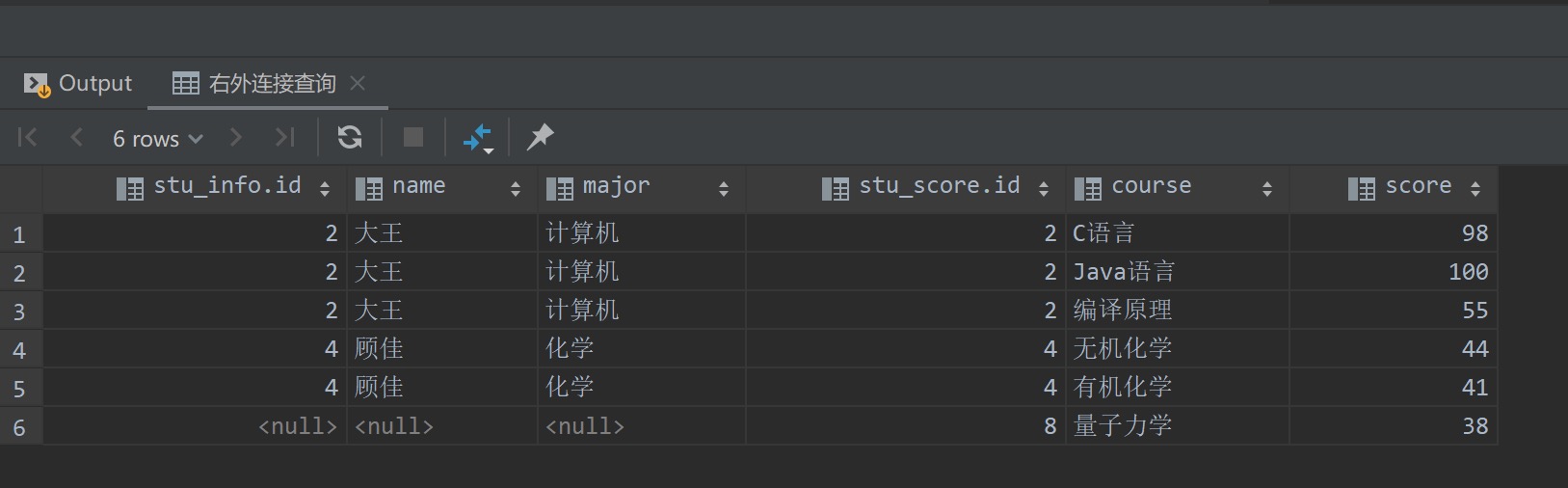
现在我们来看看where子句的过滤作用,SQL查询语句如下所示
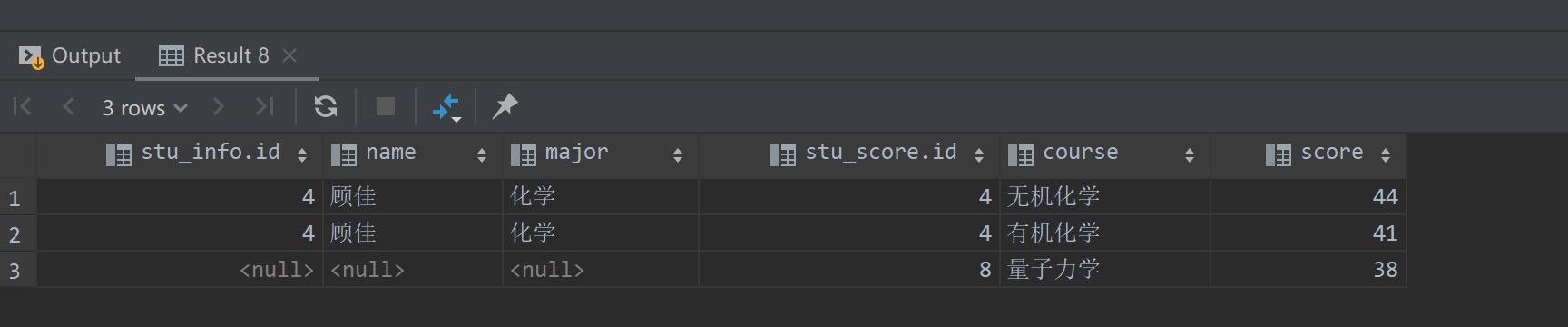
1 | select * from stu_info right join stu_score |
查询结果如下所示,符合预期
查询算法
Nested-Loop Join(NLJ)嵌套循环连接算法
对于连接查询而言,两张表的角色分别为驱动表、被驱动表。具体地,对于外连接(左外连接查询、右外连接查询)而言,表的角色是固定的。即左外连接查询下驱动表是左边的表,右外连接查询下驱动表是右边的表。而对于内连接查询而言,表的角色则是不固定的,驱动表即可以是左边的表也可以是右边的表
对于连接查询而言,最基本的实现算法就是所谓的NLJ嵌套循环连接。该算法的基本流程如下
- 确定驱动表,使用仅与驱动表相关的查询条件,并选择合适的单表访问方法来对其进行单表查询
- 在Step 1中每次从驱动表中获取到一条数据记录,均会选择合适的单表访问方法结合与被驱动表相关的查询条件对被驱动表进行单表查询
使用伪代码来描述如下所示,这也是该算法被命名为”循环嵌套”的缘故
1 | for each row in t1 matching range { |
这里,我们来结合一个外连接查询的具体SQL进行分析
1 | select * from stu_info left join stu_score |
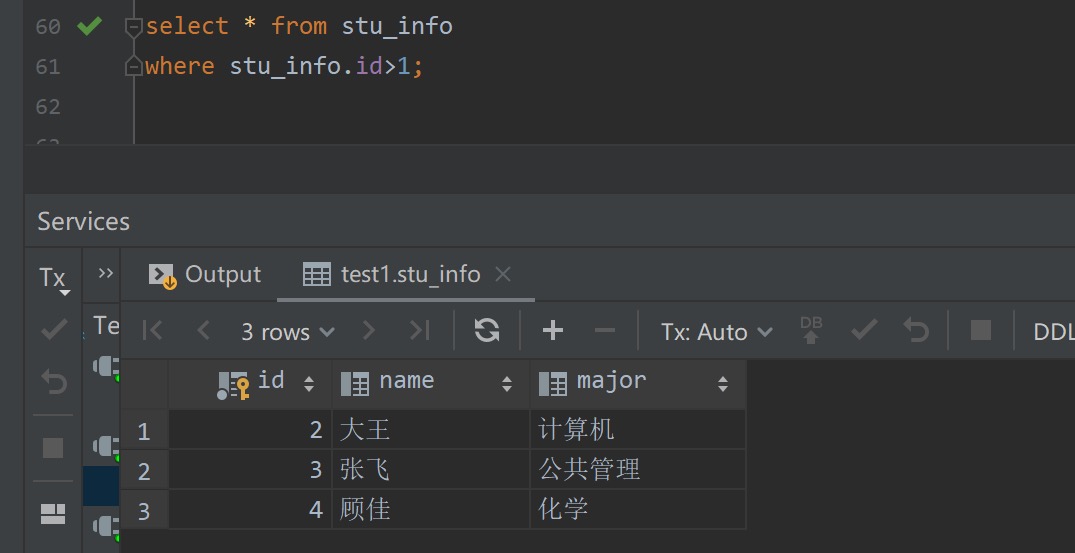
对于该连接查询而言,学生信息表stu_info作为驱动表,学生成绩表stu_score作为被驱动表。我们首先对驱动表stu_info进行单表查询,其涉及到的查询条件只有 stu_info.id>1 ,从下图即可看出该单表查询的结果
每当从stu_info表查出一条数据记录后,即再到stu_score表中进行单表查询。具体地,这里我们以当从stu_info表获取到大王(学号id字段为2)这条数据记录时为例进行分析、说明。此时涉及到被驱动表的查询条件有 stu_score.score<90 。而由于大王的学号为2,则连接条件 stu_info.id = stu_score.id 进一步变为 stu_score.id = 2 ,则此次对被驱动表的单表查询、结果如下图所示。对于学号分别为3、4的张飞、顾佳同学而言,其在被驱动表下的单表查询过程也是类似的。此处即不再赘述
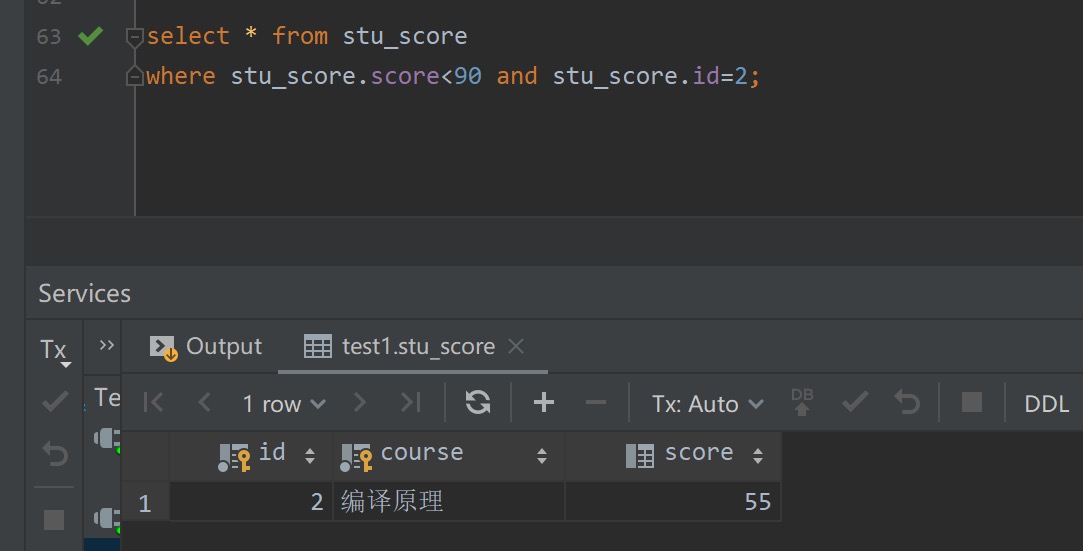
可以看到对于NLJ嵌套循环连接算法而言,其对驱动表的查询虽然只有一次,但却会对被驱动表进行多次单表查询,故该算法的效率是比较低的
基于索引的查询优化
前面我们提到对于NLJ嵌套循环连接算法而言,其会被驱动表进行多次单表查询。那么容易想当的一个优化方案,即是对被驱动表建立相关索引,以避免使用all访问方法这种扫描全表的方式来进行单表查询。值得一提的是,在被驱动表使用 聚簇索引 或 唯一二级索引 来进行非NULL值的等值查询时,这种访问方法被称之为eq_ref,而非我们之前在单表查询中所介绍的const
Block Nested-Loop Join(BNL)基于块的嵌套循环连接
前面我们提到需要对被驱动表进行多次单表查询。而在一次单表查询过程中,如果被驱动表中记录数量过多无法一次性将记录从硬盘全部加载到内存当中时,就需要分多次经历硬盘加载、查询匹配过程。依然以下面的左外连接查询为例,这里我们假设stu_info、stu_score中均有很多数据。在对驱动表进行单表查询时,假设有10条学生信息的数据记录符合查询条件。而在stu_score中共计存在100条数据记录,由于目前内存不够用故一次只能从硬盘中加载25条学生成绩数据到内存当中。则如果使用NLJ算法的话,对于被驱动表的记录,从硬盘加载到内存大概需要 10*(100/25)=40次
1 | select * from stu_info left join stu_score |
为了解决NLJ算法在被驱动表的单表查询过程中,如果被驱动表中记录数过多时需要频繁读取硬盘、加载数据而造成的性能损耗。MySQL下提供了一种基于块的嵌套循环连接(Block Nested-Loop Join,BNL)算法。其基本思想也很简单,先在内存中申请一块区域,被称之为join buffer。其算法流程如下
- 将从驱动表中查询到的数据记录,依次存放到join buffer中直到该内存区域满为止
- 对于被驱动表中的每一条数据记录,一次性与 join buffer 中的多条驱动表数据记录进行匹配查询
- 重复上述过程Step 1~2,直到将驱动表中查询到的数据记录全部处理完毕为止
可以看到通过BNL算法,可以大大减少重复加载被驱动表到内存中的次数,提升连接查询效率。这里依然利用上面的案例来进行量化分析,假设目前join buffer内存中一次最多可以存放5条驱动表中的记录数据,即学生信息记录。而在stu_score中依然是存在100条数据记录,目前同样只能从一次硬盘中加载25条学生成绩数据到内存当中。则在使用BNL算法的情况下,对于被驱动表的记录从硬盘加载到内存大概需要 (10/5)*(100/25)=8次。故在被驱动表中的记录数目较大、机器内存允许的条件下,可通过BNL算法来优化连接查询的效率。具体地,可通过 系统变量join_buffer_size(Unit: Byte)来调整join buffer内存区域的大小
参考文献
- MySQL是怎样运行的
