这里介绍机器学习中用于聚类的K-Means算法

基本原理
该聚类算法可将将数据集划分指定数量的K个簇,其是一种无监督学习的聚类算法。算法流程如下:
- 初始化K个质心,可从数据集中随机抽取K个样本作为初始质心
- 对于数据集中的每个样本而言,分别计算其到K个质心的距离(距离度量一般使用欧式距离,其他可用的度量方式有:曼哈顿距离、余弦距离等),然后将该样本归属到距离最近的某质心所对应的簇当中
- 对于每个簇而言,利用其所属的全部样本,计算平均值作为新的质心
- 重复第2~3步。迭代的终止条件可以组合选用下述条件
- 样本的分类结果没有发生任何变化
- 最大迭代次数
- SSE(Sum of Squared Errors,误差平方和)小于指定阈值
上述的SSE表达的具体含义是:所有样本到其对应簇的质心的距离的平方和。具体公式如下所示。其中,K是簇的数量;C表示该簇所属的全部样本集合,dist(x,μ)表示样本x到质心μ的距离。注意:计算SSE时使用的距离度量 需与 上述第2步使用的距离度量 保持一致
实践
基于Python的实现
这里基于NumPy提供K-Means算法的Python实现,更好的诠释该算法的过程、细节、原理
1 | import numpy as np |
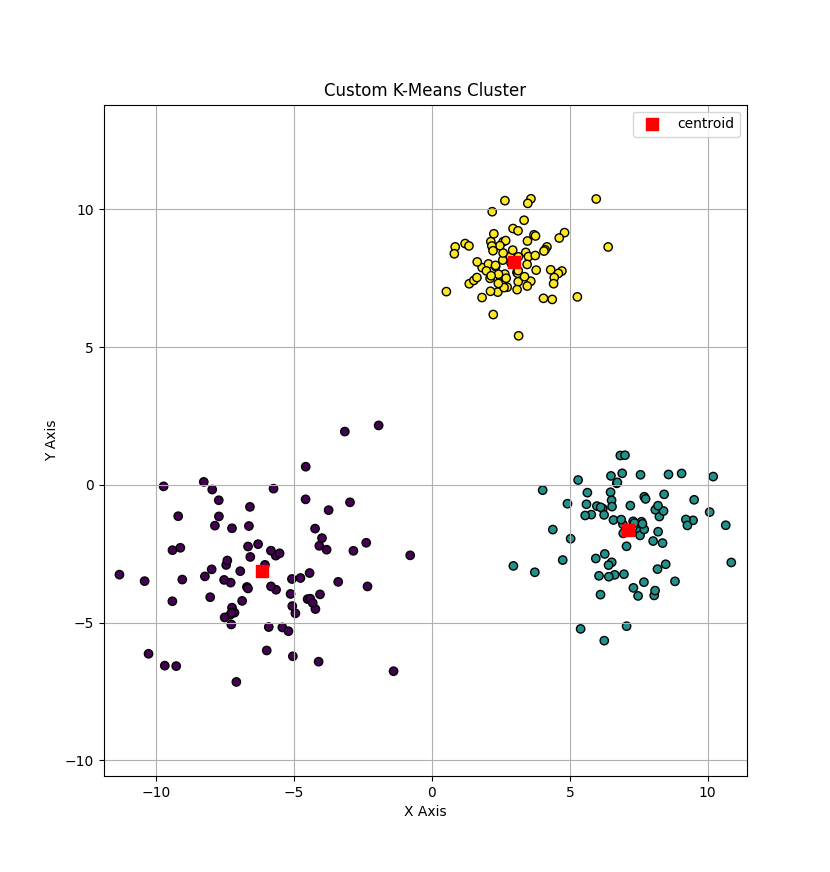
聚类效果如下所示
基于SKlearn的使用
实际开发中可直接使用SKlearn提供的K-Means算法实现。需要注意的是:SKlearn库的KMeans实例只支持使用欧氏距离,不可使用其他距离度量方式
1 | import numpy as np |
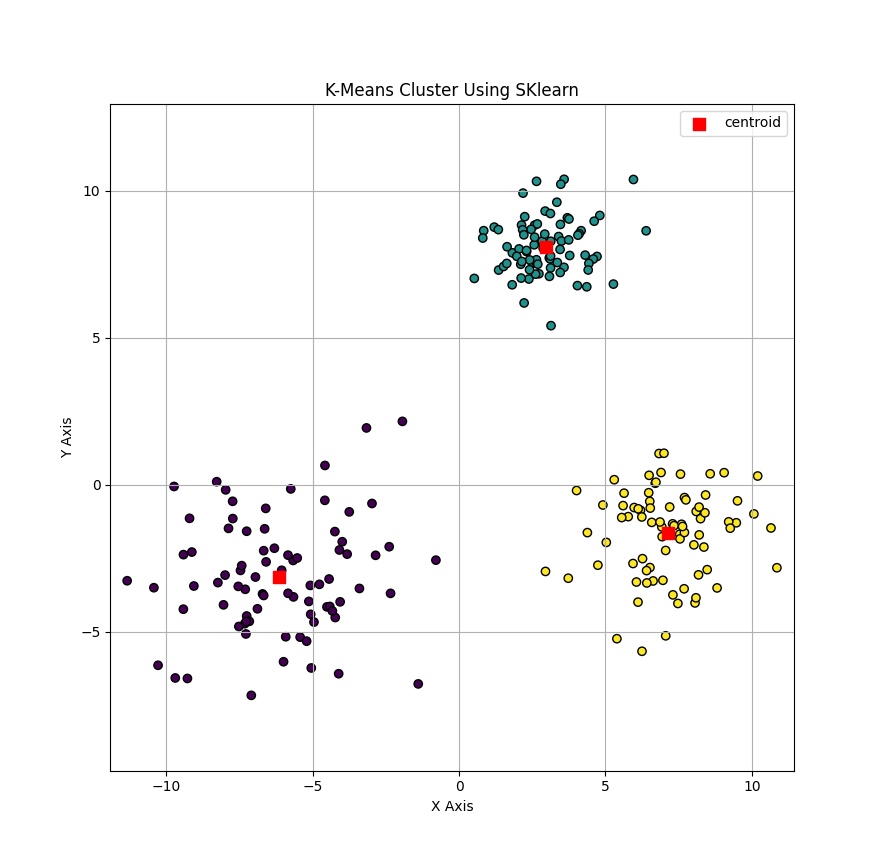
测试结果如下所示
特点
优点
- 无监督学习算法,无需训练集
- 算法简单,易于理解,可解释性强
缺点
- k值选取困难。不合适的k值会产生非预期的结果
- 异常值、噪声敏感:其会影响质心的计算
- 初始选择的k个质心敏感:不同的初始质心可能会导致最终聚类结果发生变化
- 该算法基于距离进行聚类:适用于凸性数据,其能够样本划分为球状类的簇。故对于形状为长条(带状)簇而言不适用该算法
参考文献
- 机器学习 周志华著
- 机器学习公式详解 谢文睿、秦州著
- 图解机器学习和深度学习入门 山口达辉、松田洋之著
