这里介绍机器学习中最简单最朴素的一种分类算法——KNN算法
基本原理 KNN(K-Nearest Neighbors)算法是一种监督学习的分类算法。其底层逻辑很简单:一个样本的类别是由与其距离最近的K个邻居的类别决定。即所谓的近朱者赤,近墨者黑 。具体地:对于一个待分类的样本而言,首先从训练集中找到与其距离最近的K个邻居,然后根据这K个邻居的类别进行投票。此时,投票数最多的类别即为该样本的分类类别。其中,常用的距离度量有欧式距离、曼哈顿距离、余弦距离等
从上述流程不难看出,该算法虽然是一个监督学习算法需要训练集。但其却并不需要进行训练,因为其只是简单地将训练集存储起来,然后在预测推理阶段才会使用该训练集进行计算。故该算法是一个懒惰学习算法
该算法的K值是一个超参数,其表示有多少个邻居参与投票,决定了模型的预测结果、泛化能力。具体地,如果K值过小,则可能会过拟合、泛化能力差;如果K值过大,则可能会导致欠拟合。具体地,K值一般是奇数,以避免投票时出现平局。可根据业务领域经验先确定一个K值的取值范围。然后通过交叉验证法来评估、确定K值的最终取值
实践 下面通过SKlearn提供的KNN分类器来实现一个分类任务。这里选用为经典的鸢尾花Iris数据集。该数据集包含150个样本,选取了鸢尾花的四个特征(sepal length花萼长度、sepal width花萼宽度、petal length花瓣长度、petal width花瓣宽度)用于预测鸢尾花的品种(setosa/versicolor/virginica)
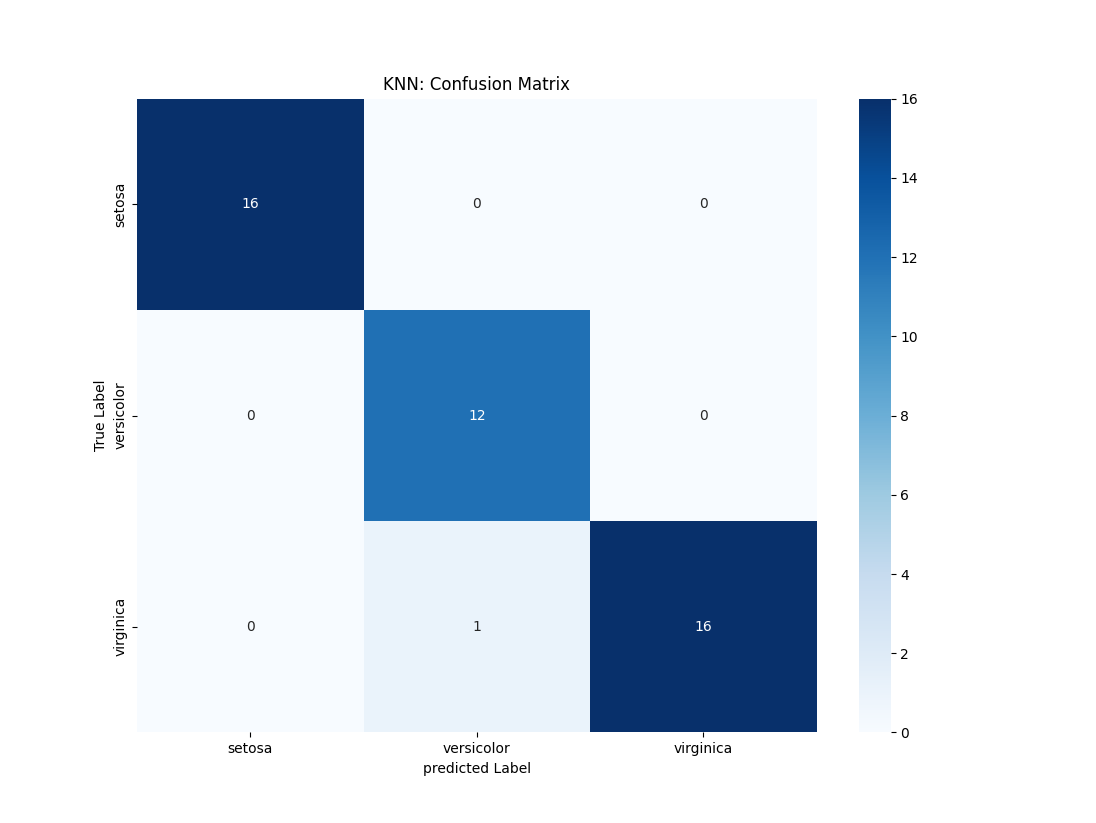
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.metrics import confusion_matriximport seaborn as snsfrom sklearn.metrics import classification_reportiris = datasets.load_iris() X = iris.data y = iris.target feature_names = iris.feature_names label_names = iris.target_names X_train, X_test, y_train, y_test = train_test_split(X, y ,test_size=0.3 , random_state=69 ) knn = KNeighborsClassifier(n_neighbors=3 , metric="euclidean" ) knn.fit(X_train, y_train) y_pred = knn.predict(X_test) report = classification_report(y_test, y_pred, target_names=label_names) print (f"------------------------ 评估指标 ------------------------" )print (f"{report} " )confusion_matrix = confusion_matrix(y_true=y_test,y_pred=y_pred) sns.heatmap(confusion_matrix, annot=True , cmap="Blues" , fmt="d" , xticklabels=label_names, yticklabels=label_names) plt.xlabel("predicted Label" ) plt.ylabel("True Label" ) plt.title("KNN: Confusion Matrix" ) plt.show()
输出结果如下:
1 2 3 4 5 6 7 8 9 10 ------------------------ 评估指标 ------------------------ precision recall f1-score support setosa 1.00 1.00 1.00 16 versicolor 0.92 1.00 0.96 12 virginica 1.00 0.94 0.97 17 accuracy 0.98 45 macro avg 0.97 0.98 0.98 45 weighted avg 0.98 0.98 0.98 45
参考文献