数据预处理作为机器学习中的关键一环,这里介绍其中的Outlier Analysis异常值分析

异常值检测
IQR法,又被称为四分位距法。其是一种基于四分位数的异常值检测方法。四分位数,相对于均值、标准差等指标而言,其不易受到极端异常值的影响。其中:
- 第一四分位数Q1:又称为下四分位数。其是数据集的第25百分位数。即:数据集中有25%的数据 小于等于 它
- 第二四分位数Q2:又被称之为中位数。其是数据集的第50百分位数。即:数据集中有50%的数据 小于等于 它
- 第三四分位数Q3:又称为上四分位数。其是数据集的第75百分位数。即:数据集中有75%的数据 小于等于 它
IQR 四分位距(Interquartile Range)指的是上四分位数(Q3)与下四分位数(Q1)之间的差值。显然该指标衡量的是数据集中间那50%的数据的分布宽度。该指标忽略了数据两端的极端值,而聚集于核心部分
进一步地,IQR法定义了一个合理数据的上下限。对于超过这个界限的数据,我们就可以认为是Outlier异常值。具体如下。其中,IQR前的系数通常取统计学上的经验值1.5
- 合理数据的上限 W_upper :Q3 + 1.5 * IQR
- 合理数据的下限 W_lower :Q1 - 1.5 * IQR
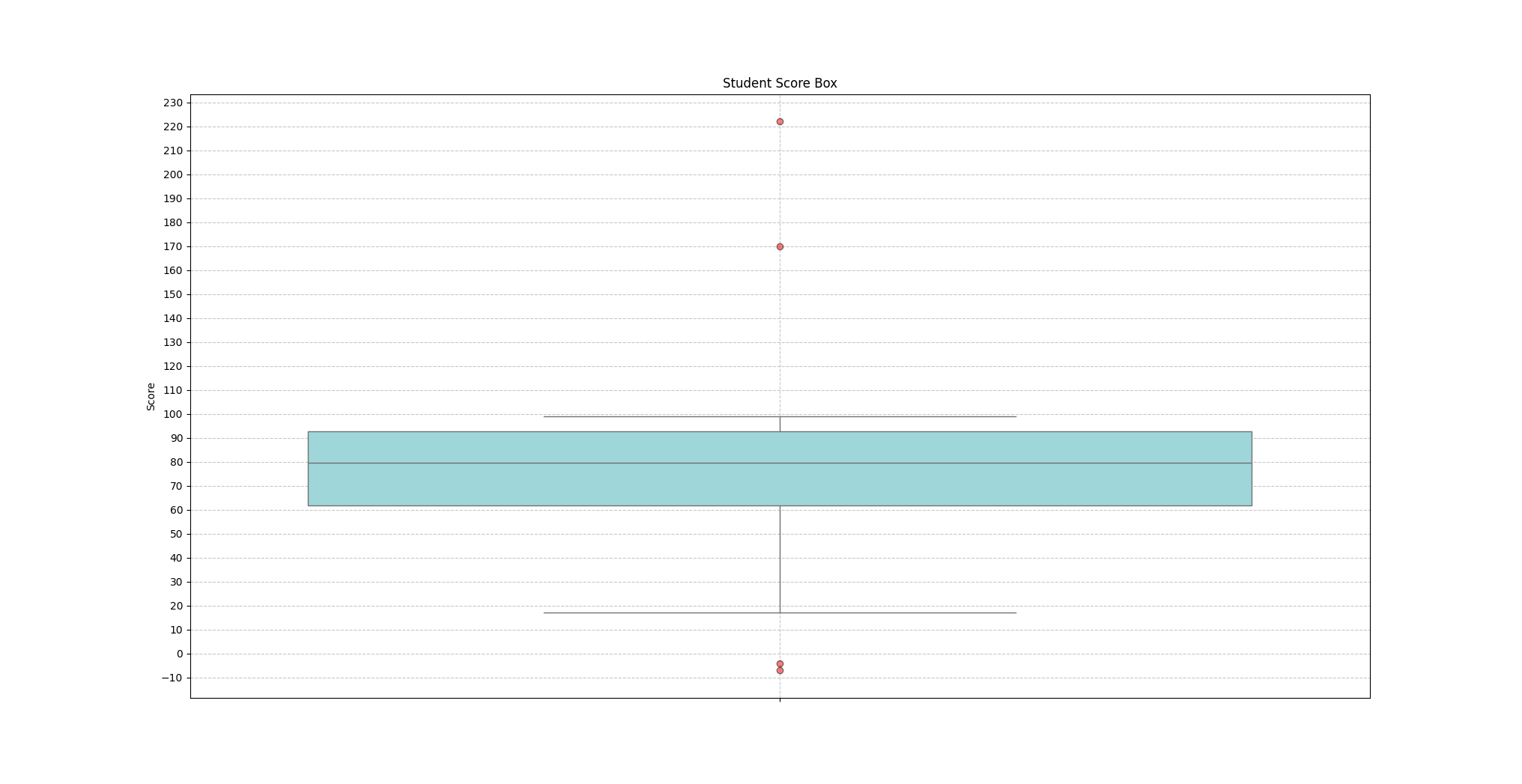
下面使用Pandas、Seaborn来展示如何使用IQR检测、识别数据集中的异常值,并绘制箱线图进行可视化展示。其中箱线图的含义如下:
- 箱体的下边缘:即箱底,表示第一四分位数 Q1
- 箱体的上边缘:即箱顶,表示第三四分位数 Q3
- 箱内的横线:表示第二四位数Q2,即中位数
- 箱体的高度:表示IQR四分位距
- 上须线的末端:表示数据集中不超过上限W_upper的最大样本值。即:max{x ∣ x ≤ W_upper}
- 下须线的末端:表示数据集中不低于下限W_lower的最小样本值。即:min{x ∣ x ≥ W_lower}
- 超过上下限范围[W_lower,W_upper]的数据点:表示异常值
1 | import pandas as pd |
输出结果如下
1 | Origin Data: |
异常值处理
异常值检测出来后,可通过下述常见策略进行处理:
- 删除:删除包含存在异常值的样本。但这样会导致数据集中样本数量减少
- Capping盖帽:将超出边界的异常值直接替换为相应的边界值
- 替换:将异常值视作为缺失值,然后使用某种策略(均值/众数/中位数)进行填充
- Binning分箱:将连续的数值变量转换为离散的类别变量。此时,异常值的具体数值将不再重要。因为其会被归为最高或最低的某个类别中
参考文献
- 机器学习 周志华著
- 机器学习公式详解 谢文睿、秦州著
- 图解机器学习和深度学习入门 山口达辉、松田洋之著
