PostgreSQL,同样作为关系型数据库的一员。由于其优秀的性能,现在已经越来越广泛地被使用。这里简单介绍下在使用PostgreSQL过程中需要注意的Tips

选择数据库
和MySQL一样,PostgreSQL在本地安装后也提供了一个命令行客户端——psql。通过psql不仅可以执行SQL命令,还可以执行PostgreSQL的元命令(以 反斜杠\ 开头的命令)。比如在PG下选择数据库时,其只支持元命令(\c database)并没有相应的SQL命令。不像MySQL可以通过SQL命令实现(use database)切库。与此同时,在开发过程中更多的会选择GUI客户端来操作数据库。这里我用的即是Jetbrains的DataGrip。而在DataGrip下无法通过执行PG的元命令选择数据库
事实上,可以通过Console File右上角的下拉框来选择我们的所需的database、schema
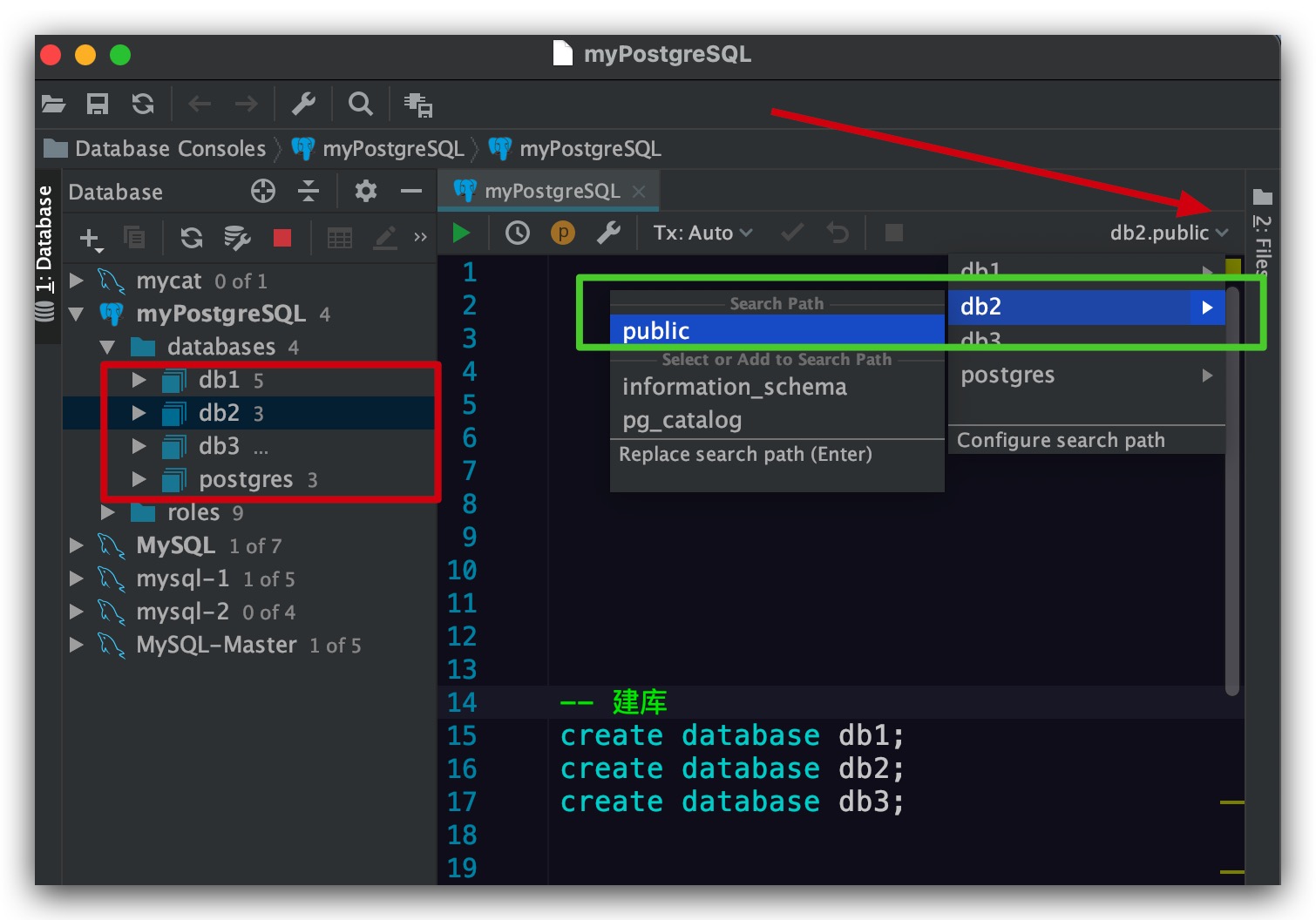
选择Schema
在SpringBoot中,若JDBC URL中未指定Schema则默认使用数据库的public Schema。故如果期望连接、使用自定义的Schema可在JDBC URL中使用currentSchema参数实现。示例如下所示
1 | # 设置数据源为 db1数据库的sh1 schema |
左模糊查询: char、varchar类型
WHERE语句中可以使用LIKE进行模糊查询,这里需要特别注意char、varchar类型的左模糊查询问题。先建立一张表并插入一些数据
1 | -- 建表 |
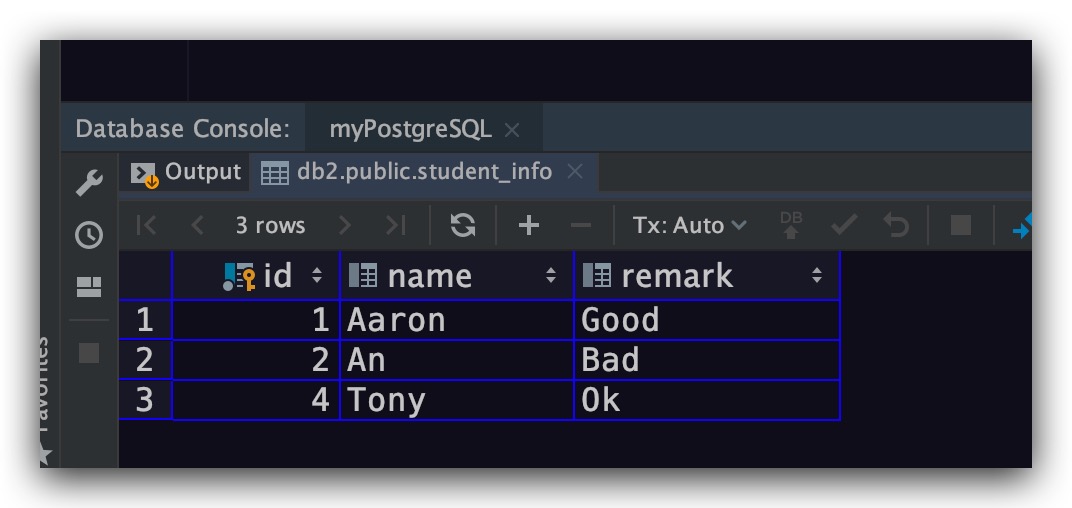
表中数据如下所示
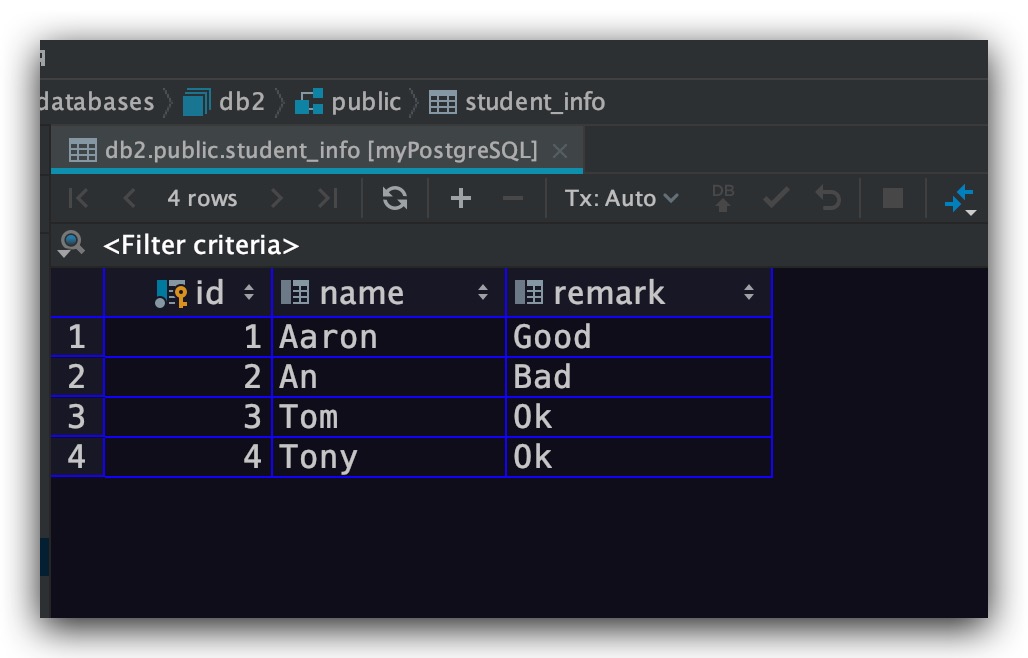
现在分别对name、remark字段进行左模糊查询
1 | -- 对remark字段进行左模糊查询,查询remark字段以d结尾的数据 |
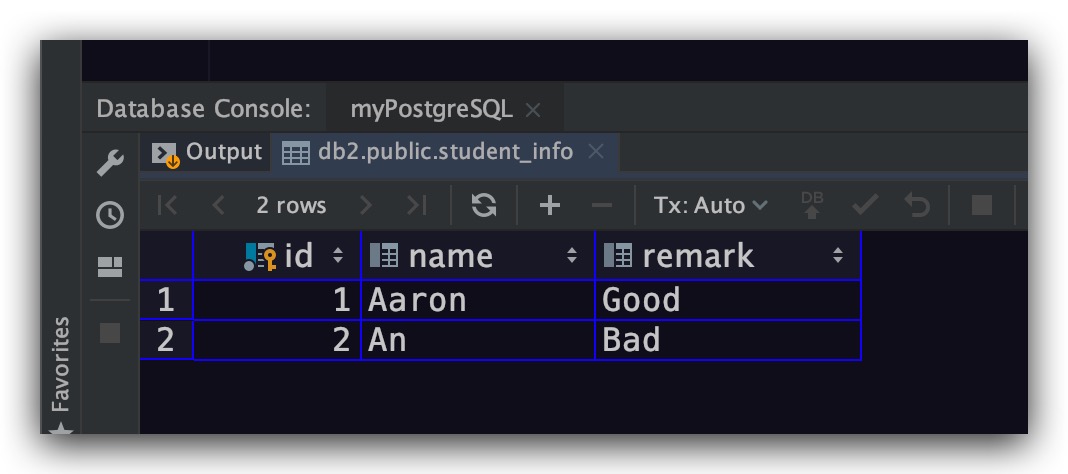
结果符合预期
1 | -- 对name字段进行左模糊查询,查询name字段以n结尾的数据 |
查询结果却为空,这显然不符合我们的预期
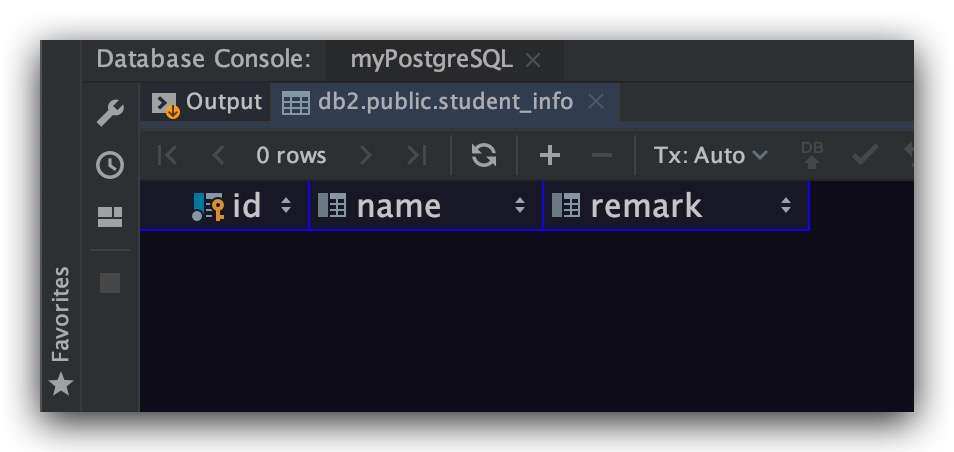
其原因就在name字段为char(100)类型。即name字段固定占100个字符,不足会在尾部补空白。在进行LIKE匹配时,这个填充空白并没有移除掉。上表中所有记录的name字段显然都是以填充的空白结尾的,故导致我们的查询结果为空;而remark字段为varchar(100)类型,即变长类型。其不会填充空白
现在我们修改查询语句,来查询name字段含n的数据。如下所示
1 | -- 对name字段进行模糊查询,查询name字段含n的数据 |
结果符合预期
自增主键
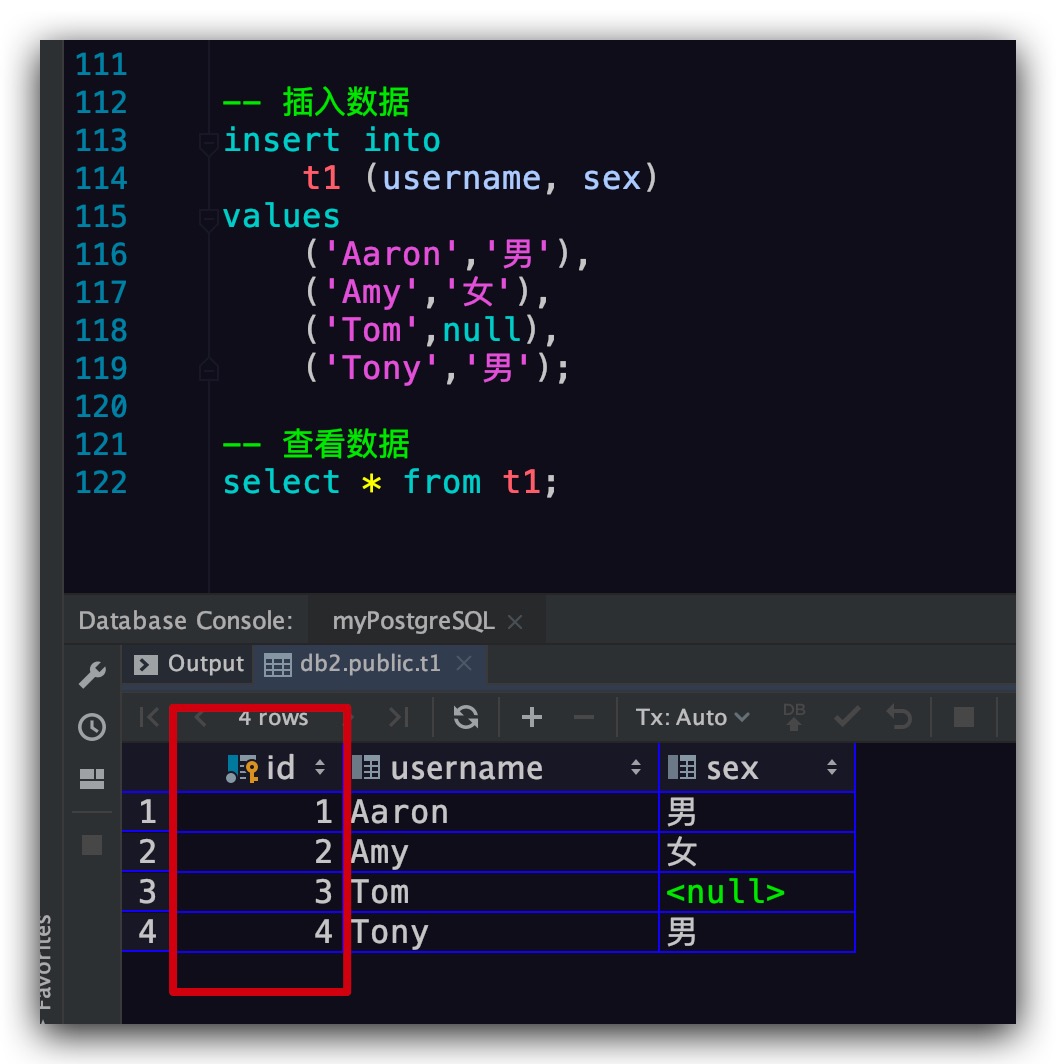
MySQL下可以通过AUTO_INCREMENT属性实现主键自增。而在PostgreSQL下如果想要实现主键自增则可以通过序列来实现。如下代码所示,我们先定义一个名为t1_seq的序列,然后将主键的默认值设为该序列的下一个值,这样即可实现所谓的主键自增。其中, :: 是PostgreSQL的类型转换符
1 | -- 定义一个序列 |
测试效果如下,符合预期
事实上我们也可以在建表的时候,直接将主键字段的类型设为serial,以实现主键自增。其实serial类型并不是真正的数据类型,其本质上依然还是创建了一个序列
1 | -- 创建表,并将主键类型设为serial,实现主键自增 |
继承
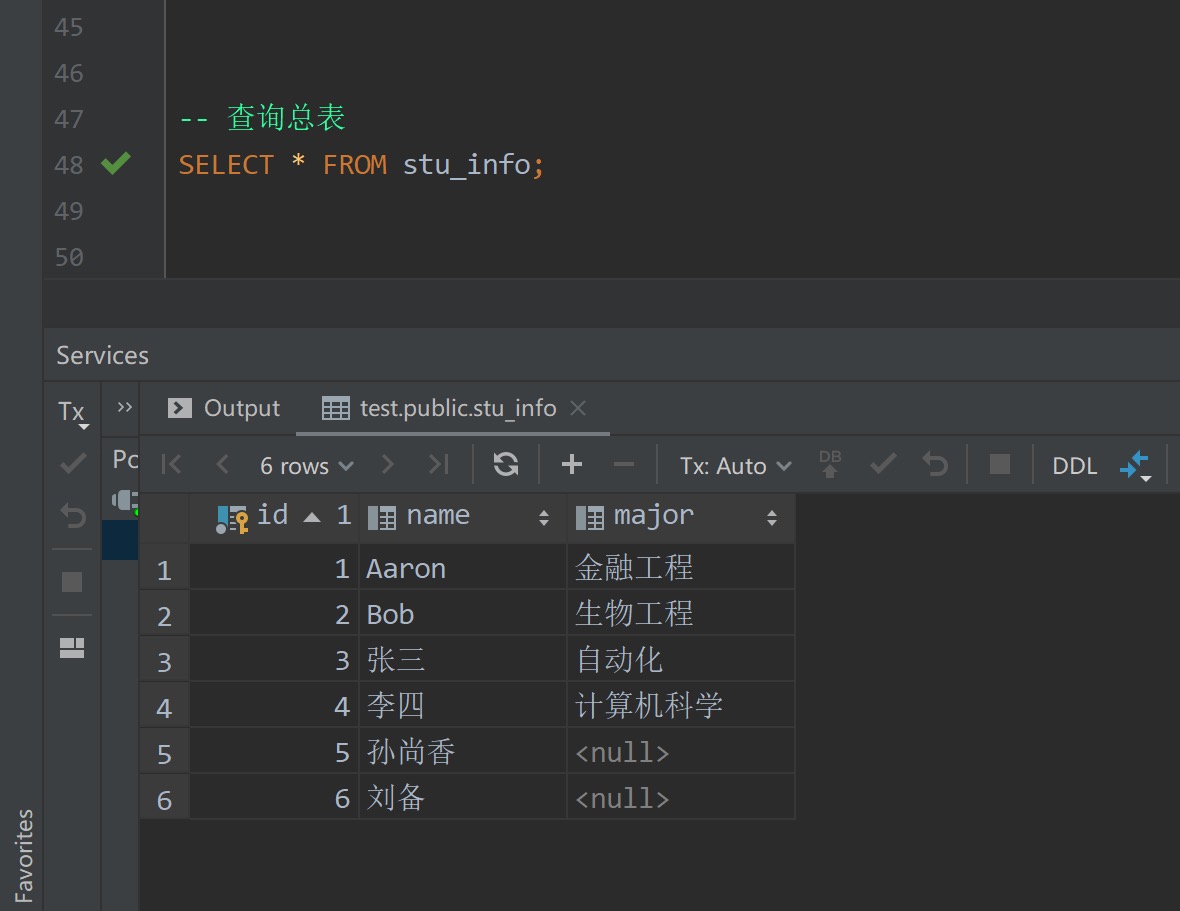
PostgreSQL中特别地提供了表的继承。这样在查询父表的数据同时,还可以将子表的数据也一并查询出来。示例如下
1 | -- 建立学生信息总表: stu_info |
现在我们查询总表的数据
1 | -- 查询总表 |
测试结果如下,符合预期
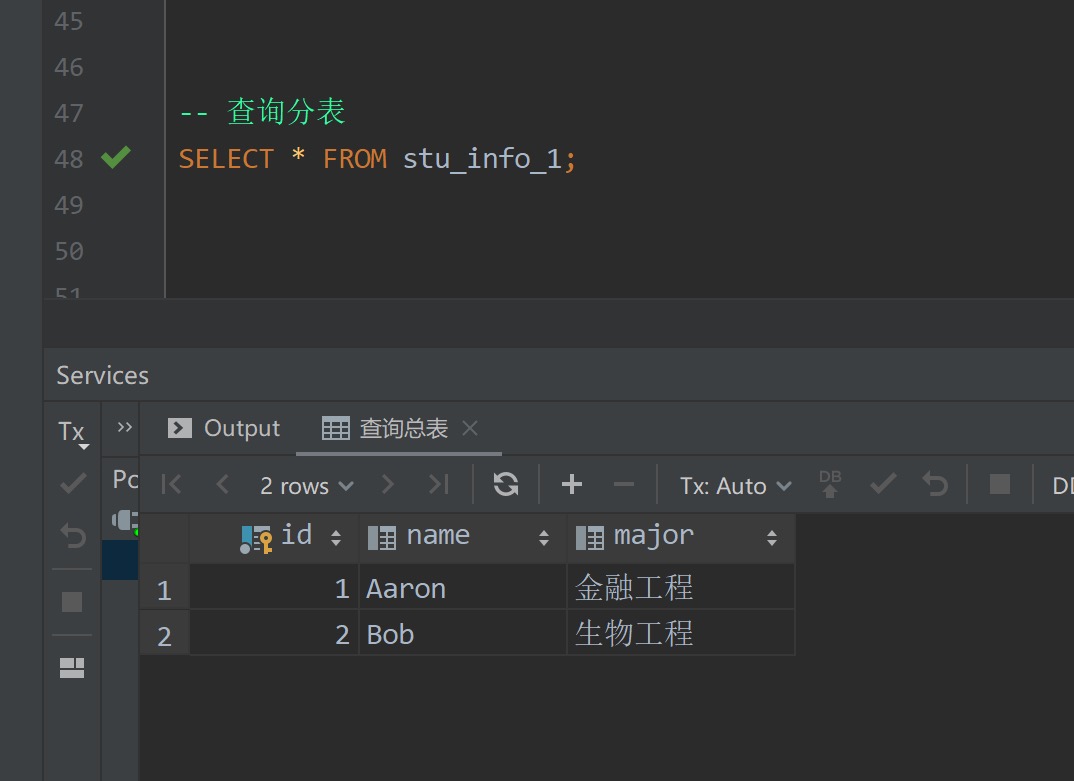
当然也可以只查询某个分表
1 | -- 查询分表 |
测试结果如下,符合预期
由于PG此特性,可以大大简化分表场景下的数据查询工作。即数据只存储在各分表中,而父表不存储数据仅用于查询。当然有时我们不仅需要从总表查询数据,还需要确定相关数据在哪个分表中。可以查看记录的隐藏字段tableoid实现
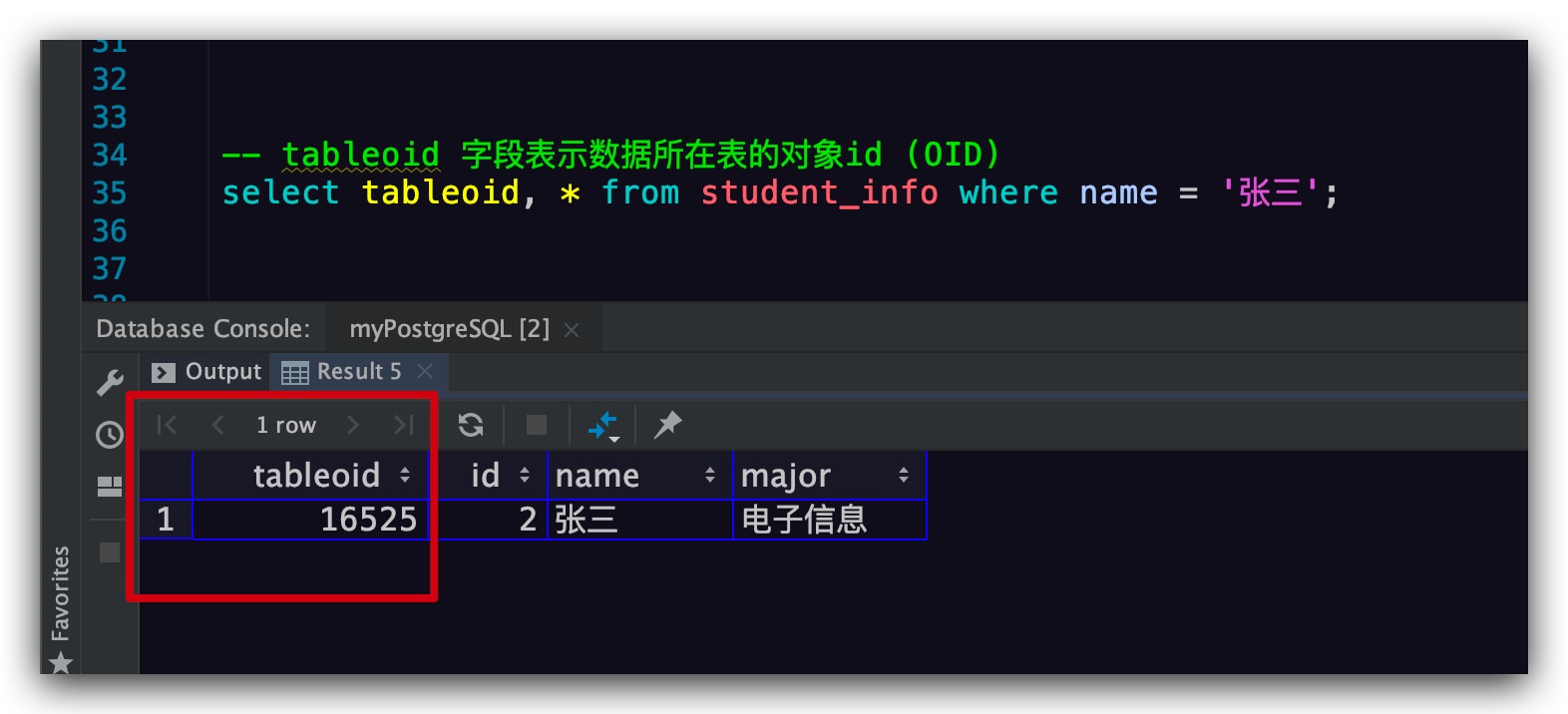
1 | -- tableoid 字段表示数据所在表的对象id (OID) |
可以看到,该记录的tableoid字段值为16525
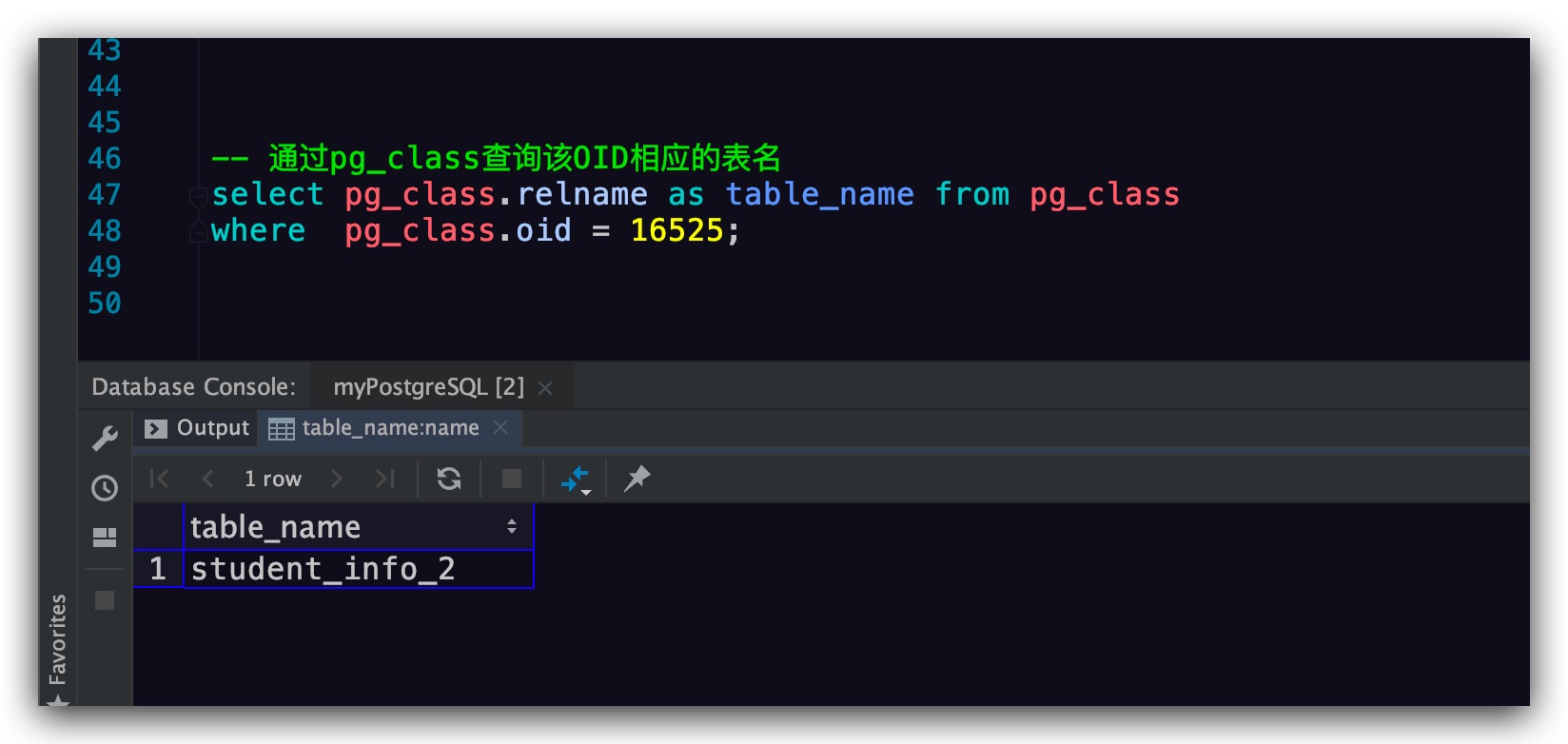
进一步地,通过系统表pg_class确定该oid所表示的表
1 | -- 通过pg_class查询该OID相应的表名 |
结果符合预期,如下所示
表间数据复制
INSERT INTO SELECT 语句
PG支持INSERT INTO SELECT语句进行表间的数据复制,要求目标表必须存在。示例如下所示
1 | -- 将t_people_old表中符合条件的数据记录(所有字段) 复制到 t_people_new表中 |
SELECT INTO 语句
对于表间的数据复制,PG还提供了对SELECT INTO 语句的支持。其要求目标表不存在, PG其会根据插入的字段自动创建目标表。示例如下所示
1 | -- 将t_people_old表中符合条件的数据记录(所有字段) 复制到 t_people_new表中 |
