这里介绍机器学习中常见的一种分类算法——Random Forest随机森林

Ensemble Learning 集成学习
集成学习Ensemble Learning并不是指一种具体的机器学习算法。它实际上是指通过组合多个算法模型来获得比单个算法模型更好的性能、效果。换言之,其核心思想的底层逻辑是——三个臭皮匠,顶个诸葛亮。常见的组合方式有:Bagging 装袋法、Boosting 提升法、Stacking 堆叠法
Bagging 装袋法
Bagging是Bootstrap Aggregating的缩写,故又被称为自助聚合法。Bootstrap自助法是统计学中的一种抽样方法,其通过样本集中进行若干次有放回的随机抽样来创建一个样本子集(也被称之为自助样本)。这样重复多次即可创建出多个样本子集。由于是进行有放回的抽样,故一些样本可能会在某个样本子集中重复出现多次,而另一些样本可能在某个样本子集中从未出现过
Bagging法的基本流程:
- 首先,利用Bootstrap自助法从训练集中创建N个样本子集
- 然后,分别使用上述的N个样本子集,并行地训练出N个模型。其中,这N个模型使用的都是同一种机器学习算法。只是用于训练的样本子集不同,进而导致这N个模型之间的模型参数存在些许差异
- 预测时,先利用这N个模型分别进行预测,然后对N个结果进行聚合得到最终的预测结果。具体地,针对分类任务,可采用投票的方式;针对回归任务,可采用平均的方式
Boosting 提升法
当某算法的一个模型在训练集上完成训练后,该算法的下一个版本模型会继续使用该训练集进行训练。但在训练过程中,会更加关注上一个版本模型预测错误的样本(例如,增加预测错误样本的权重等)并试图纠正这些错误,来提升本次训练的效果。这样迭代重复多次,即可得到N个模型。可以看到Boosting 法不同于Bagging 法,后者是并行的,而前者是串行的训练同一种机器学习算法的N个模型。且每个版本模型的训练都依赖于上一个版本模型的结果,从而实现逐渐提升整体性能的目标,故此得名提升法
预测时,同样会利用这N个版本的模型分别进行预测,然后对N个结果进行加权投票(对于分类任务)或加权平均(对于回归任务)来得到最终的预测结果。其中,权重与模型的性能相关
Stacking 堆叠法
该方法通过组合多种不同的机器学习算法来提升泛化能力,但训练过程较为复杂。具体地:
- 首先,利用 原始的训练集 作为输入,分别训练出多种不同算法的模型,即所谓的基模型
- 然后,将这些 基模型的预测结果 作为新的特征,以构成 元模型的训练集
- 最后,利用 元模型的训练集 作为输入训练出一个新的模型,即所谓的元模型
预测时,先使用基模型进行预测;然后,将基模型的预测结果作为元模型的输入;最后,元模型的输出结果即为最终的预测结果
基本原理
Random Forest随机森林是一种典型的基于Bagging装袋法的集成学习算法。具体地,其通过构建、组合多个决策树模型来提升准确性。故该算法是一种用于多分类任务的监督学习算法。其核心流程如下:
- 首先,通过Bootstrap自助法从原始的训练集中进行有放回的随机抽样,创建N个样本子集。为避免投票出现平局,N通常为奇数
- 然后,对每个样本子集分别生成、构建出一个决策树,这样就会得到N个决策树,即所谓的森林
- 预测时,使用这N个决策树分别进行预测,然后对N个结果进行投票。即可得到最终的预测结果
与传统的决策树算法流程不同之处在于,使用样本子集构建决策树过程中,其会在每次节点进行分裂时,先从全部特征集合中随机选取部分特征,构成一个随机的特征子集。 然后从这个随机的特征子集中来挑选最佳的特征来进行节点的分裂。这使得每个树的结构都具有足够的随机性,从而提高随机森林模型整体的多样性、泛化性。此外,由于随机森林在构建决策树时,采用了随机样本(Bootstrap自助法挑选的样本子集)、随机特征(每次节点分裂从随机的特征子集中挑选最佳特征)降低了过拟合风险。故其在构建决策树通常不会进行后剪枝,以降低计算成本
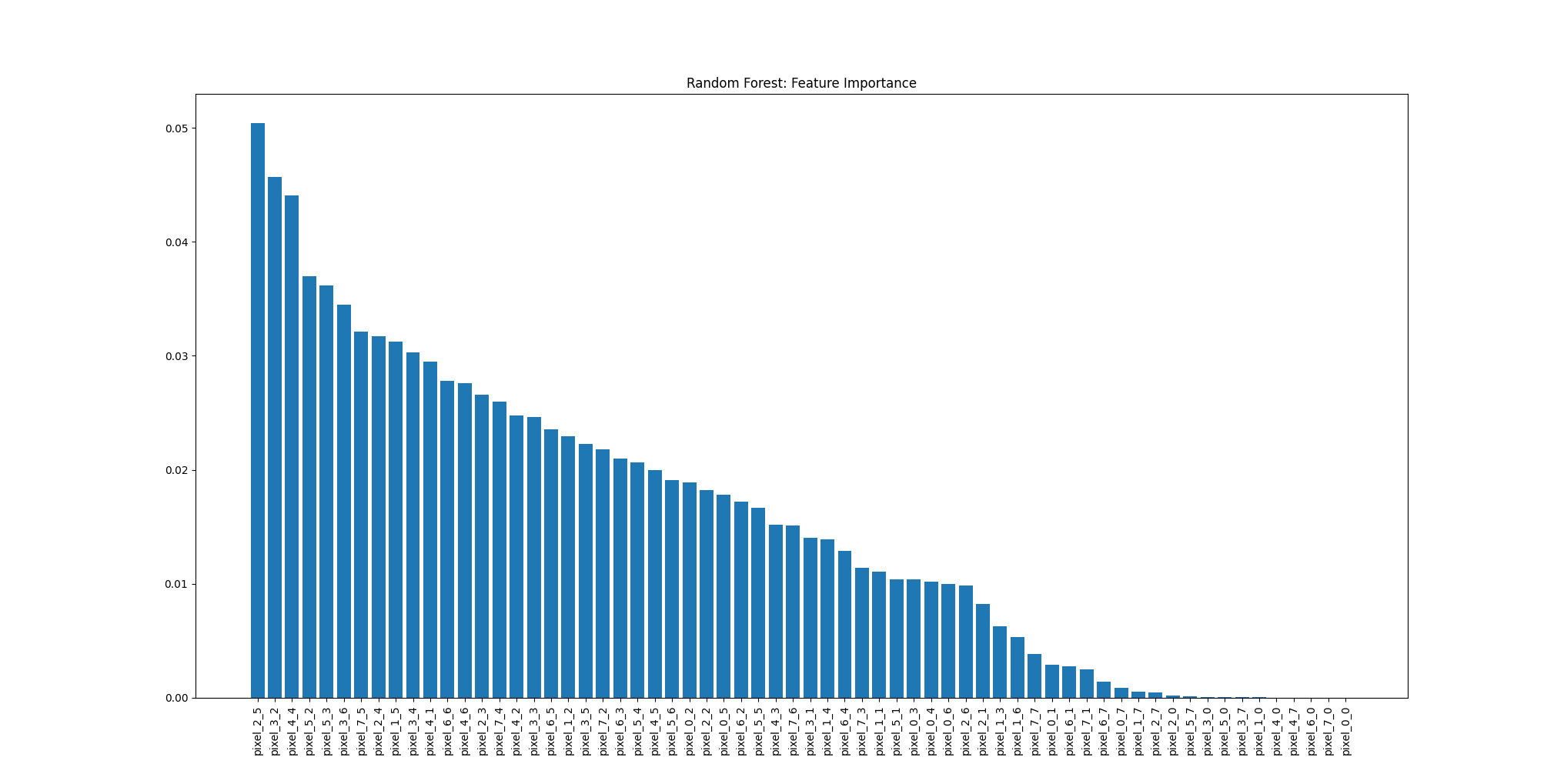
在随机森林模型中通常包含大量的决策树,这样即使将所有树的结构进行可视化,人工观察的方式也很难快速、直观判断出各特征的重要性。为此,随机森林模型在实现的过程中,通常会去统计各特征的Feature Importance重要性分数。该指标综合考虑了特征在各决策树中被选中进行分裂的次数、每次分裂带来的纯度提升。这样当模型训练完毕后,我们只需通过查看各特征的重要性分数,即可帮助我们更好地去理解模型的决策依据
实践
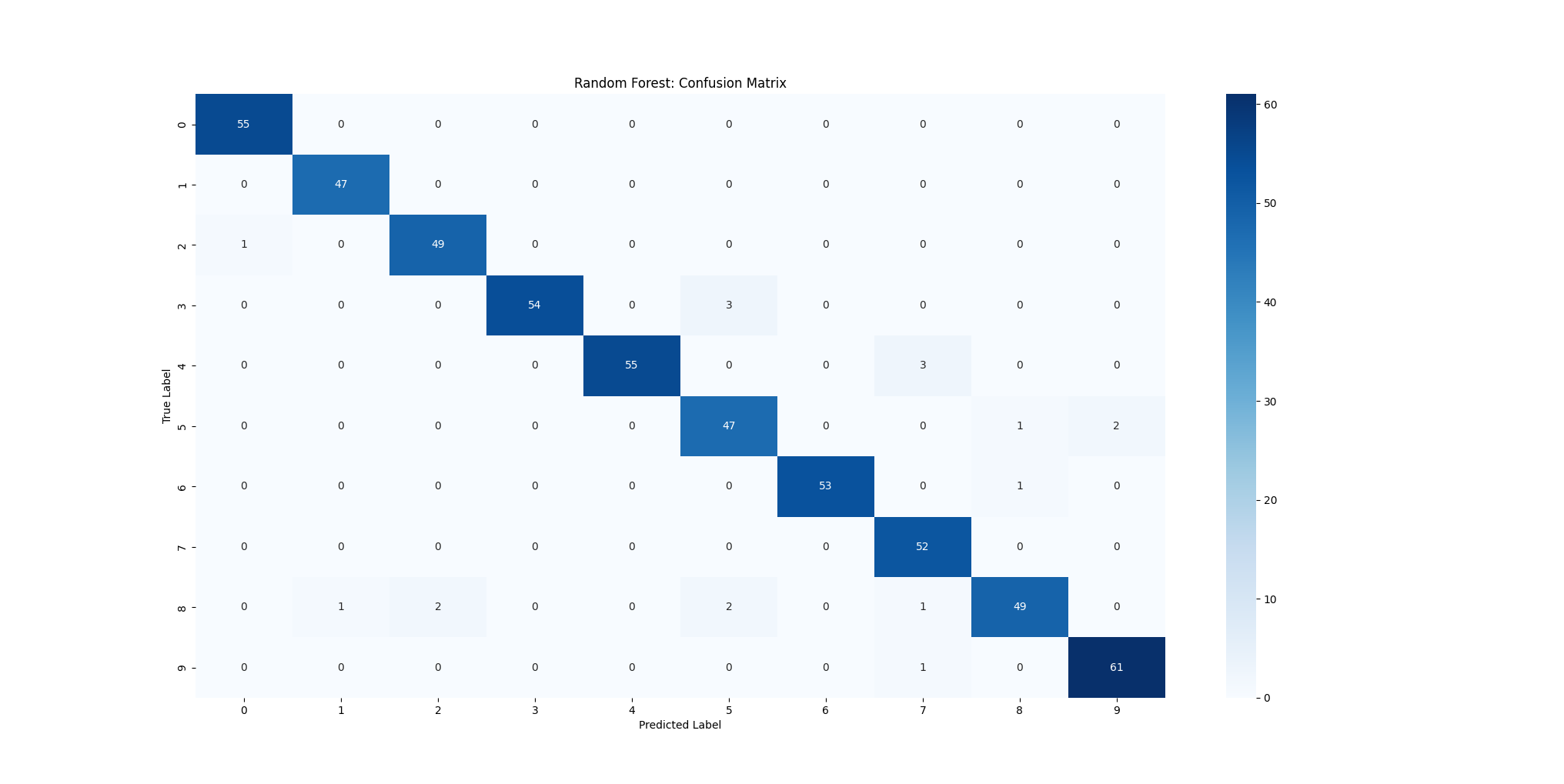
下面通过 SKlearn 提供的随机森林分类器来实现一个多分类任务。这里选用经典的 Digits Dataset 手写数字数据集。该数据集包含1797张手写数字的灰度图片(8×8 像素),每张图片的特征数为64个(以每个像素点的灰度值作为特征),目标是识别图片中手写的数字0~9
1 | from sklearn.datasets import load_digits |
输出结果如下
1 | ------------------------ 评估指标 ------------------------ |
特点
优点
- 准确性高、泛化性好
- 采用随机样本、随机特征的机制,使得模型整体上不易过拟合
- 得益于随机特征的机制,使得模型可以处理高维的原始特征
- 训练速度快,可以同时并行训练随机森林中的多个决策树
缺点
- 随机森林由多个决策树组成,模型整体上较为复杂,可解释性较差
- 由于需要存储多个决策树,存储资源占用较大。特别在树的数量很多、树的深度很深的情况下
- 由于需要多个决策树分别进行预测, 预测速度较慢
参考文献
- 机器学习 周志华著
- 机器学习公式详解 谢文睿、秦州著
- 图解机器学习和深度学习入门 山口达辉、松田洋之著
