很多编程语言中都有 volatile 关键字,但是不同语言下其语义并不完全相同。本文将就其在Java中的语义作具体说明、解释

Visibility 可见性
很多人对volatile关键字的基本理解是每次读取该关键字所修饰的变量时,可以保证能够获取到其在内存中最新的值。首先说明这个理解并没有错,其说明了volatile具有可见性。下面我们通过一个例子来验证volatile的可见性。下面的代码中,我们定义了一个普通的共享变量isLoop用于控制线程A的while循环。我们期望当其被线程B修改为false时,线程A跳出while循环
1 | public class VolatileTest { |
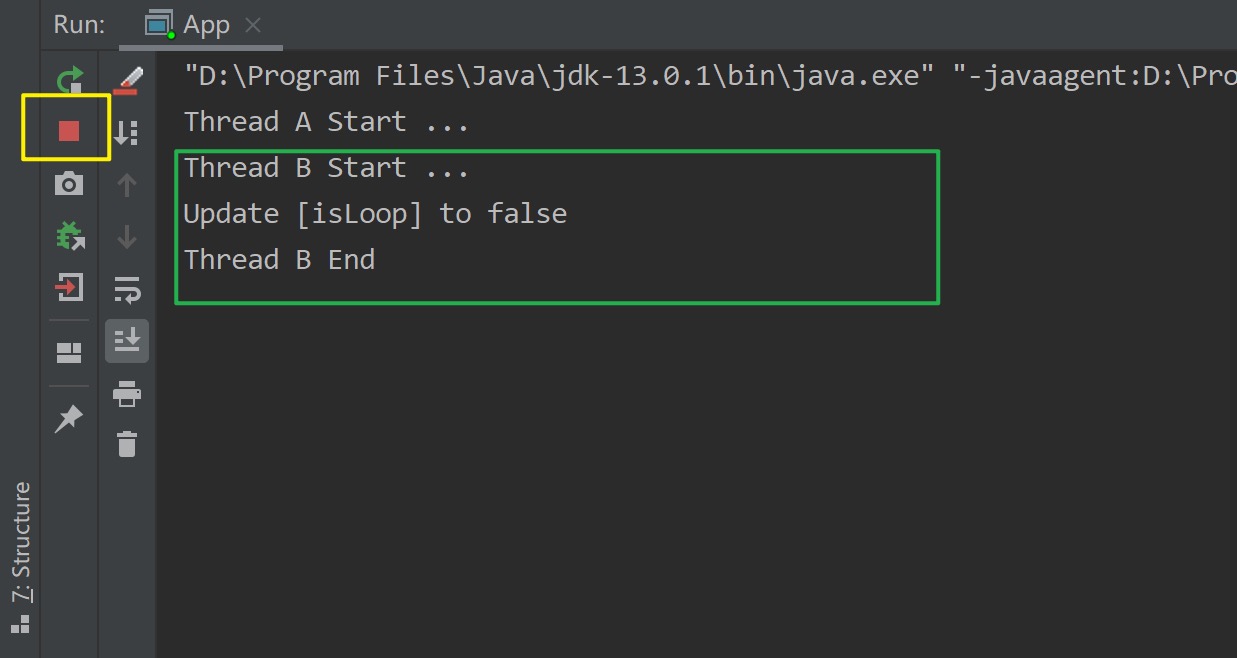
现在,我们来实际验证下这个代码的效果。可以看到线程B虽然将isLoop修改为false了,但是从下图黄框我们可以发现,线程A依然处于While循环中没有结束。显然这里与我们的预期期望并不相符。其实原因也很简单,我们知道JMM要求,线程不可以直接操作主内存中的共享变量,其需要拷贝共享变量的副本至线程的工作内存中才能使用。在这里的示例代码中,虽然线程B将其工作内存中的共享变量isLoop副本的值修改为false了,但是并没有立即同步到主内存中。换句话说主内存中共享变量isLoop的值依然是true
如果要求测试结果符合我们的预期,也很简单,只需使用volatile关键字修饰isLoop变量
1 | // 共享变量,判定是否继续循环 |
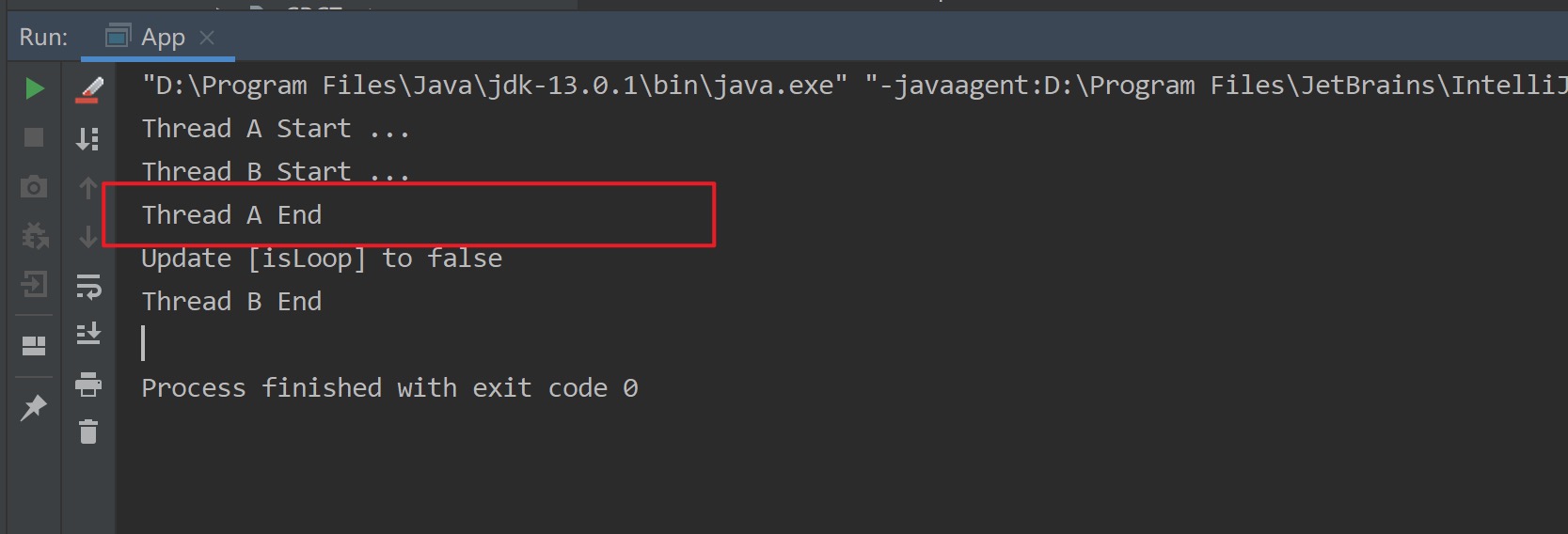
从修改后程序的测试结果,我们可以得出一个结论,当线程B将共享变量修改为false后,线程A能够立刻感知到其他线程对该变量所做的修改。即volatile具备可见性
前面我们是通过程序的现象了解了volatile关键字的可见性,现在我们来具体看看Java底层是如何实现的,这里我们借助HSDIS进行反汇编并通过JITWatch工具进行可视化分析
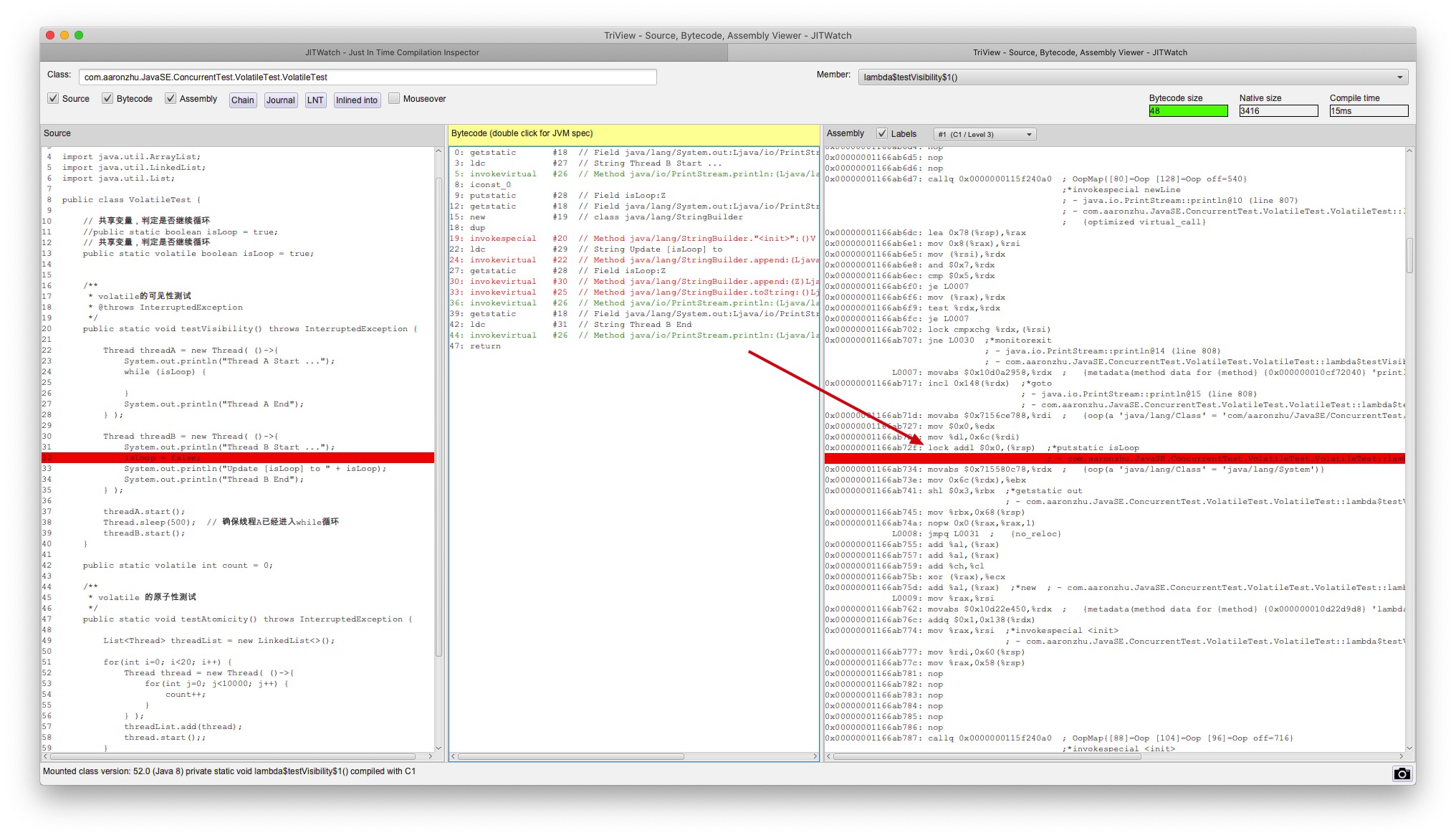
可以看到线程B在修改了共享变量后,在汇编指令中插入了一条lock前缀指令。根据Intel手册对lock指令的解释,其作用如下:
- 会将当前处理器Cache中的数据立即回写到Ram中。在此过程中,CPU会适当地选取总线加锁或缓存锁等形式来保证该过程不会被打断
- 该数据的回写操作同时会引起其他处理器Cache中相应数据的缓存无效(MESI协议)
- 强制要求lock指令之前的操作都必须在此之前执行完成、lock指令之后的操作都必须在此之后执行。因此该指令虽然不是内存屏障,但其却具有该语义,相当于是一个内存屏障
现在我们就可以很好的解释volatile关键字的可见性了。当线程B工作内存中的共享变量isLoop副本被修改后会立即刷新回主内存,即主内存中共享变量isLoop的值被更新为false。与此同时对于线程A而言,虽然其工作内存中已经有了共享变量isLoop的副本,但是由于volatile关键字的作用,会使得其每次进行while循环判定时,都会从主内存中重新拷贝共享变量isLoop的副本,而不会使用工作内存中之前的旧副本(旧副本数据已经失效,不可用)。所以说volatile关键字的所修饰共享变量,一方面可以保证共享变量的更新、修改能够立即被同步回主内存中,另一方面可以保证每次都是从主内存中读取该共享变量的最新值,而不是使用其工作内存中已有的副本数据
Atomicity 原子性
既然volatile具备可见性,那是不是就是说其在并发下就是安全的呢?现在我们先来看一个例子
1 | public class VolatileTest { |
其意图很简单,启动20个线程,每个线程分别对共享变量count进行1万次自增操作。我们期望这20个线程完成自增任务后,共享变量的值最终应该是20万(20*10000=200000)。现在让我们来看下实际的测试结果,发现count值远小于20万。实际上该程序不论测试执行多少次基本都会小于20万
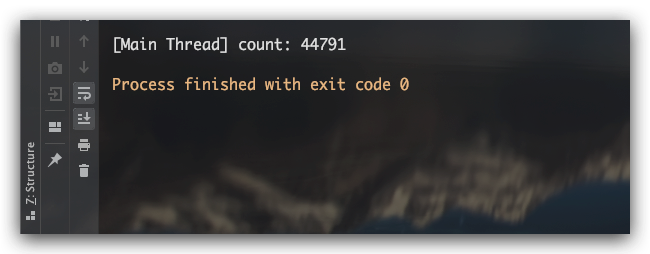
咦,之前明明不是说volatile具备可见性么?线程每次进行count++自增时,应该都是获取到主内存中共享变量count的最新值进行操作的啊,为什么实际测试结果总是比预期小呢?这里我们依然通过反汇编来进行分析、解释
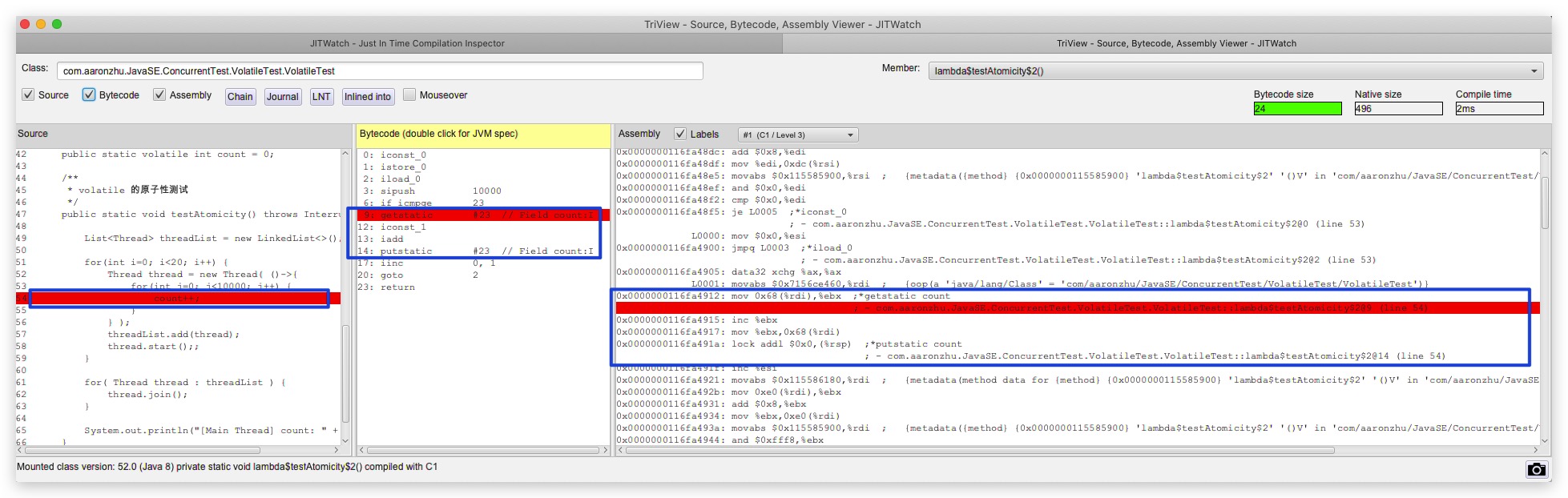
可以看到虽然在Java代码中count++只是一行代码,但是实际上转化为字节码、汇编后却是多条指令。当线程1先从主内存中拷贝共享变量count最新值(假设此时为10)到其工作内存后。正当CPU准备执行自增操作时。可能另外一个线程(记为线程2)已经完成了共享变量的自增操作,并将更新后的值11写入到主内存中去了。此时线程1中count值却依然还是10(因为线程1已经完成了共享变量count的加载拷贝操作,故并不会重新从主内存中拷贝共享变量count最新值11),当其执行完自增操作变为11后并回写到主内存。可以看到,虽然线程1、2分别完成了一次自增操作,但count却并没有加2只加了1。其原因就在于volatile不具备原子性,当线程1从主内存加载完count变量值后,本该立即执行的修改、赋值操作却被其他线程所打断,导致接下来修改、赋值操作所使用的数据是旧数据
由于volatile不具备原子性,所以我们使用时需要特别小心。一般地,如果 运算结果不依赖变量当前的值 或 确保只有一个线程修改变量 的场景下,才会使用volatile关键字
Ordering 有序性
而在JMM中,volatile同样具备有序性。具体地,其是通过插入内存屏障指令实现,其具体规则如下所示
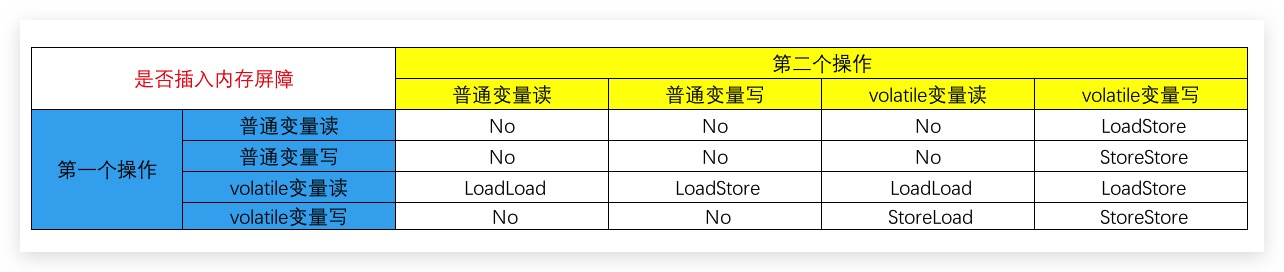
从上表我们可以看出:
- 当第一个操作是volatile变量读时,无论第二个操作是什么,均不允许重排序。即其保证了volatile变量读之后的操作不会被重排序到volatile变量读之前
- 当第二个操作是volatile变量写时,无论第一个操作是什么,均不允许重排序。即其保证了volatile变量写之前的操作不会被重排序到volatile变量写之后
- 当第一个操作是volatile变量写、第二个操作是volatile变量读时,不允许重排序
在JDK1.5之前的Java内存模型中,虽然不允许volatile变量之间进行重排序,但却允许普通变量与volatile变量之间的重排序。所以在JSR 133中对volatile变量的内存语义进一步增强,即限制了普通变量与volatile变量之间是否可以重排序的具体场景。这也是为什么在JDK 1.5之前无法通过DCL(Double-checked locking, 双锁检查锁)实现一个线程安全的单例模式
1 | public class Singleton { |
在 instance = new Singleton() 过程中,其大致可分为三步:
- 分配内存空间
- 通过构造器进行对象初始化
- 将volatile变量instance指向相应的内存空间
按理说正常的执行顺序应该是1->2->3,但是在JDK 1.5之前,2和3可能会发生重排序,即可能出现1->3->2这样的执行顺序。当线程A按此顺序(1->3->2)执行完成3(此时instance不为null了)正准备执行2时,恰好此时另外一个线程B调用了Singleton.getInstance() 方法,由于此时instance已经不为null了,线程B就会拿到一个未进行初始化的对象,从而引发了错误,即所谓的安全发布失败。而在JSR 133中,Java内存模型对volatile变量与普通变量之间重排序的规则进行了完善,故可以保证在JDK 1.5及其之后的版本中,2和3不会发生重排序。即保证了基于DCL的单例模式是线程安全的
参考文献
- Java并发编程之美 翟陆续、薛宾田著
- 深入理解Java虚拟机·第2版 周志明著
- JSR-133: Java Memory Model and Thread Specification
