这里介绍SQL中的窗口函数Window Function

概述
窗口函数是一种可以对查询结果集中的一组行记录进行计算的函数。与GROUPBY子句相比,其提供了在不破坏查询结果原始行的前提下执行聚合、排序、排名等操作的能力
窗口函数的语法规则如下所示
1 | -- 用法1 |
使用窗口函数时,OVER子句是必须存在的,不可以省略。例如用法1。同时在OVER子句中,我们可以可选地使用PARTITION BY子句、ORDER BY子句、ROWS/RANGE子句。例如用法2。具体地:
- PARTITION BY子句:其定义了窗口函数的分区方式。它指定了窗口函数的作用范围,即所谓的窗口大小。窗口函数将在每个分区内进行计算
- ORDER BY子句:其定义窗口函数在计算前,窗口中各条记录的的排序顺序
- ROWS/RANGE子句:其定义了开窗范围
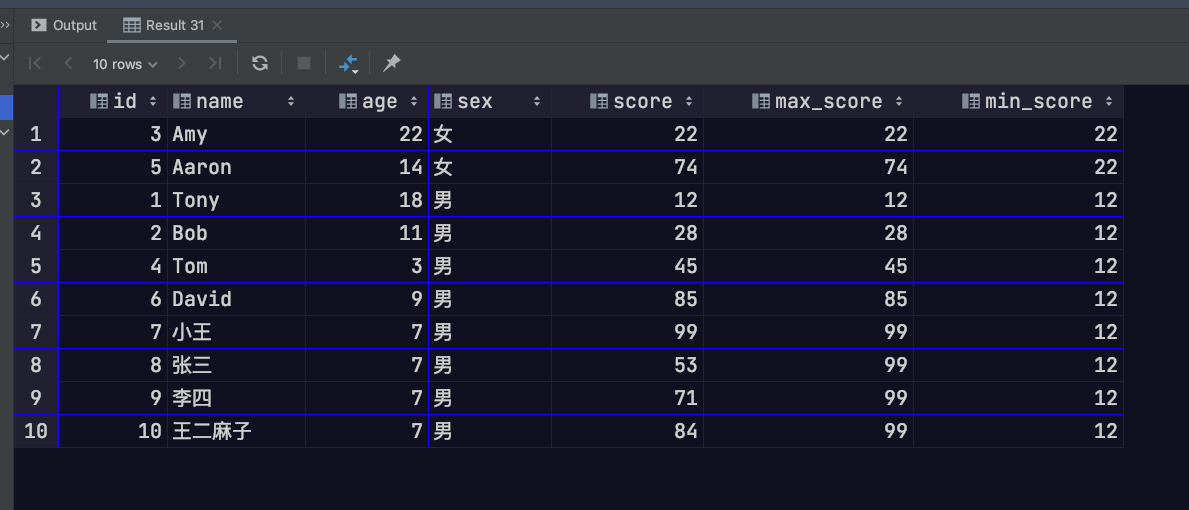
建表语句
这里建立一张表,以供后续测试
1 | CREATE TABLE `stu_info` ( |
常用窗口函数
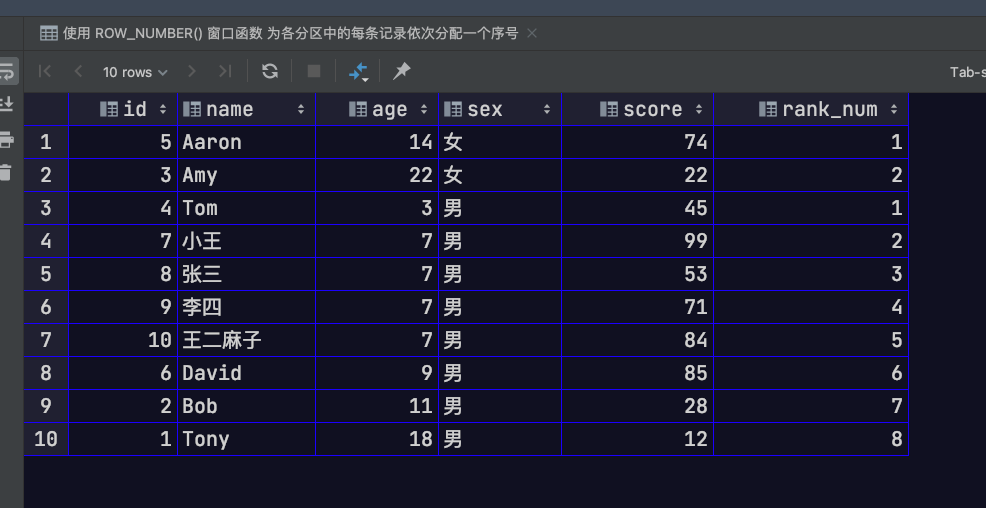
ROW_NUMBER 函数
其会为窗口中每一个行记录分配一个唯一的序号。这个序号是根据窗口中记录的排序顺序进行分配的。从1开始、依次递增。这里,我们期望对每个性别而言,按年龄大小顺序进行排名
1 | -- 通过 PARTITION BY sex 子句 实现 将记录按性别进行分区 |
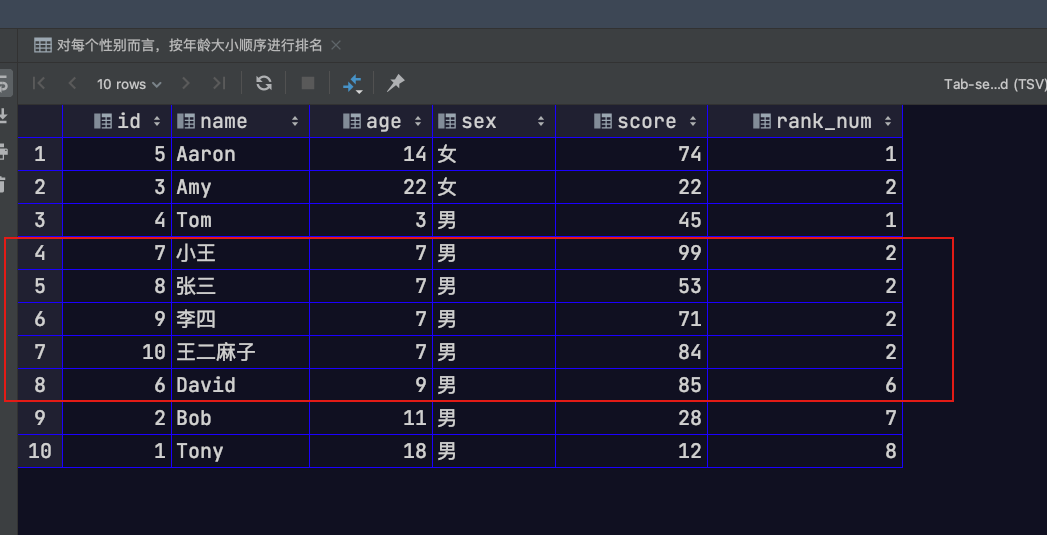
RANK 函数
其会为窗口中每一个行记录分配一个排名。但与ROW_NUMBER函数不同的是,对于相同数值会有相同排名,并且下一个排名值会跳过相应数量的排名
1 | -- 对每个性别而言,按年龄大小顺序进行排名 |
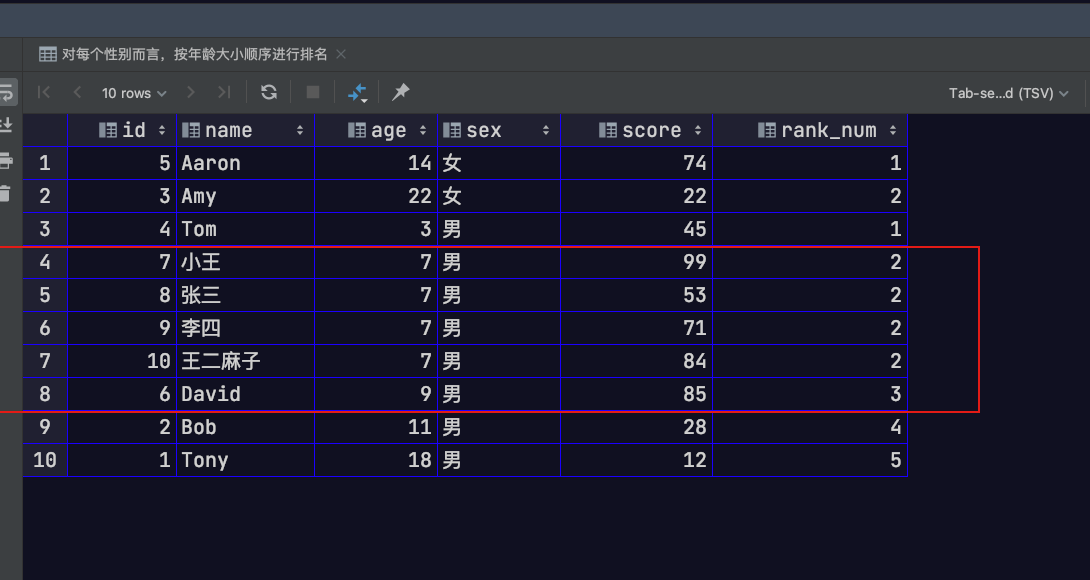
DENSE_RANK 函数
其会为窗口中每一个行记录分配一个排名。虽然对于相同数值会有相同排名,但与RANK函数不同的是,下一个排名值不会跳过相应数量的排名
1 | -- 对每个性别而言,按年龄大小顺序进行排名 |
FIRST_VALUE/LAST_VALUE 函数
FIRST_VALUE/LAST_VALUE函数 会返回窗口中第一行/最后一行的指定字段的值。但需要注意的是,LAST_VALUE 函数的结果会受到开窗范围的影响
1 | -- 对每个性别而言,按分数大小升序排序。获取相应性别下分数最低、最高人的姓名 |
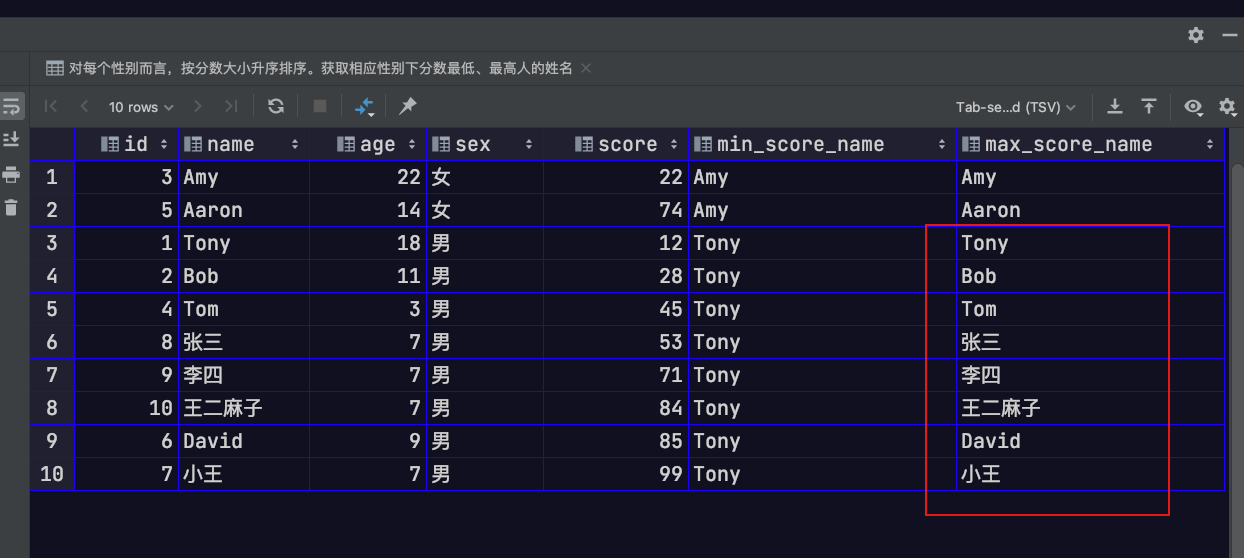
LAG/LEAD 函数
LAG/LEAD(<指定字段名>, n, default)函数:可用来获取当前行的前n行/后n行的指定字段的值。其中,default参数表示没有可用的行取不到值时返回的默认值
1 | SELECT |
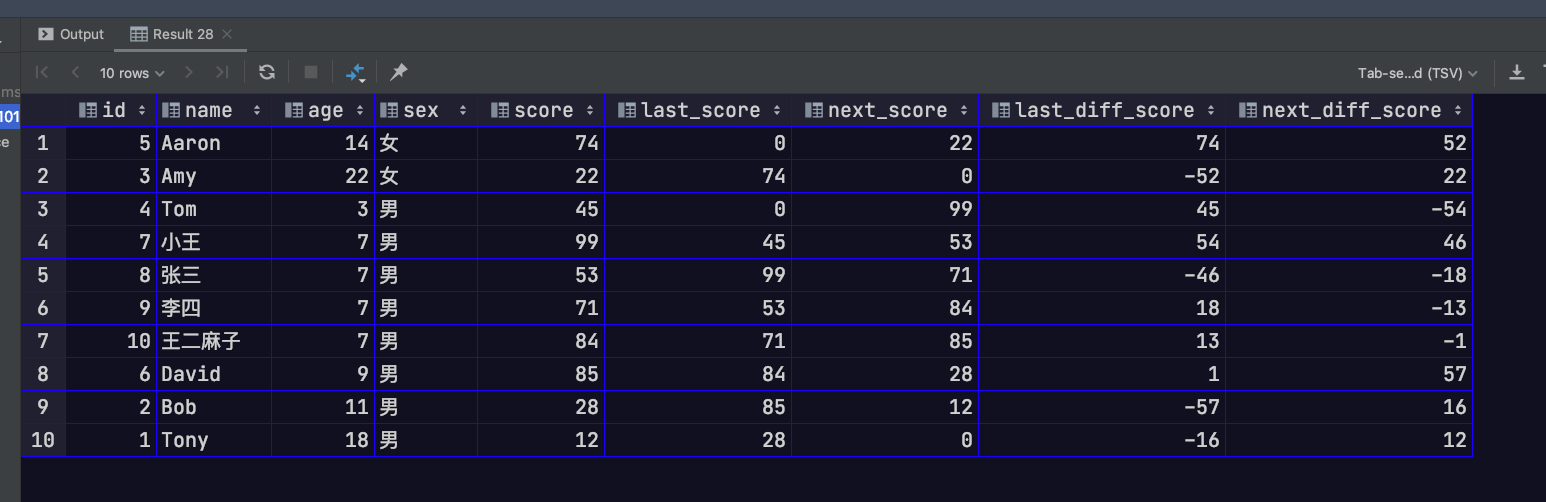
开窗范围
ROWS 子句
ROWS 子句是基于分区中的物理行数来定义开窗范围。其中,行数的表示法如下:
- CURRENT ROW:ROWS子句下,指分区中的当前行
- UNBOUNDED PRECEDING:ROWS子句下,指分区中的第一行
- UNBOUNDED FOLLOWING:ROWS子句下,指分区中的最后一行
- [num] PRECEDING:ROWS子句下,表示当前行的前num行
- [num] FOLLOWING:ROWS子句下,表示当前行的后num行
完整的ROWS子句,可以使用下述两种写法
1 | -- 表示开窗范围为:指定的开始行 到当前行 |
示例如下所示
1 | -- ROWS 开窗范围 |
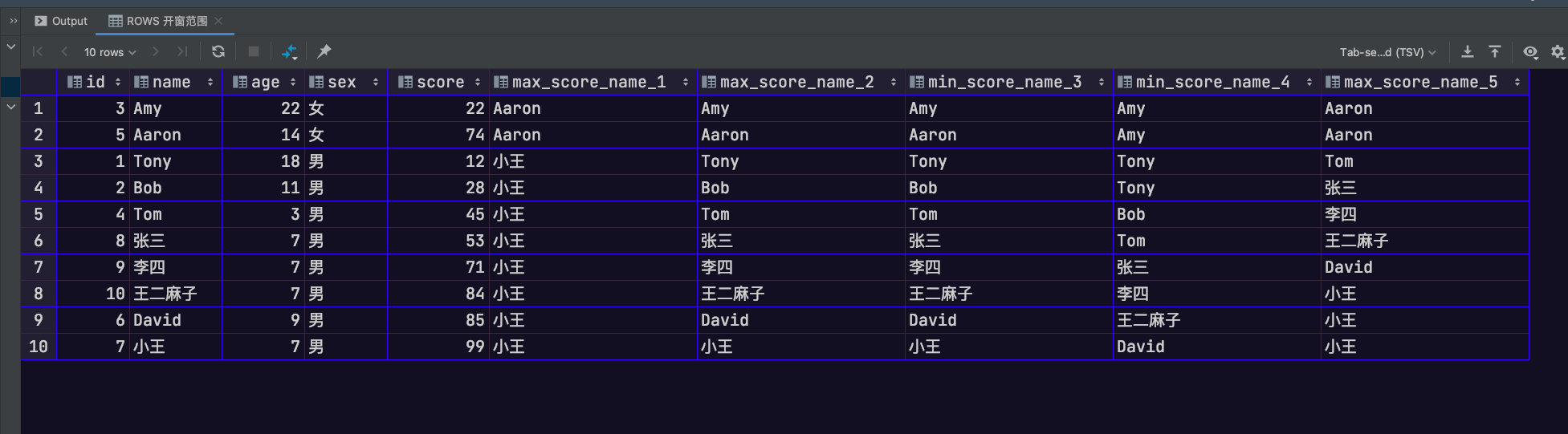
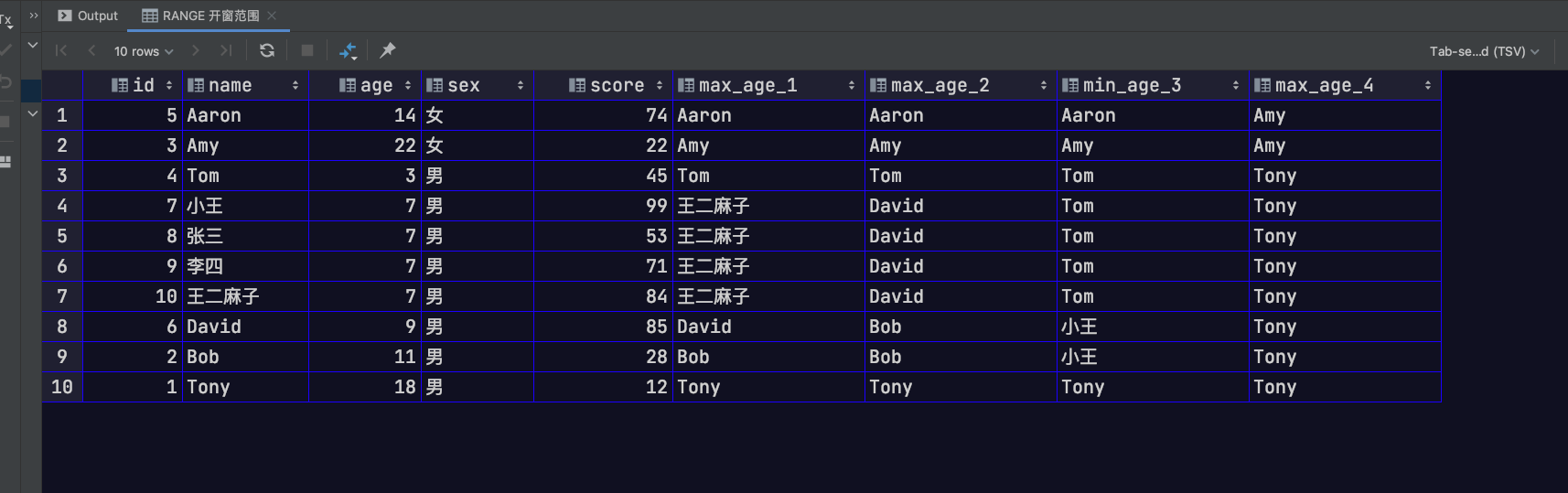
RANGE 子句
RANGE 子句是基于分区中的排序字段的值来定义开窗范围。值的表示法如下:
- CURRENT ROW:RANGE子句下,指分区中的当前行的排序字段的值
- UNBOUNDED PRECEDING:RANGE子句下,指分区中的第一行的排序字段的值
- UNBOUNDED FOLLOWING:RANGE子句下,指分区中的最后一行的排序字段的值
- [num] PRECEDIN:RANGE子句下,表示分区中的当前行的排序字段的值 减去 num后的值
- [num] FOLLOWING:RANGE子句下,表示分区中的当前行的排序字段的值 加上 num后的值
- INTERVAL [num] [时间单位] PRECEDING:对于排序字段为时间类型时,可以使用该语法表示分区中的当前行的排序字段的时间值 减去 num [时间单位]的时间值。例如,INTERVAL 2 DAY PRECEDING 表示当前行的排序字段对应时间值的前2天
- INTERVAL [num] [时间单位] FOLLOWING:对于排序字段为时间类型时,可以使用该语法表示分区中的当前行的排序字段的时间值 加上 num [时间单位]的时间值。例如,INTERVAL 3 HOUR FOLLOWING 表示当前行的排序字段对应时间值的下3个小时
完整的RANGE子句,可以使用下述两种写法
1 | -- 表示开窗范围为:排序字段的值从 指定的起始值 到 当前行排序字段对应的值 |
示例如下
1 | SELECT |
聚合函数
事实上,除了专用的窗口函数。聚合函数也可作为窗口函数进行使用
1 | SELECT |