… If an index is not used for ORDER BY but a LIMIT clause is also present, the optimizer may be able to avoid using a merge file and sort the rows in memory using an in-memory filesort operation. If multiple rows have identical values in the ORDER BY columns, the server is free to return those rows in any order, and may do so differently depending on the overall execution plan. In other words, the sort order of those rows is nondeterministic with respect to the nonordered columns. …
while i < count do set my_first_name = gen_str(rand()*3+1, names); set my_last_name = gen_str( 1, names); set my_nation = gen_str(1, nations); set my_age =ceil( rand()*100 ); if rand() <0.5then set my_sex ='男'; else set my_sex ='女'; end if; set my_iphone =cast( ceil(rand()*100000000000) aschar ); set my_birthday = concat( floor(rand()*100+1900), '-', floor(rand()*11+1) );
insertinto stu_info(first_name, last_name, nation, age, sex, iphone, birthday) values(my_first_name, my_last_name, my_nation, my_age, my_sex, my_iphone, my_birthday); set i = i+1; end while; end // delimiter ;
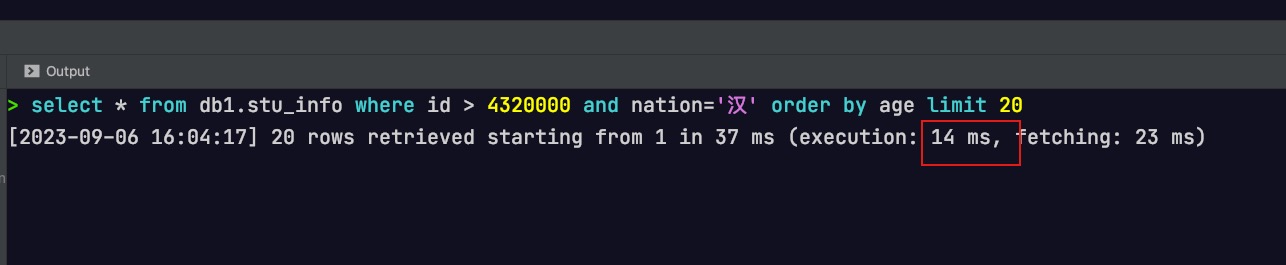
-- 需要支持业务排序(按 nation 排序) select*from db1.stu_info where id >4320000orderby nation, id limit 20;
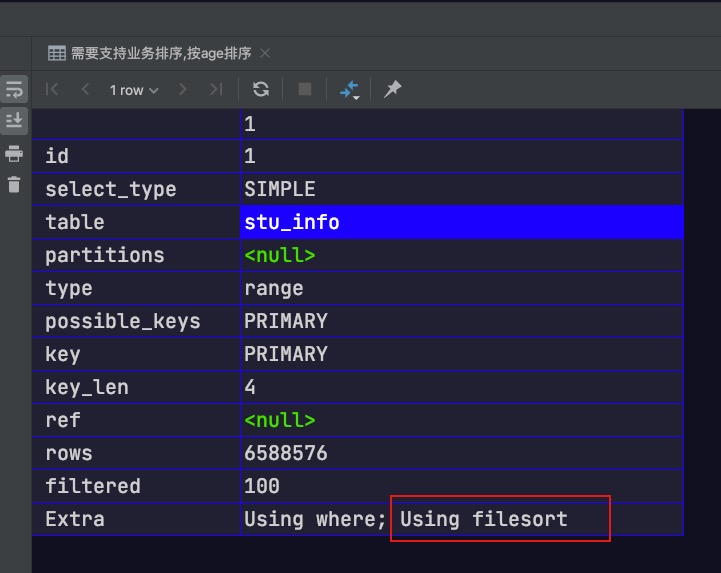
-- 需要支持业务排序(依次按 nation、age 排序) select*from db1.stu_info where id >4320000orderby nation, age, id limit 20;
查询效率如下所示,第一个SQL相对于第二个SQL来说慢很多
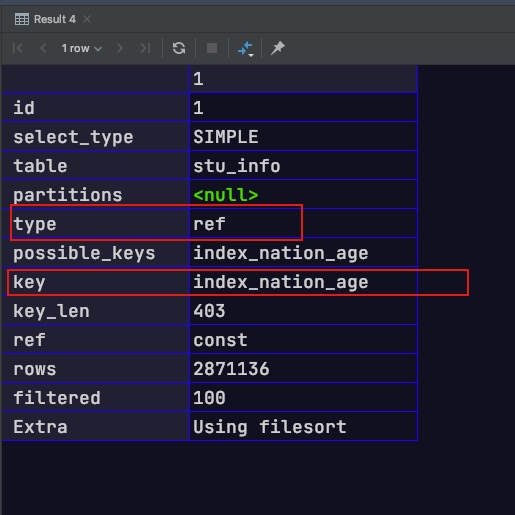
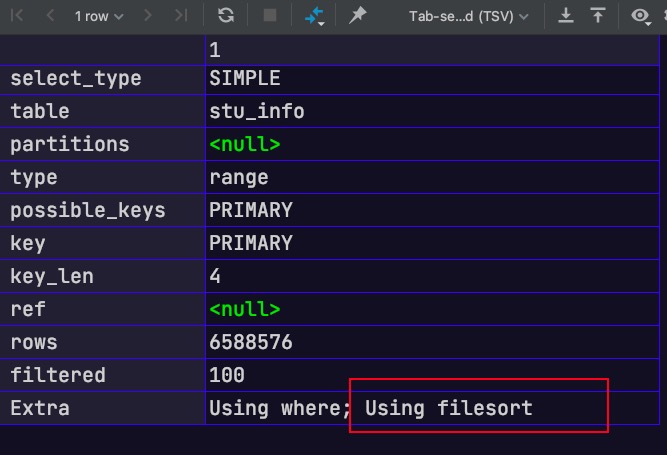
查看第一个SQL的执行计划可以发现,其未使用二级索引index_nation_age进行排序,而是通过filesort进行排序的。究其本质,当二级索引中各索引字段均相同时,其会按主键进行排序。故对于第一个SQL中的排序条件(order by nation, id)来说,是不满足最左匹配原则的;而对于第二个SQL中的排序条件(order by nation, age, id)来说,是满足最左匹配原则的,可以充分利用二级索引实现排序
1
explain select*from db1.stu_info where id >4320000orderby nation, id limit 20;
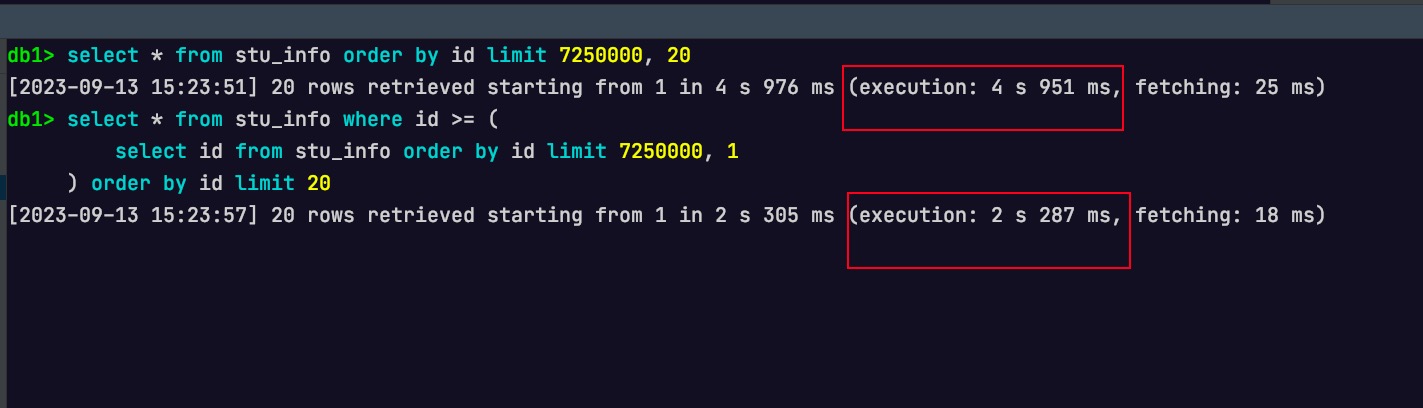
select*from stu_info orderby id limit 7250000, 20;
-- 基于子查询的深分页优化 select*from stu_info where id >= ( select id from stu_info orderby id limit 7250000, 1 ) orderby id limit 20;
效果如下所示
而对于如下的深分页sql
1
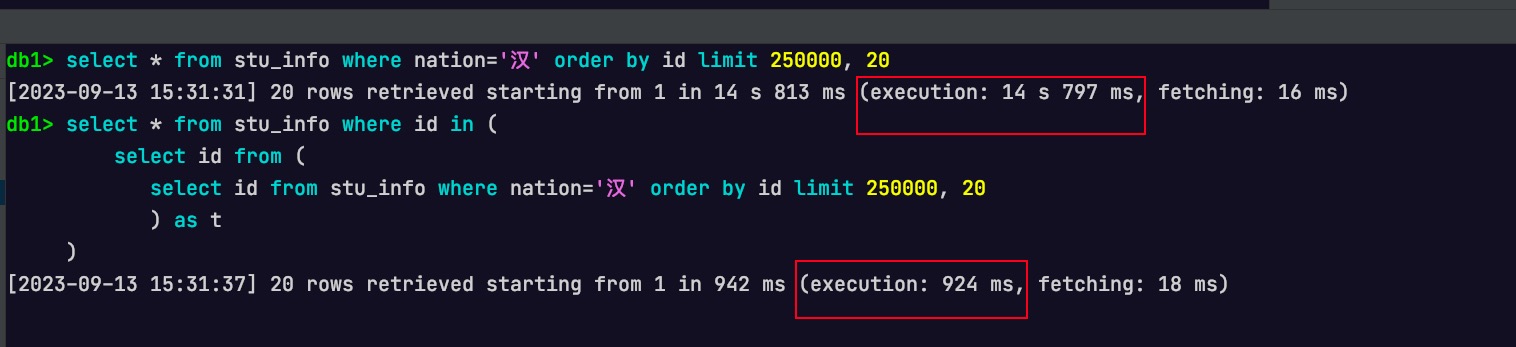
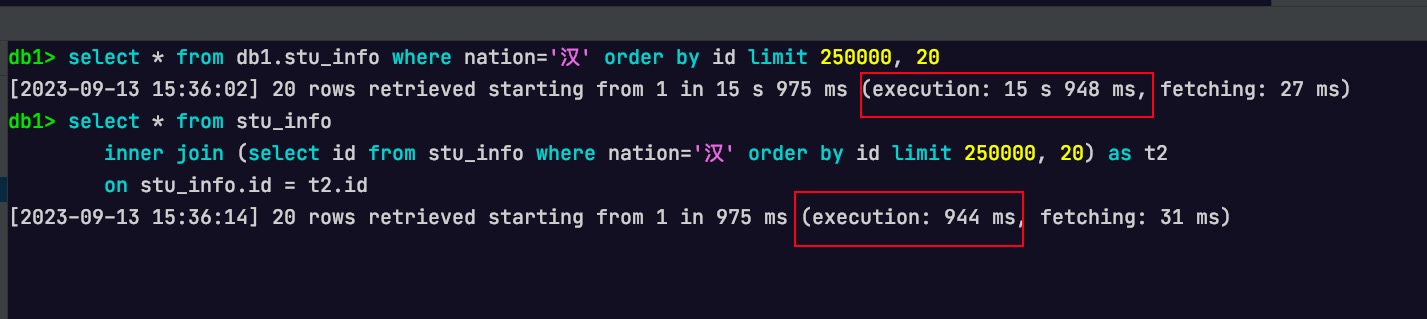
select*from stu_info where nation='汉'orderby id limit 250000, 20;
如果期望用子查询方式进行优化,会得到下述sql
1 2 3
select*from stu_info where id in ( select id from stu_info where nation='汉'orderby id limit 250000, 20 );
但不幸地是上述sql执行会报错:This version of MySQL doesn’t yet support ‘LIMIT & IN/ALL/ANY/SOME subquery’。即,在MySQL 8.0版本中不支持在子查询中使用limit语句。解决办法也很简单。只需在limit的子查询外层再加一层子查询即可,如下所示
1 2 3 4 5 6
-- 基于子查询的深分页优化 select*from stu_info where id in ( select id from ( select id from stu_info where nation='汉'orderby id limit 250000, 20 ) as t );