本文对PostgreSQL 11中声明式分区表进行实践
概述 在PostgreSQL 10之前,需要使用继承的方式来实现分区表,即所谓的继承式分区表 。从PostgreSQL 10开始,引入了声明式分区表 。支持Range、List两种分区方式。而在PostgreSQL 11中,声明式分区表的功能得到进一步增强。提供了对Hash分区的支持
Range范围分区 所谓范围分区,指的是根据分区键的值将记录存储到符合范围的分区表中。这里我们先建立使用范围分区的stu_info父表。其中,分区键为age字段
1 2 3 4 5 6 7 create table stu_info ( id int not null , name varchar (100 ) null , age int not null , primary key (id,age) ) partition by range (age);
然后建立下述3张分区表。其中,MINVALUE、MAXVALUE 分别表示无限小值、无限大值。需要注意的是对于 from (18) to (60) 这样范围描述而言,该范围包含了临界值18,但不包含临界值60
1 2 3 4 5 6 7 8 9 10 create table stu_info_young partition of stu_info for values from (MINVALUE) to (18 );create table stu_info_middle partition of stu_info for values from (18 ) to (60 );create table stu_info_old partition of stu_info for values from (60 ) to (MAXVALUE);
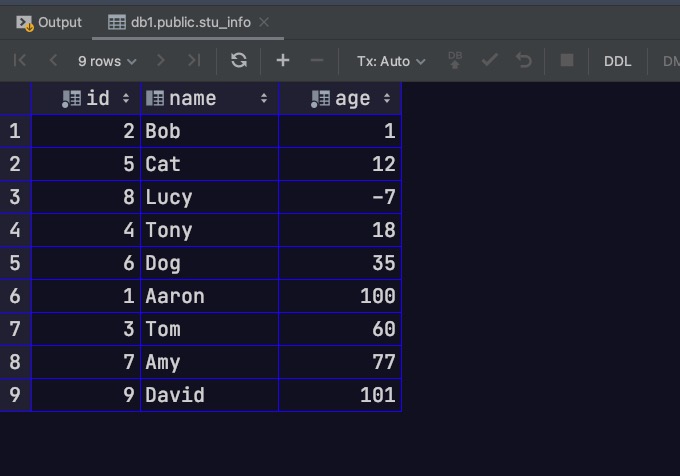
现在我们直接向父表插入数据
1 2 3 4 5 6 7 8 9 10 insert into stu_info(id, name, age) values (1 , 'Aaron' , 100 );insert into stu_info(id, name, age) values (2 , 'Bob' , 1 );insert into stu_info(id, name, age) values (3 , 'Tom' , 60 );insert into stu_info(id, name, age) values (4 , 'Tony' , 18 );insert into stu_info(id, name, age) values (5 , 'Cat' , 12 );insert into stu_info(id, name, age) values (6 , 'Dog' , 35 );insert into stu_info(id, name, age) values (7 , 'Amy' , 77 );insert into stu_info(id, name, age) values (8 , 'Lucy' , -7 );insert into stu_info(id, name, age) values (9 , 'David' , 101 );
此时,直接访问父表。可以发现我们能够同时看到分区表中的数据
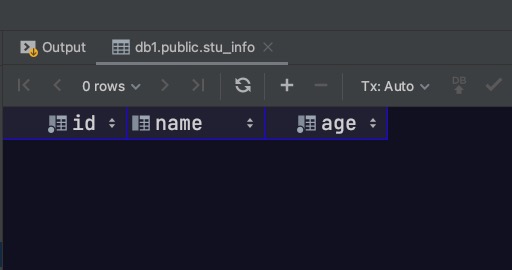
通过添加only关键字,可以实现只查看父表中的数据,而不查看分区表中的数据
1 2 select * from only stu_info;
此时会发现查询结果为空。因为记录是存储到各分区表当中,而不是直接存储到父表中的
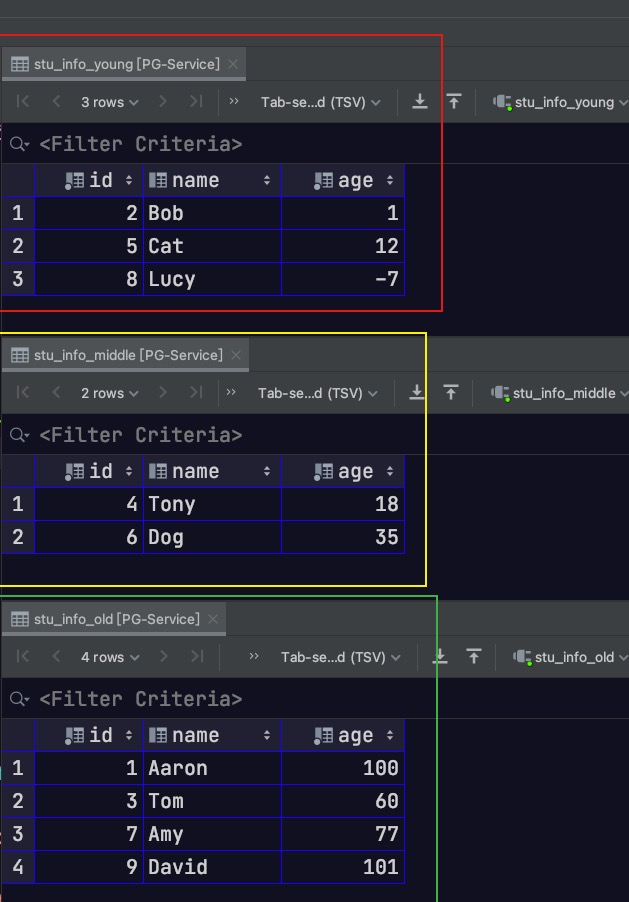
当然我们也可以直接访问各分区表,如下所示
1 2 3 4 5 select * from stu_info_young;select * from stu_info_middle;select * from stu_info_old;
List列表分区 所谓列表分区,指的是根据分区键的值将记录存储到符合枚举值列表的分区表中。这里我们先建立使用列表分区的goods_info父表。其中,分区键为type字段
1 2 3 4 5 6 7 8 create table goods_info ( id int not null , name varchar (100 ) null , price double precision null , type varchar (100 ) null , primary key (id,type) ) partition by list (type);
然后建立下述3张分区表。此外,在PostgreSQL 11中,提供了default默认分区的支持。用于存储无法匹配任何分区的数据
1 2 3 4 5 6 7 8 9 10 create table goods_info_3c partition of goods_info for values in ('phone' , 'pc' );create table goods_info_food partition of goods_info for values in ('fruits' , 'meat' );create table goods_info_other partition of goods_info default ;
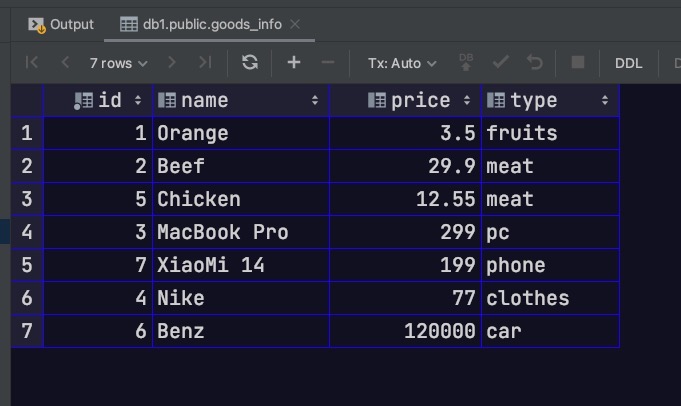
现在我们直接向父表插入数据
1 2 3 4 5 6 7 8 insert into goods_info(id, name, price, type) VALUES (1 , 'Orange' , '3.5' , 'fruits' );insert into goods_info(id, name, price, type) VALUES (2 , 'Beef' , '29.9' , 'meat' );insert into goods_info(id, name, price, type) VALUES (3 , 'MacBook Pro' , '299' , 'pc' );insert into goods_info(id, name, price, type) VALUES (4 , 'Nike' , '77' , 'clothes' );insert into goods_info(id, name, price, type) VALUES (5 , 'Chicken' , '12.55' , 'meat' );insert into goods_info(id, name, price, type) VALUES (6 , 'Benz' , '120000' , 'car' );insert into goods_info(id, name, price, type) VALUES (7 , 'XiaoMi 14' , '199' , 'phone' );
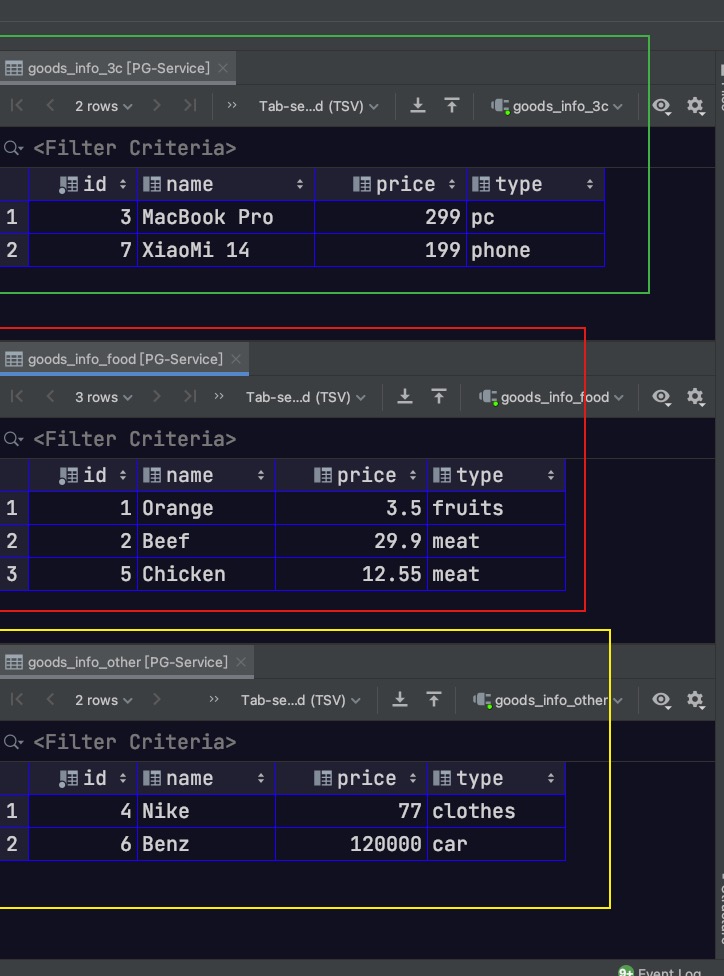
此时,直接访问父表。可以发现我们能够同时看到分区表中的数据。同理,如果通过添加only关键字,可以实现只查看父表中的数据,而不查看分区表中的数据。此时会发现查询结果为空。因为记录是存储到各分区表当中,而不是直接存储到父表中的
1 select * from goods_info;
当然我们也可以直接访问各分区表,如下所示
1 2 3 4 5 select * from goods_info_3c;select * from goods_info_food;select * from goods_info_other;
Hash哈希分区 在PostgreSQL 11中分区方式增加了对Hash分区的支持。其是对分区键的值进行哈希、取模,然后根据余数存储到相应的分区表中。这里我们先建立使用哈希分区的country_code父表。其中,分区键为country_code字段
1 2 3 4 5 6 7 create table country_info ( id int not null , country varchar (100 ) null , country_code int null , primary key (id,country_code) ) partition by hash (country_code);
然后建立下述3张分区表
1 2 3 4 5 6 7 8 9 10 create table country_info_0 partition of country_info for values with (modulus 3 , remainder 0 );create table country_info_1 partition of country_info for values with (modulus 3 , remainder 1 );create table country_info_2 partition of country_info for values with (modulus 3 , remainder 2 );
现在我们直接向父表插入数据
1 2 3 4 5 6 7 8 insert into country_info(id, country, country_code) VALUES (3 , 'China' , 1 );insert into country_info(id, country, country_code) VALUES (6 , 'USA' , 3 );insert into country_info(id, country, country_code) VALUES (9 , 'UK' , 0 );insert into country_info(id, country, country_code) VALUES (12 , 'Russia' , 2 );insert into country_info(id, country, country_code) VALUES (15 , 'Canada' , 4 );insert into country_info(id, country, country_code) VALUES (18 , 'France' , 5 );insert into country_info(id, country, country_code) VALUES (21 , 'Japan' , 6 );
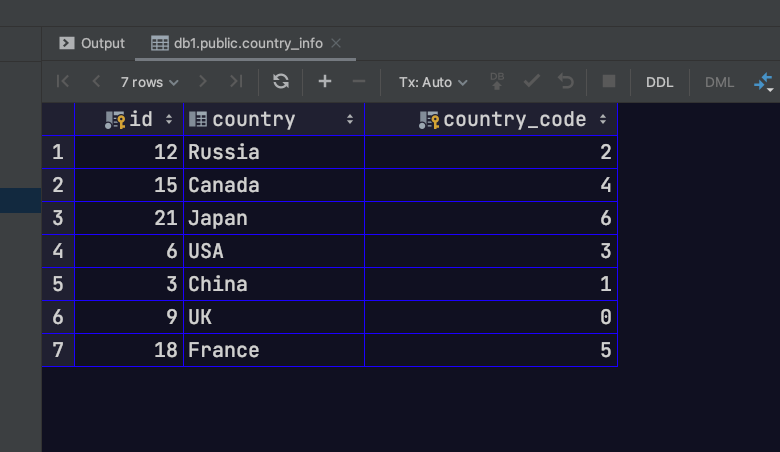
此时,直接访问父表。可以发现我们能够同时看到分区表中的数据。同理,如果通过添加only关键字,可以实现只查看父表中的数据,而不查看分区表中的数据。此时会发现查询结果为空。因为记录是存储到各分区表当中,而不是直接存储到父表中的
1 select * from country_info;
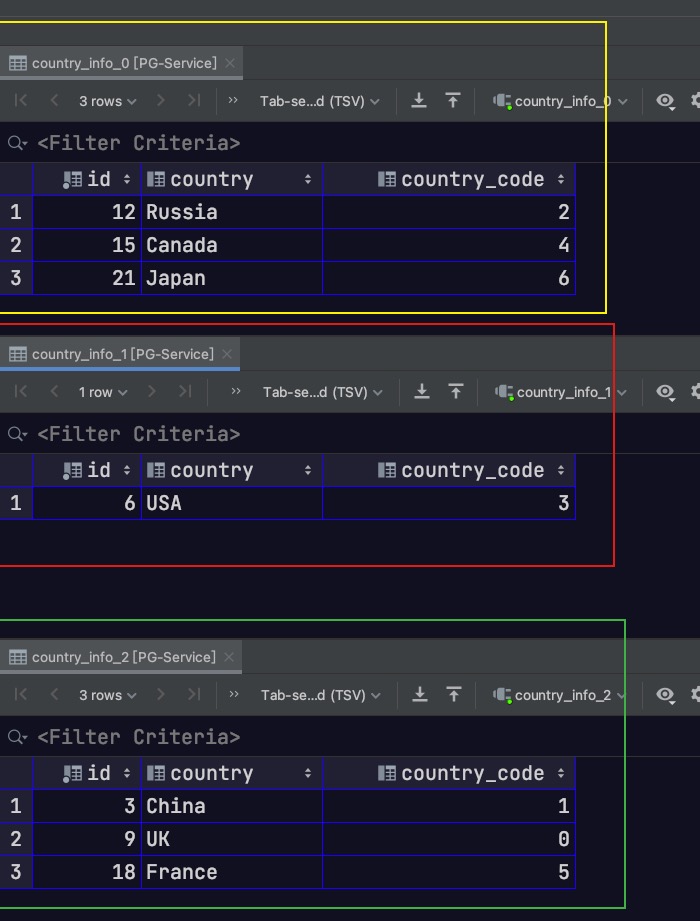
当然我们也可以直接访问各分区表,如下所示
1 2 3 4 5 select * from country_info_0;select * from country_info_1;select * from country_info_2;
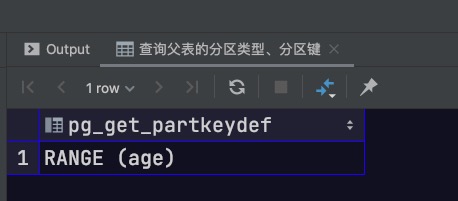
常用查询SQL 1. 查询父表的分区类型、分区键
1 2 select pg_get_partkeydef('stu_info' ::regclass);
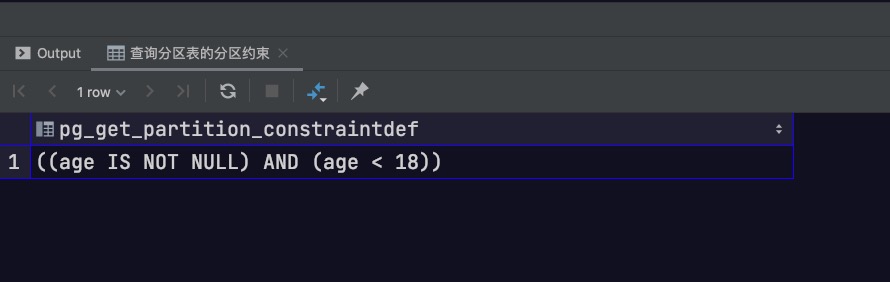
2. 查询分区表的分区约束
1 2 select pg_get_partition_constraintdef('stu_info_young' ::regclass);
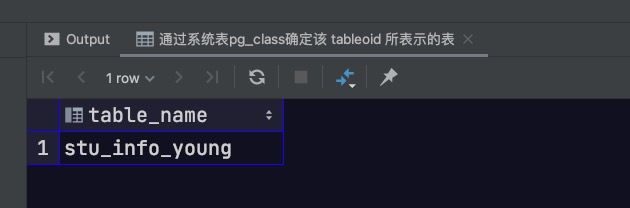
3. 定位记录实际所存储的分区表
相关SQL如下所示,定位父表stu_info中id为2的记录实际存储的分区表
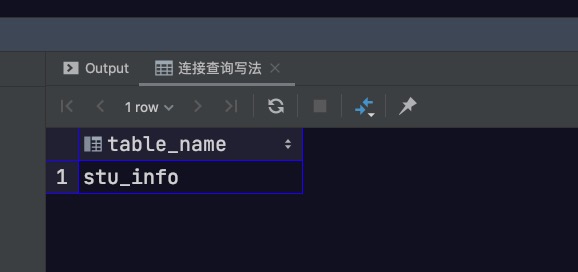
1 2 3 4 5 select relname as table_name from pg_catalog.pg_class where relfilenode = ( select tableoid from stu_info where id= 2 );
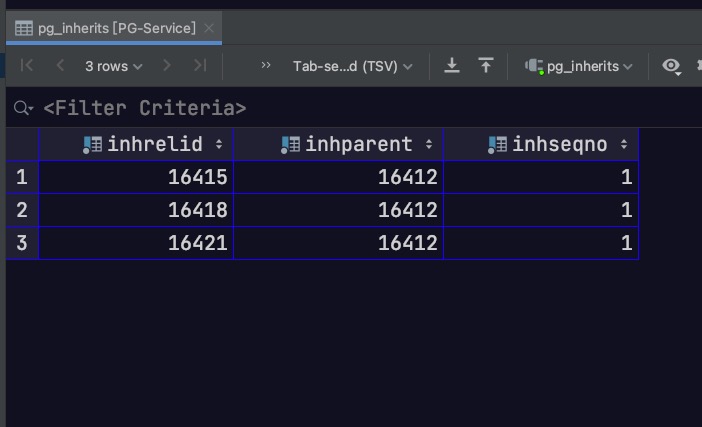
4. 查询分区表的所有父表
因为系统表 pg_catalog.pg_inherits 记录了父表、分区表间的关联关系。其中,inhrelid表示分区表的oid,inhparent表示父表的oid
故可通过下述sql进行查询,子查询写法如下
1 2 3 4 5 6 7 8 9 10 select relname as table_name from pg_catalog.pg_class where relfilenode in ( select inhparent from pg_catalog.pg_inherits where inhrelid in ( select relfilenode as tableoid from pg_catalog.pg_class where relname= 'stu_info_old' ) );
当然也可以使用连接查询,sql如下所示
1 2 3 4 5 6 7 8 9 select c2.relname as table_name from pg_catalog.pg_class c1 join pg_catalog.pg_inherits i on i.inhrelid = c1.relfilenode join pg_catalog.pg_class c2 on c2.relfilenode = i.inhparent where c1.relname = 'stu_info_old' ;
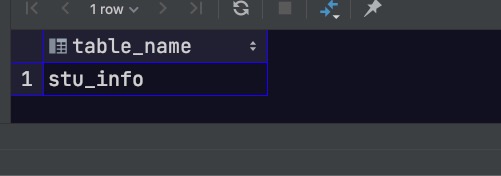
5. 查询父表下的分区表
可以利用如下sql通过子查询获得,sql如下所示
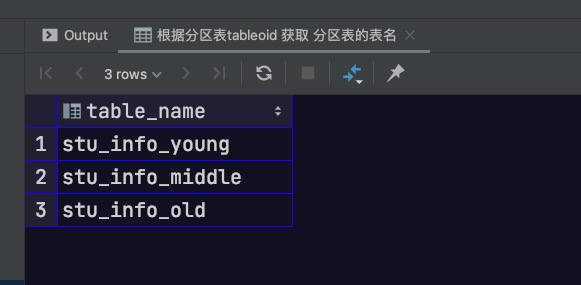
1 2 3 4 5 6 7 8 9 10 select relname as table_name from pg_catalog.pg_class where relfilenode in ( select inhrelid as tableid from pg_catalog.pg_inherits where inhparent in ( select relfilenode as tableoid from pg_catalog.pg_class where relname= 'stu_info' ) );
当然也可以使用连接查询,sql如下所示
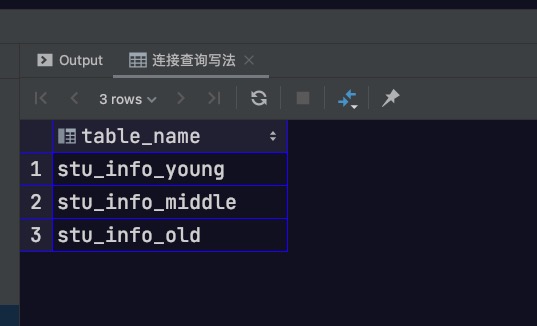
1 2 3 4 5 6 7 8 select c1.relname as table_name from pg_catalog.pg_class c1 join pg_catalog.pg_inherits i on i.inhrelid = c1.relfilenode join pg_catalog.pg_class c2 on c2.relfilenode = i.inhparent where c2.relname = 'stu_info' ;
6. 移除/添加 分区表
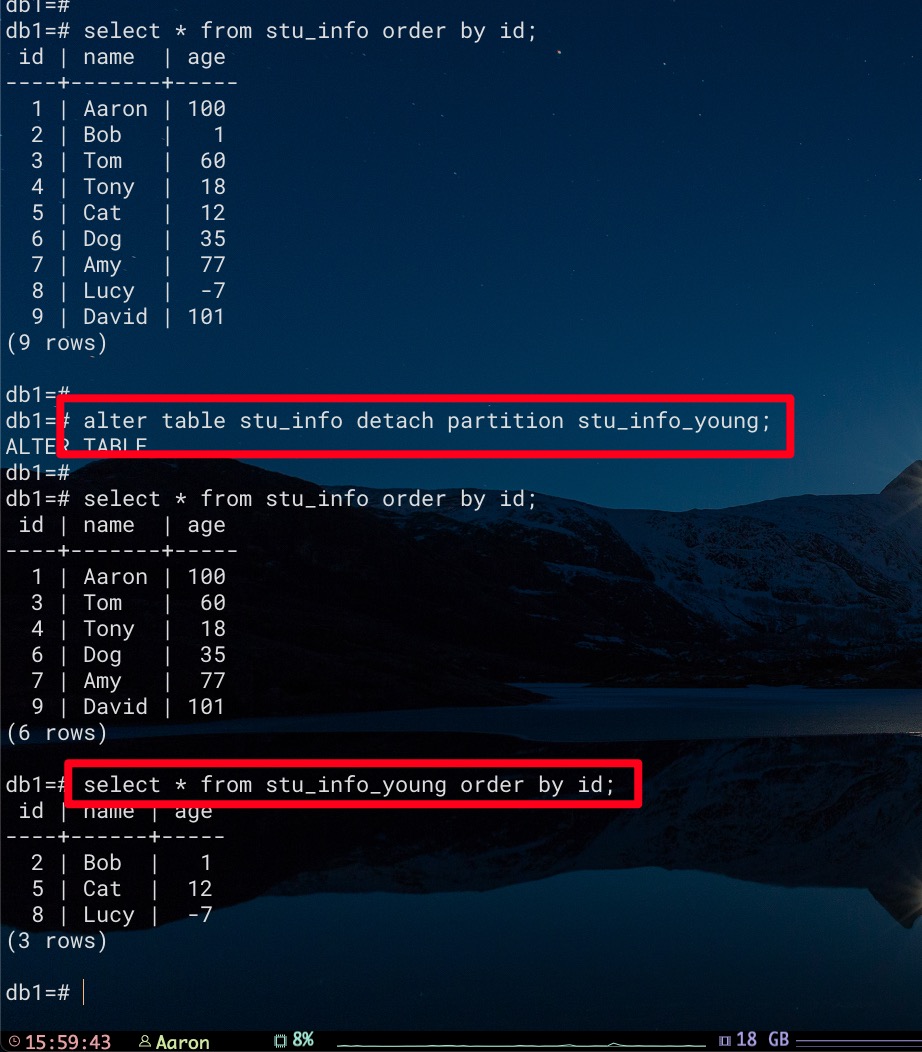
可通过如下方式将分区表从父表中移除,此时该分区表将会被转换为普通表。这样父表中将不会再查到该表的数据,但可以通过直接访问该表来获得
1 2 alter table stu_info detach partition stu_info_young;
可通过如下方式将向父表中添加某个分区表,此时该普通表将会被转换为分区表。相关数据可通过父表查询获得
1 2 alter table stu_info attach partition stu_info_young for values from (MINVALUE) to (18 );
Note
Range、List分区均支持default默认分区。但Hash分区方式不支持default默认分区
在PostgreSQL 11中,在父表创建索引、唯一性约束后,各分区表均会自动创建相应索引、唯一性约束
在父表创建唯一性约束时,必须包含分区键 。故,在父表建立主键时也必须包含分区键。因为各分区表中的唯一性约束只能保证数据在分区表中的唯一性。故需要添加分区键来保证其在所有分区表当中的唯一性。例如,对于分区表stu_info_young、stu_info_old而言,其可能各自都有一条id为1的记录,但由于分区键age不一样。故这两条数据在整体上才不会违反主键的唯一性要求
当进行修改操作,如果记录的分区键的值被修改后,导致其需要从原分区表a移动到新分区表b时。需要注意,如果是对父表进行修改操作时,相关记录不仅会修改成功,同时也会完成记录的移动;但如果是对原分区表a进行修改操作的话,则会直接修改失败
使用声明式分区表时,推荐将enable_partition_pruning 配置项设置为on ,以启用分区过滤功能。这样扫描时直接过滤掉不必要的分区,从而提高查询性能