这里介绍Kubernetes调度中的Pod亲和性

Pod亲和性
节点亲和性,是基于节点的标签对Pod进行调度。而Pod亲和性则可以实现基于已经在节点上运行Pod的标签来约束新Pod可以调度到的节点。具体地,如果X上已经运行了一个或多个满足规则Y的Pod,则这个新Pod也应该运行在X上。其中,X可以是节点、机架、可用性区域、地理区域等。可通过topologyKey字段定义拓扑域X,其取值是节点标签的键名Key;而Y则是Kubernetes尝试满足的规则。可以通过标签选择器的形式来定义。此外,Pod亲和性使用podAffinity字段,其下支持两种亲和性:
- requiredDuringSchedulingIgnoredDuringExecution:requiredDuringScheduling表明其是一个强制性的调度,调度器只有在规则被满足的时候才能执行调度;而IgnoredDuringExecution则表明其不会影响已在节点上运行的Pod
- preferredDuringSchedulingIgnoredDuringExecution:preferredDuringScheduling表明其是一个偏好性的调度,调度器会根据偏好优先选择满足对应规则的节点来调度Pod。但如果找不到满足规则的节点,调度器则会选择其他节点来调度Pod。而IgnoredDuringExecution则表明其不会影响已在节点上运行的Pod
强制性调度
这里提供了一个存在5个工作节点的K8s集群,然后我们使用Deployment部署了应用的前端服务
1 | # 应用的前端服务 |
效果如下所示,可以看到前端服务运行了2个Pod。分别在my-k8s-cluster-multi-node-worker2、my-k8s-cluster-multi-node-worker3节点上
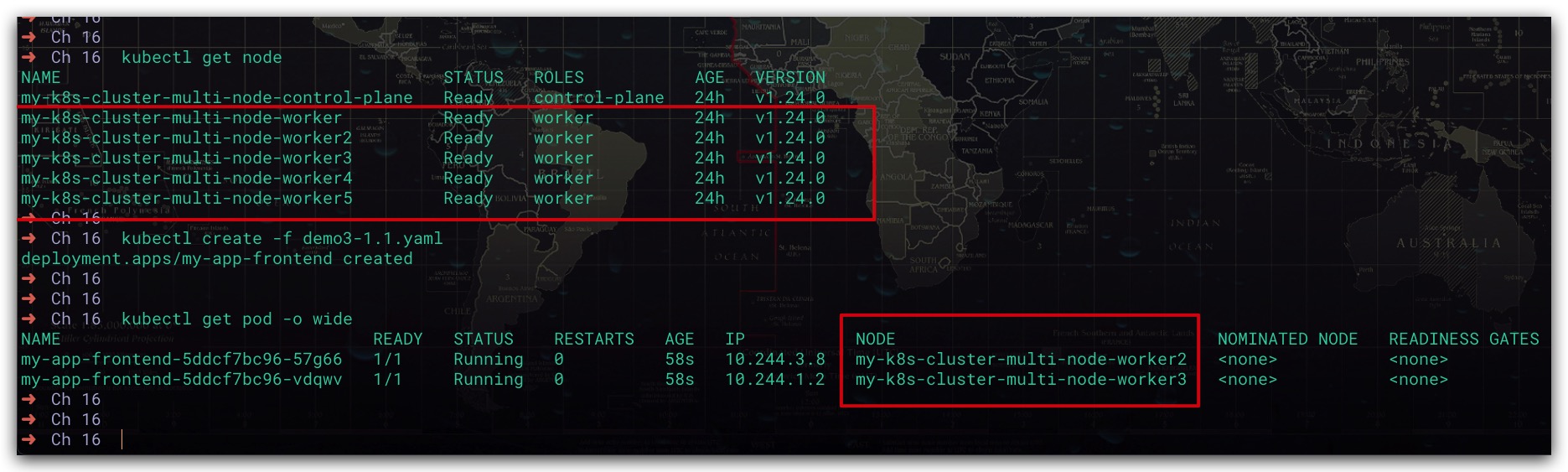
现在我们来部署应用的后端服务,这里我们期望后端服务的Pod能够运行在前端服务的Pod所在的节点上。这时就可以通过节点亲和性实现。具体地:
- 首先,使用podAffinity来定义Pod亲和性规则,使用requiredDuringSchedulingIgnoredDuringExecution定义强制性的调度规则
- 然后,使用标签选择器来确定Pod的范围,这里我们显然选择的是前端服务的Pod
- 最后,使用topologyKey来定义拓扑域信息,这里我们使用的是节点主机名。对于 此时即将被调度的新Pod 与 标签选择器所确定的Pod 来说,它们各自运行节点的主机名是相同的。即,后端服务的Pod 必须被调度到 与前端服务的Pod所在节点拥有相同主机名 的节点上
这样即可实现后端服务的Pod所在的节点上,一定存在前端服务的Pod
1 | # 应用的后端服务 |
效果如下所示。后端服务的5个Pod均运行在my-k8s-cluster-multi-node-worker2、my-k8s-cluster-multi-node-worker3节点上
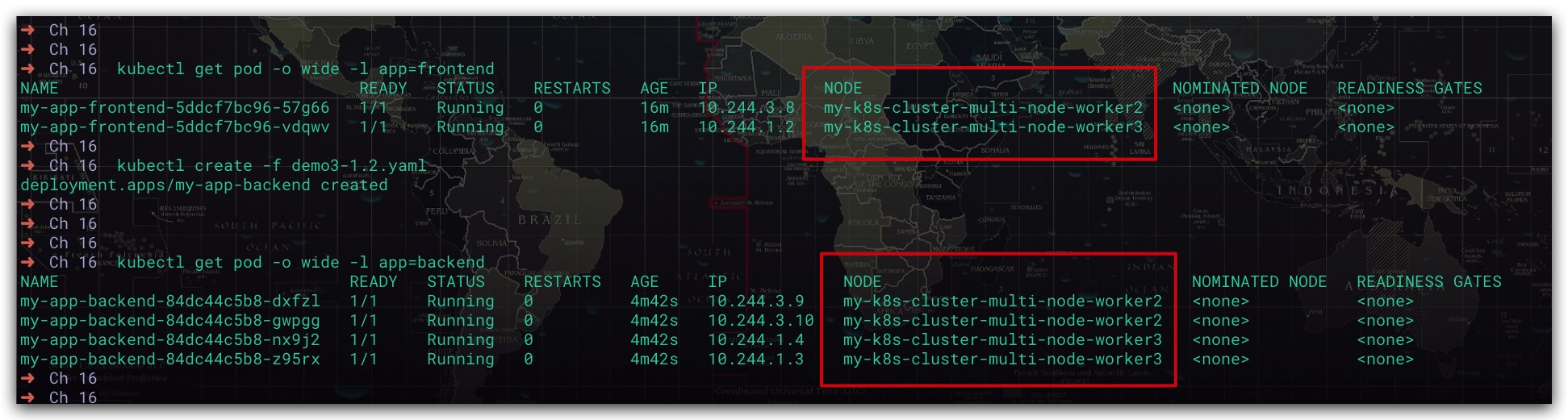
偏好性调度
这里提供了一个存在5个工作节点的K8s集群,然后我们使用Deployment部署了应用的前端服务
1 | # 应用的后端服务 |
效果如下所示,可以看到后端服务运行了2个Pod。分别在my-k8s-cluster-multi-node-worker、my-k8s-cluster-multi-node-worker3节点上。而通过标签信息可知,这两个节点都位于上海
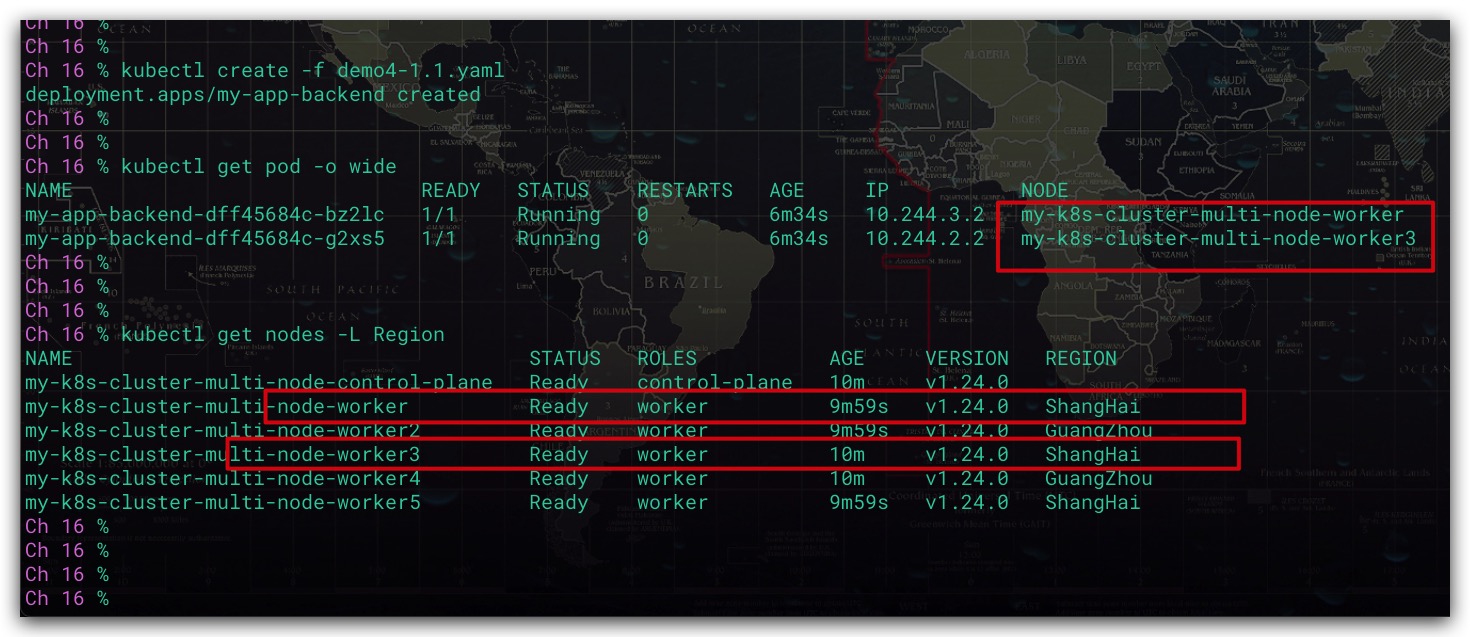
现在我们来部署应用的缓存服务,这里我们期望 缓存服务Pod所在的节点 能够尽可能与 前端服务Pod所在的节点 在通过一个地理区域,以减少网络通讯的延迟。
- 首先,使用podAffinity来定义Pod亲和性规则,使用preferredDuringSchedulingIgnoredDuringExecution定义偏好性的调度规则。可通过权重值来定义对节点偏好,权重值越大优先级越高。其中,权重范围: 1~100
- 然后,使用标签选择器来确定Pod的范围,这里我们显然选择的是前端服务的Pod
- 最后,使用topologyKey来定义拓扑域信息,这里我们使用的是节点的Region标签地理位置。此时即将被调度的新Pod 将会更倾向于调度到 与标签选择器所确定的Pod的所在节点 具有相同Region标签值的节点当中。即,缓存服务的Pod的所在节点 与 后端服务的Pod的所在节点 将会尽可能得位于同一个地理区域(具有相同Region标签值)
1 | # 应用的缓存服务 |
效果如下所示。缓存服务的4个Pod均运行同样位于上海的节点上。需要注意的是,由于这里是偏好性调度。故如果当上海的节点由于某种原因导致无法调度Pod到其上运行,调度器选择其他地域的节点进行调度也是合法的、允许的。比如这里位于广州的节点
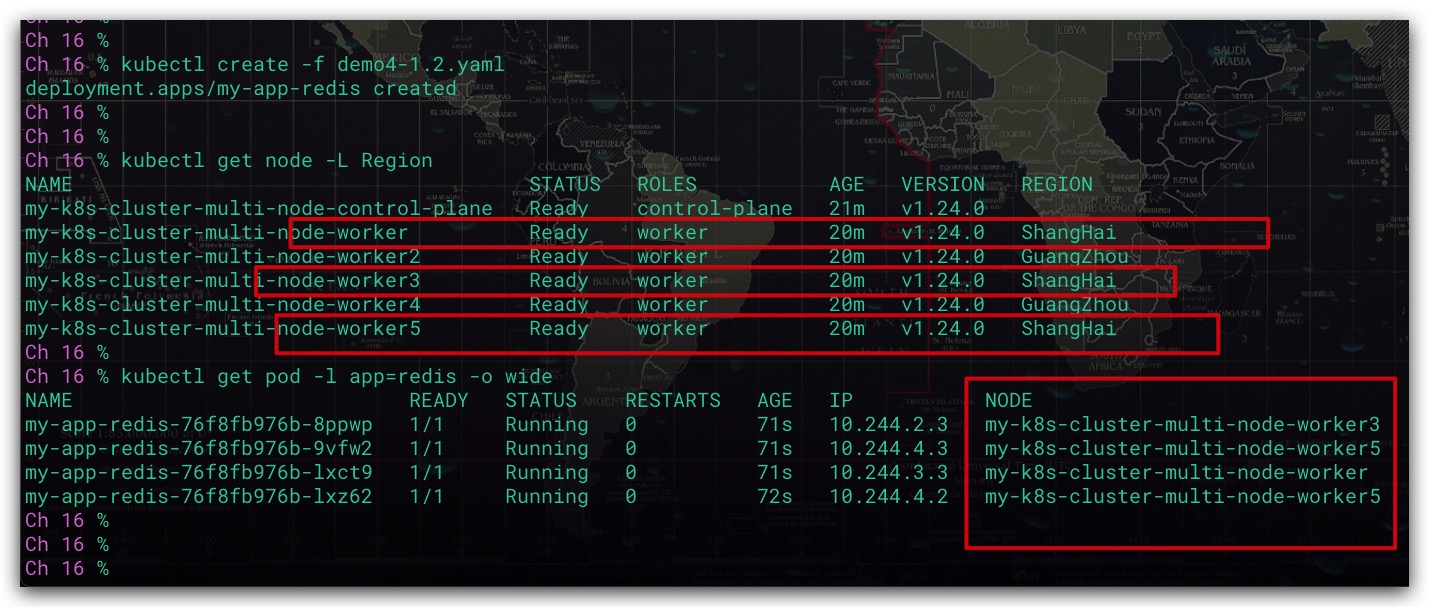
Pod反亲和性
而Pod反亲和性,同样也是基于已经在节点上运行Pod的标签来约束新Pod可以调度到的节点。只不过其与Pod亲和性恰恰相反。即,如果X上已经运行了一个或多个满足规则Y的Pod,则这个新Pod不应该运行在X上。此外,Pod反亲和性使用podAntiAffinity字段,其下同样支持两种反亲和性:requiredDuringSchedulingIgnoredDuringExecution 强制性调度、preferredDuringSchedulingIgnoredDuringExecution 偏好性调度
强制性调度
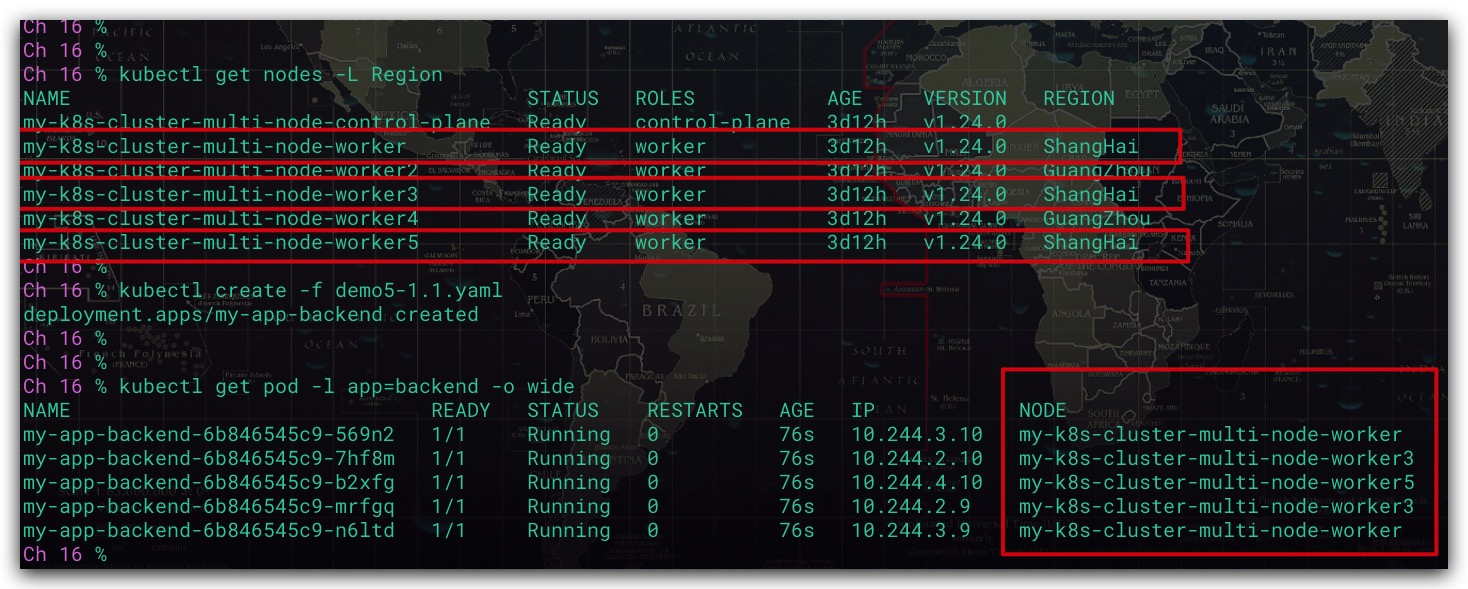
这里提供了一个存在5个工作节点的K8s集群,然后我们使用Deployment部署了应用的后端服务。这里为了便于后续演示,我们规定后端服务的Pod只允许运行在上海的节点上
1 | # 应用的后端服务 |
效果如下所示,可以看到后端服务运行了5个Pod。分别运行在位于上海的my-k8s-cluster-multi-node-worker、my-k8s-cluster-multi-node-worker3、my-k8s-cluster-multi-node-worker5节点上
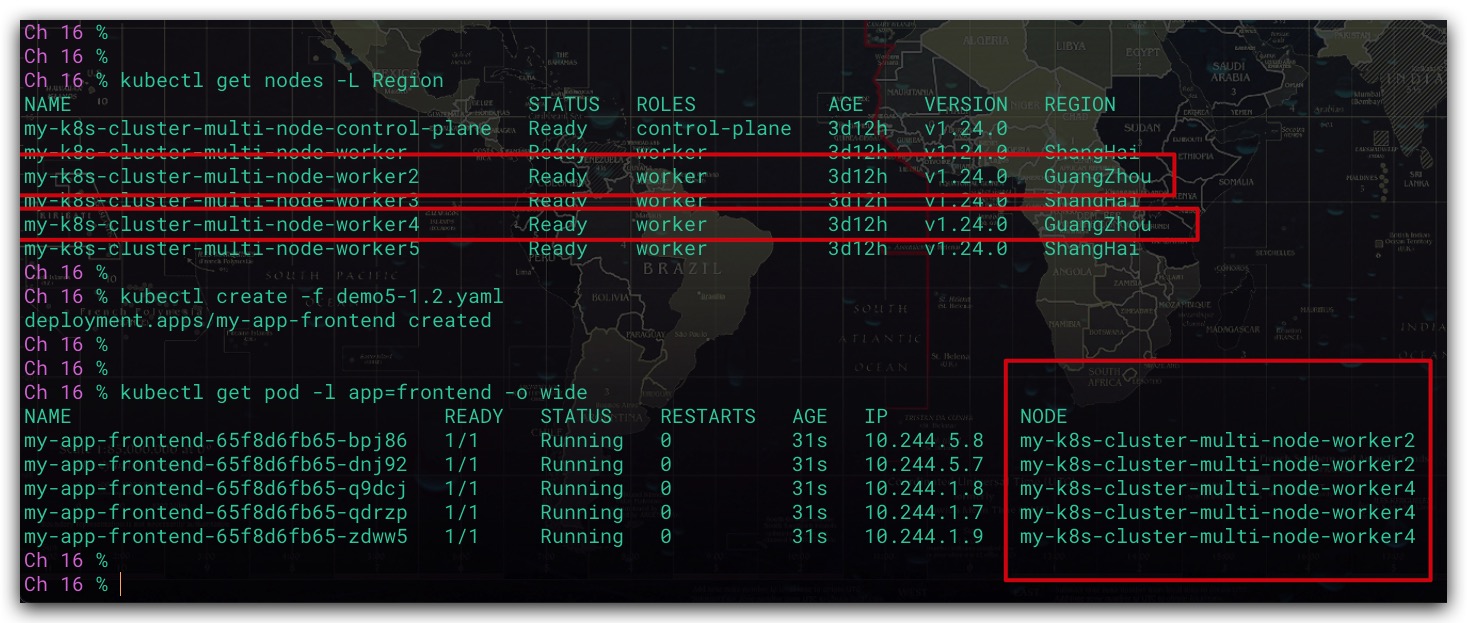
现在我们来部署应用的前端服务,同时基于某种特殊原因的考量,我们期望该应用的前、后端服务的Pod分别运行在不同区域。即前端服务的Pod的运行在位于上海的节点,则我们希望后端服务的Pod运行在除上海之外的节点当中。这时就可以通过节点反亲和性实现。具体地:
- 首先,使用podAntiAffinity来定义Pod反亲和性规则,使用requiredDuringSchedulingIgnoredDuringExecution定义强制性的调度规则
- 然后,使用标签选择器来确定Pod的范围,这里我们显然选择的是后端服务的Pod
- 最后,使用topologyKey来定义拓扑域信息,这里我们使用的是节点的Region标签地理位置。对于 此时即将被调度的新Pod 与 标签选择器所确定的Pod 来说,它们各自运行节点的地理位置是不同的。即,后端服务的Pod 必须被调度到 与前端服务的Pod所在节点拥有不同地理位置 的节点上
1 | # 应用的前端服务 |
效果如下所示。前端服务的5个Pod均运行在位于广州的my-k8s-cluster-multi-node-worker2、my-k8s-cluster-multi-node-worker4节点上
偏好性调度
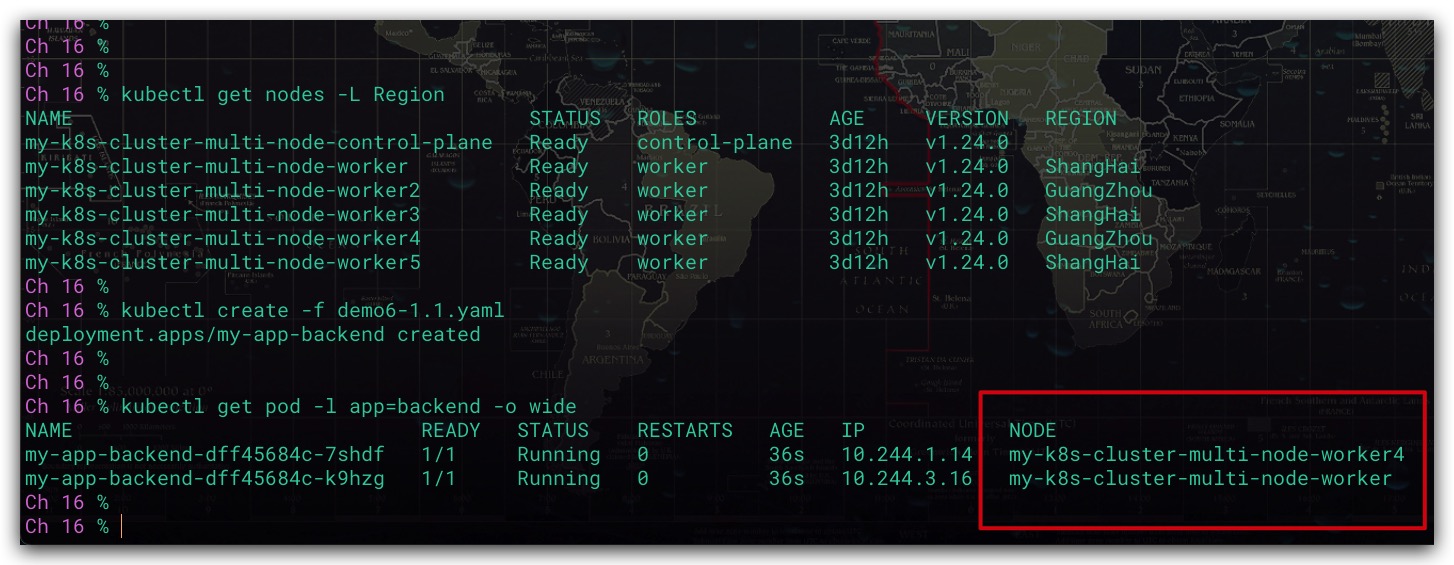
这里提供了一个存在5个工作节点的K8s集群,然后我们使用Deployment部署了应用的后端服务
1 | # 应用的后端服务 |
效果如下所示,可以看到前端服务运行了2个Pod。分别在my-k8s-cluster-multi-node-worker、my-k8s-cluster-multi-node-worker4节点上
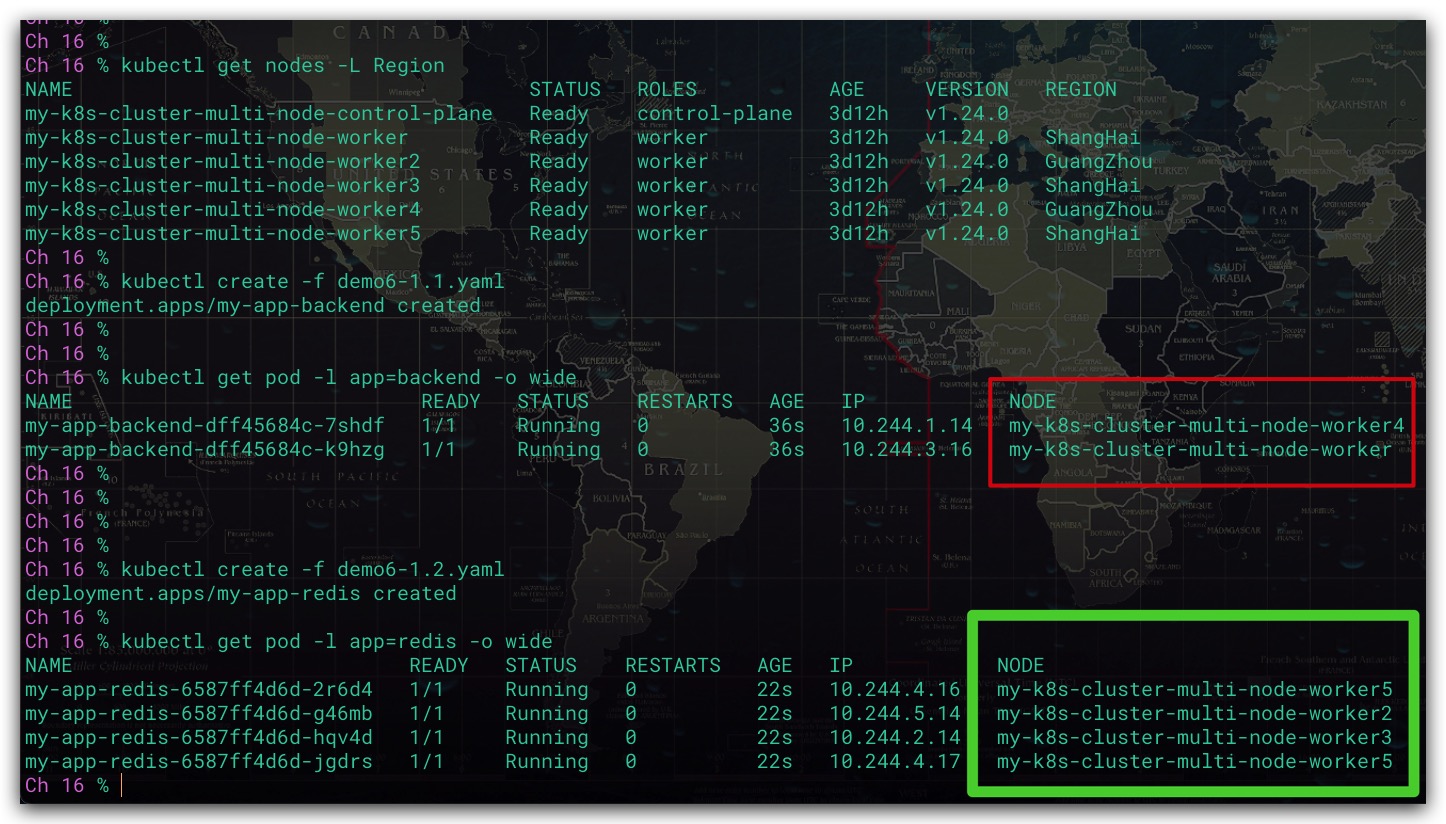
现在我们来部署应用的缓存服务,这里由于后端服务、缓存服务都非常占用资源。故我们提出下述调度要求
- 缓存服务Pod所在的节点 能够尽可能与 前端服务Pod所在的节点 不是同一个节点
- 缓存服务Pod所在的节点 能够尽可能与 前端服务Pod所在的节点 不在同一个地理区域
- 上诉2点均为偏好性要求,且第1点优先级是最高的
- 首先,使用podAntiAffinity来定义Pod反亲和性规则,使用preferredDuringSchedulingIgnoredDuringExecution定义偏好性的调度规则。可通过权重值来定义偏好,权重值越大优先级越高。其中,权重范围: 1~100
- 然后,使用标签选择器来确定Pod的范围,这里我们显然选择的是前端服务的Pod
- 最后,使用topologyKey来定义拓扑域信息。这里我们分别使用了节点主机名、地理位置。以此实现即将被调度的新Pod 将会更倾向于调度到 与标签选择器所确定的Pod的所在节点 具有不同节点 或 不同地理区域的节点上
1 | # 应用的缓存服务 |
效果如下所示。缓存服务的4个Pod均运行在与后端服务Pod所在节点不同的节点上。但这里由于是偏好性调度,当最终结果未满足两个服务运行在不同的地理位置时,即调度器选择相同地理位置的节点进行调度也是合法的、允许的
参考文献
- Kubernetes in Action中文版 Marko Luksa著
- 深入剖析Kubernetes 张磊著
