分布式系统中各类型数据的一致性要求不尽相同,而Quorum NWR算法则为我们提供了一种在强一致性与最终一致性之间可以进行动态变化的思路

基本原理
在Quorum NWR算法中,存在三个参数:N、W、R。这里依次进行介绍
1. 副本数 N
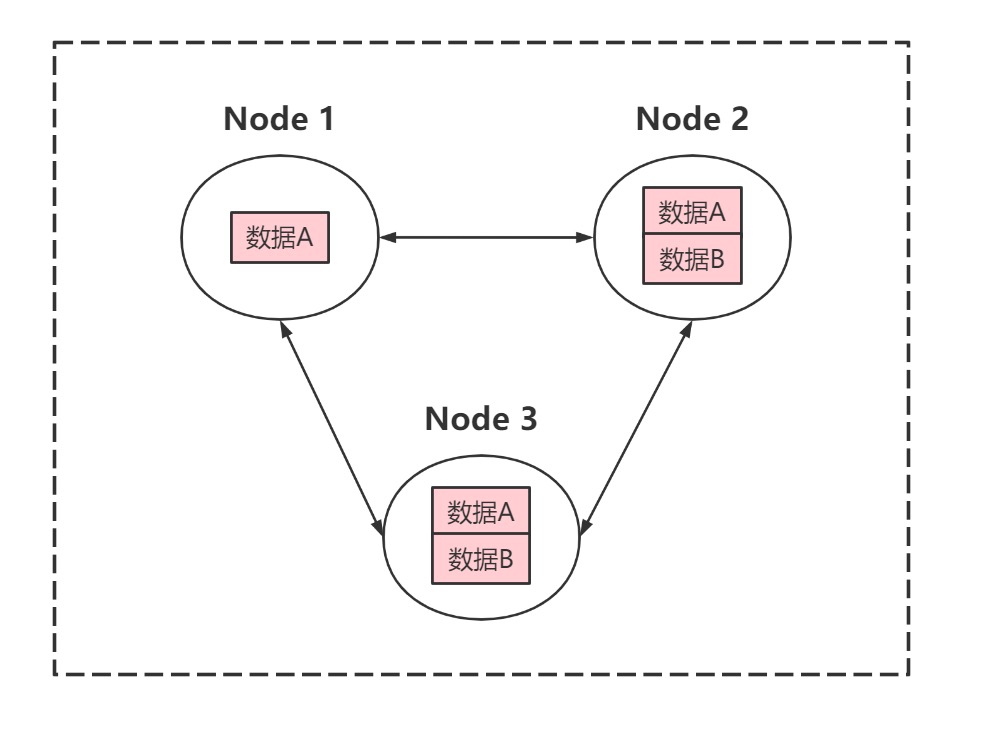
参数N为副本数,又被称作复制因子。其含义是一份数据在整个集群中的副本数量。注意其与集群中节点数量并无任何关系,例如下图是一个3节点的集群,其中数据A的副本数为3、数据B的副本数为2
2. 写一致性级别 W
参数W为写一致性级别(Write Consistency Level),其含义为成功完成W个副本更新、写入,才会视为本次写操作成功
3. 读一致性级别 R
参数R为读一致性级别(Read Consistency Level)。类似地,其含义为成功从R个副本读取相应数据,才会视为本次读操作成功
下面就N、W、R参数在不同组合条件下,如何实现强一致性、最终一致性进行介绍:
当 W + R > N 时,根据鸽巢原理可知,在进行读操作时R个副本返回的结果中一定包含最新的数据。然后再利用时间戳、版本号等手段即可确定出最新的数据。换言之在满足该条件的参数组合下,可以实现数据的强一致性
当 W + R <= N 时,无法实现强一致性,其只能保障最终一致性。即系统可能会获取旧数据
事实上当W=N、R=1时,即所谓的WARO(Write All Read One)。就是CAP理论中CP模型的场景。综上所述从实际应用角度出发,Quorum NWR算法有效解决了AP模型下不同业务场景对自定义一致性级别的需求
参考文献
- 数据密集型应用系统设计(DDIA) Martin Kleppmann著
