所谓统计数据指的是关于表、索引的统计数据,了解它们可以帮助我们更方便的使用MySQL

存储方式
InnoDB下针对不同存储方式的统计数据可分为两种:永久性的统计数据、非永久性的统计数据。前者是将统计数据存储在硬盘中。而后者则是将统计数据储存在内存中的,一旦服务关闭,这些统计数据就丢失了。为此MySQL中提供了一个系统变量innodb_stats_persistent用于设置统计数据的存储方式。具体地,值为ON意为统计数据被存储到硬盘中,值为OFF意为统计数据被存储到内存中
由于统计数据是以表为单位进行统计的,故我们还可以通过STATS_PERSISTENT属性来显式地设置表的统计数据的存储方式,其中,值为0意为该表的统计数据存储在内存中,值为1意为该表的统计数据存储在硬盘中。更多地,我们一般很少会在建表时指定该属性,故表的统计数据的存储方式就默认使用我们上面提到的系统变量innodb_stats_persistent的配置
1 | -- 创建表,并设置统计数据的存储方式 |
永久性的统计数据
具体地对于永久性的统计数据而言,其是将表、索引的统计数据分别存储在innodb_table_stats、innodb_index_stats表中
表的统计数据
表的统计数据存放在innodb_table_stats表中,如下图所示
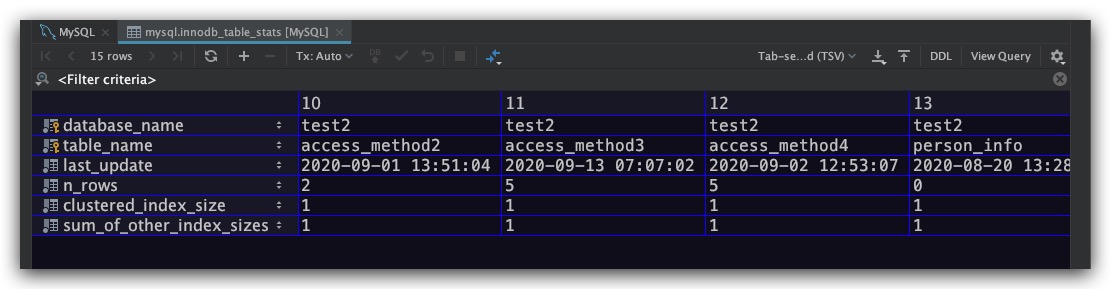
具体地,这里对该表中的相关字段进行说明,其中主键为database_name、table_name两个字段的组合
- database_name : 数据库名
- table_name : 数据表名
- last_update : 本条记录的最后更新时间
- n_rows : 该表的记录条数
- clustered_index_size : 该表聚簇索引使用的页面数量
- sum_of_other_index_sizes : 该表其他索引使用的页面数量
值得一提的是,在InnoDB存储引擎下,其对表中记录数量的统计值n_rows是不准确的。其统计方法是先通过算法选取若干个(聚簇索引的)叶子节点页面,然后计算叶子节点页面中记录数量的均值,最后将均值乘以(聚簇索引的)叶子节点的数量得到n_rows值。故其不是一个精确值,而是一个估计值。在计算均值过程中,如果选取的叶子节点越多,则n_rows值越准确。故在MySQL中,可通过系统变量innodb_stats_persistent_sample_pages来设置 在计算永久性的统计数据时统计过程所需的页面采样数量。显然innodb_stats_persistent_sample_pages值越大,统计过程所需耗时也就越多
前面我们说了,统计数据是以表为单位进行统计的,故我们还可以通过STATS_SAMPLE_PAGES属性来显式地设置表在计算永久性的统计数据时统计过程所需的页面采样数量。更多地,我们一般很少会在建表时指定该属性,则该表就默认使用我们上面提到的系统变量innodb_stats_persistent_sample_pages的配置
1 | -- 创建表,并设置 永久性的统计数据时 统计过程所需的页面采样数量 |
当然,查看表的统计信息还可以通过下面SQL语句进行查询
1 | show table status like '[表名]'; |
索引的统计数据
为了方便后续行文,我们先来创建一张表,并向其中插入一些数据
1 | CREATE TABLE access_method3 ( |
索引的统计数据存放在innodb_index_stats表中,如下所示
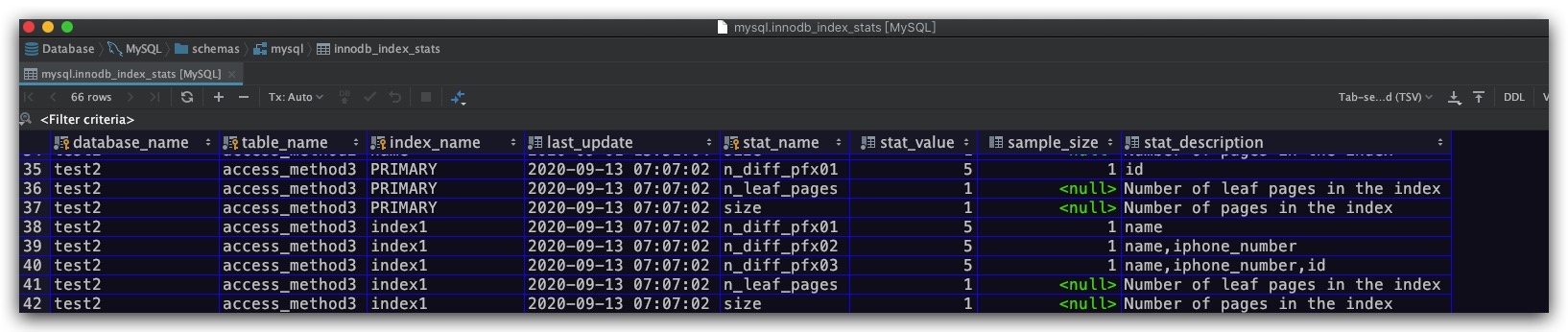
具体地,这里对该表中的相关字段进行说明,其中主键为database_name、table_name、index_name、stat_name四个字段的组合
- database_name : 数据库名
- table_name : 数据表名
- index_name : 索引名
- last_update : 本条记录最后的更新时间
- stat_name : 统计项的名称
- stat_value : 统计项的值
- sample_size : 为计算统计项而采样的页面数量。对于多个字段的联合索引而言,其需要采样的页面数量为innodb_stats_persistent_sample_pages × 索引字段的个数。当如果需要采样的页面数量大于该索引的叶子节点数量时,则会采用全表扫描的方式来统计索引列的不重复值的数量
- stat_description : 对统计项的描述
从上图可以看到在同一个索引中会有多个不同的stat_name统计项,这里就对各统计项目进行解释
- n_leaf_pages : 该索引的叶子节点使用的页面数量
- size : 该索引使用页面的总数量
- n_diff_pfxNN : 这里的NN可以替换为01、02、03…。其代表索引列中部分字段组合下不重复值的数量。例如上图的统计项为n_diff_pfx01的记录,从stat_description字段就可以看出该统计项表示的是该索引中name字段不重复的记录数量为5
这里关于不重复值的数量统计,重点来讲解一下NULL值这个特殊情况。比如这里有一个age字段,其在4条记录的值分别为23、41、NULL、NULL。而事实上很多时候,大家对于NULL值的理解存在分歧
- 第一种理解是NULL值表示的是一个未确定的值,故在MySQL下任何一个和NULL值做比较的表达式,其结果都为NULL值。例如下面所示。所以对于每个NULL值而言都是独一无二的。故在此种理解下,对于age字段而言,其不重复值的数量为4
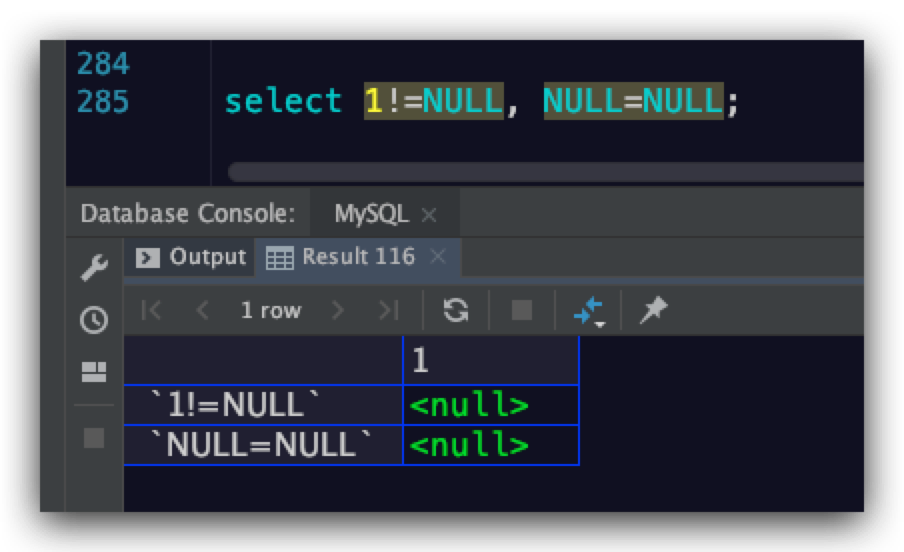
第二种理解是在业务逻辑中NULL值即表示没有,即认为所以NULL值都是相同的。故在此种理解下,对于age字段而言,其不重复值的数量为3
第三种理解则认为NULL值完全没意义。在统计不重复值的数量时,完全不考虑NULL值。故在此种理解下,对于age字段而言,其不重复值的数量为2
由于众口难调,所以MySQL提供了一个系统变量innodb_stats_method以满足不同用户的不同理解需求。具体地,该系统变量提供以下三个值nulls_unequal、nulls_equal、nulls_ignored来分别满足上述三种不同理解的场景需求
当然我们还可以通过下面的语句来查看表的索引情况
1 | show index from [表名]; |
现结合下面的实例,对其结果的字段进行介绍
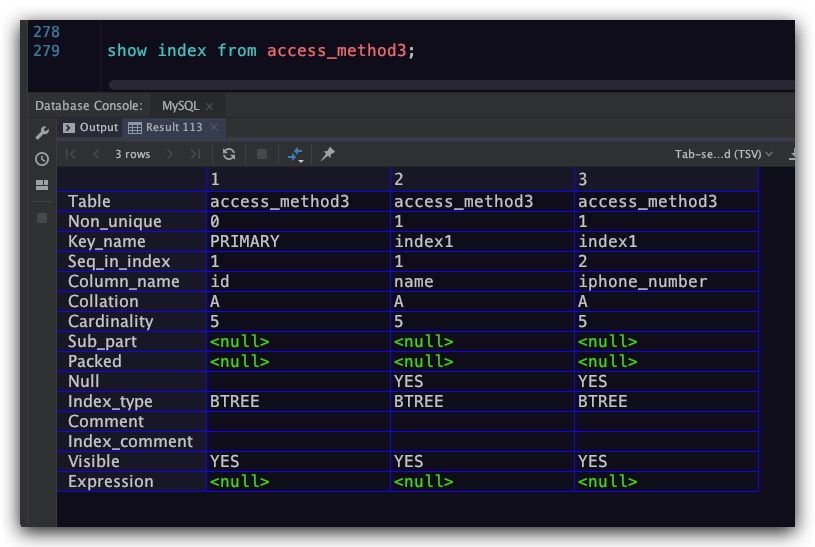
- Table : 索引所属表名
- Non_unique : 索引列的值是否是唯一的。具体地,对于聚簇索引、唯一二级索引而言该字段值为0,普通二级索引值为1
- Key_name : 索引名称
- Seq_in_index : 索引字段在索引中的位置,从1开始计数。例如对于索引index1(name, iphone_number)而言,name、iphone_number字段的值分别为1、2
- Column_name : 索引字段名称
- Collation : 存放索引字段中的值所使用的排序方式。值为A意为升序,值为NULL意为降序
- Cardinality : 索引字段中不重复值的数量
- Sub_part : 当索引字段类型为字符串时,该值表示其是对字段的前N个字符建立索引。如果该值为NULL,则意为其是对整个字符串建立索引,而非只是对字符串的前N个字符建立索引
- Packed : 表示该索引字段如何被压缩。值为NULL意为未被压缩
- Null : 该索引字段是否允许存储NULL值
- Index_type : 索引类型。常见的值有BTREE,即我们所说的B+树索引
- Comment : 索引字段的注释信息
- Index_comment : 索引注释信息
更新统计数据
MySQL服务重新统计数据
当系统变量innodb_stats_auto_recalc值为ON,即可实现统计数据的自动更新。具体地,一般当表中变化的记录数超过一定阈值,MySQL会自动开始重新进行统计。只不过该统计是异步的,所以即使满足重新统计的条件也不会立即开始计算,有可能会延迟几秒才开始
前面我们说了,统计数据是以表为单位进行统计的,故我们还可以通过STATS_AUTO_RECALC属性来显式地设置表是否自动更新统计数据。具体地,当值为0意为不会进行自动更新;当值为1意为会进行自动更新。更多地,我们一般很少会在建表时指定该属性,则该表就默认使用我们上面提到的系统变量innodb_stats_auto_recalc的配置
1 | -- 创建表,并设置 是否自动更新统计数据 |
而如果系统innodb_stats_auto_recalc变量值为OFF,则MySQL不会自动更新统计数据。此时我们可以通过下面SQL语句手动的让MySQL开始统计工作。该统计工作会立即开始,即是同步的
1 | -- 重新统计指定表的相关数据 |
手动更新innodb_table_stats、innodb_index_stats表
前面我们介绍了innodb_table_stats、innodb_index_stats表。既然它们也是数据表,那自然也可以通过update语句来直接修改上述两表中的数据记录,只不过最后需要通过flush语句来使修改生效即可。下面通过一个具体的例子进行说明
1 | -- 将修改innodb_table_stats表中表名为access_method3的记录的n_rows字段为996 |
非永久性的统计数据
由于非永久性的统计数据是存放在内存当中的。一旦MySQL服务停机或者断电,统计数据即会丢失。故一般很少使用,即将系统变量innodb_stats_persistent设为OFF。这里着重强调一点的是,在非永久性的统计数据中,其统计过程所需的页面采样数量是由系统变量innodb_stats_transient_sample_pages来决定
参考文献
- MySQL是怎样运行的
