这里就基于Docker的ElasticSearch部署、使用方式进行介绍,并就与SpringBoot的集成开展相关实践

环境配置
ElasticSearch
通过Docker拉取ElasticSearch镜像并创建容器,需要显式地指定ElasticSearch版本
1
2
3
4
5
6
7
8
|
docker pull elasticsearch:7.12.0
docker run -e "discovery.type=single-node" \
-d -p 9200:9200 -p 9300:9300 \
--name myES \
elasticsearch:7.12.0
|
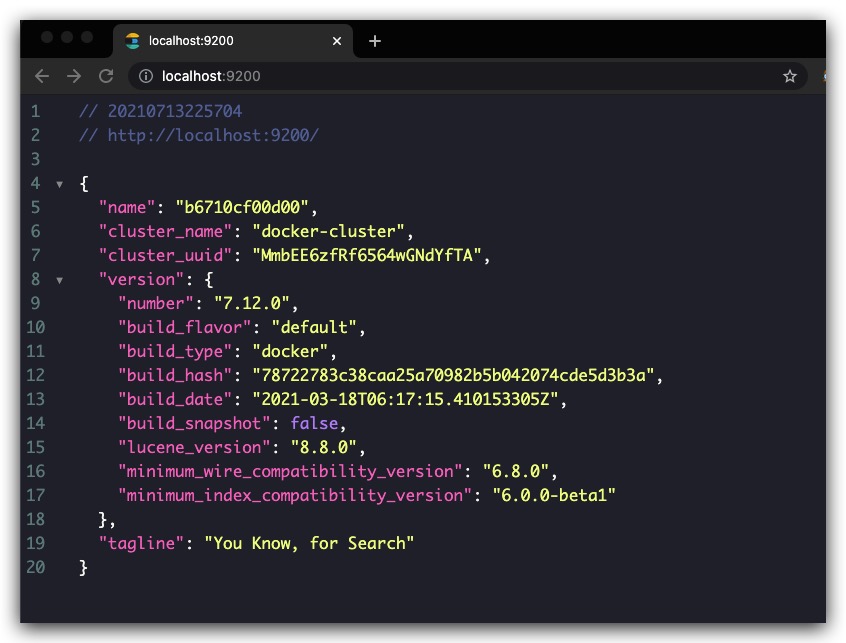
访问 http://localhost:9200,效果如下
Kibana
通过Docker拉取Kibana镜像并创建容器。值得一提的是,需要保证Kibana版本与ElasticSearch版本一致
1
2
3
4
5
6
7
8
|
docker pull kibana:7.12.0
docker run \
-d -p 5601:5601 \
--name Kibana \
kibana:7.12.0
|
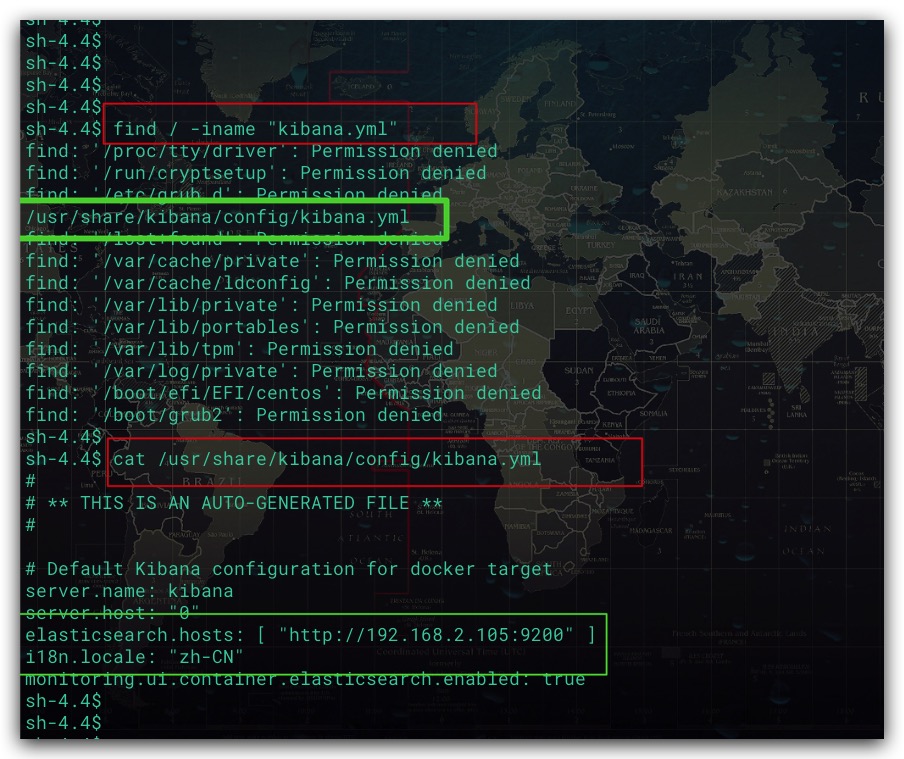
进入Kibana容器,修改配置文件kibana.yml,涉及命令如下。这里我们宿主机IP为192.168.2.105
1
2
3
4
5
6
|
find / -iname "kibana.yml"
cd /usr/share/kibana/config
vi kibana.yml
|
如下图所示
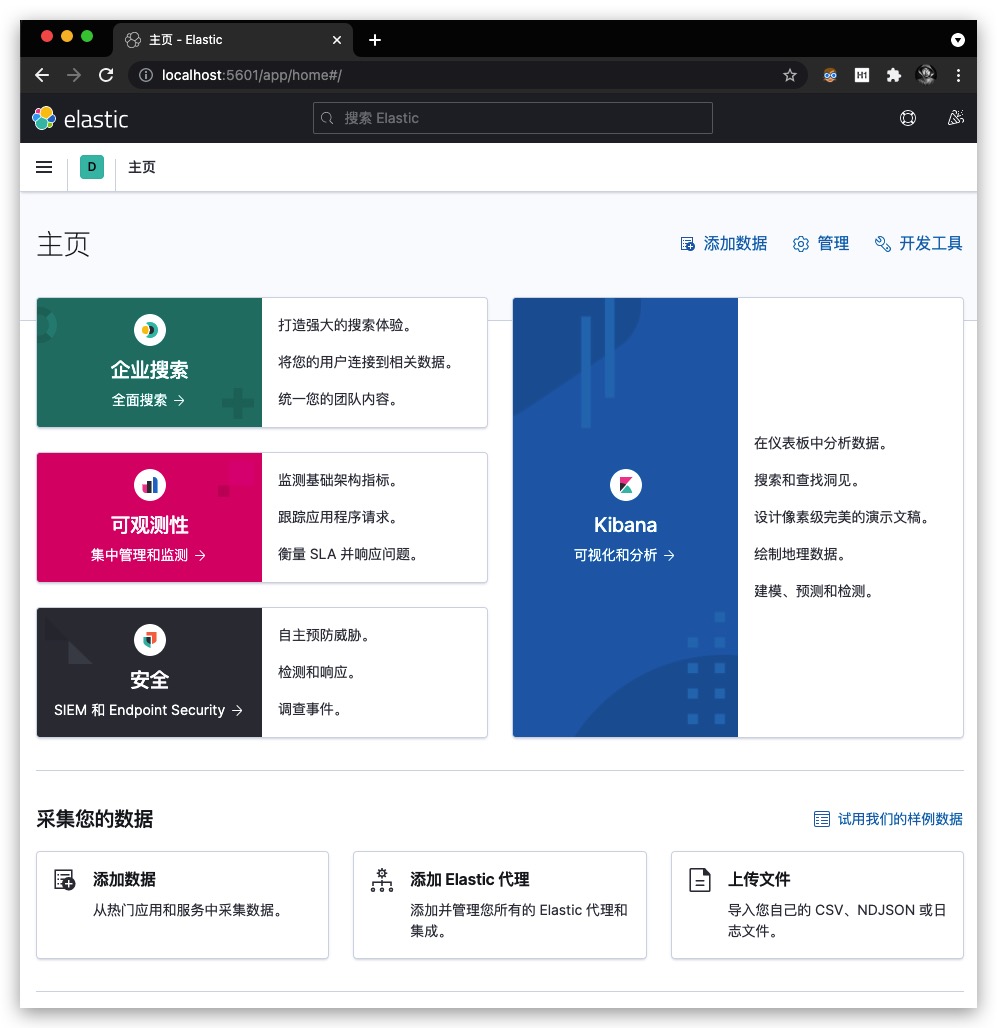
修改完毕后,重启Kibana容器。访问 http://localhost:5601,效果如下
SpringBoot集成配置
POM文件添加ES依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| <properties>
<es.version>7.12.0</es.version>
</properties>
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${es.version}</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${es.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${es.version}</version>
</dependency>
</dependencies>
|
在配置文件application.properties中添加ElasticSearch服务连接信息
1
2
3
4
|
elasticsearch.hostname=localhost
elasticsearch.port=9200
elasticsearch.schema=http
|
实践
索引管理
创建索引
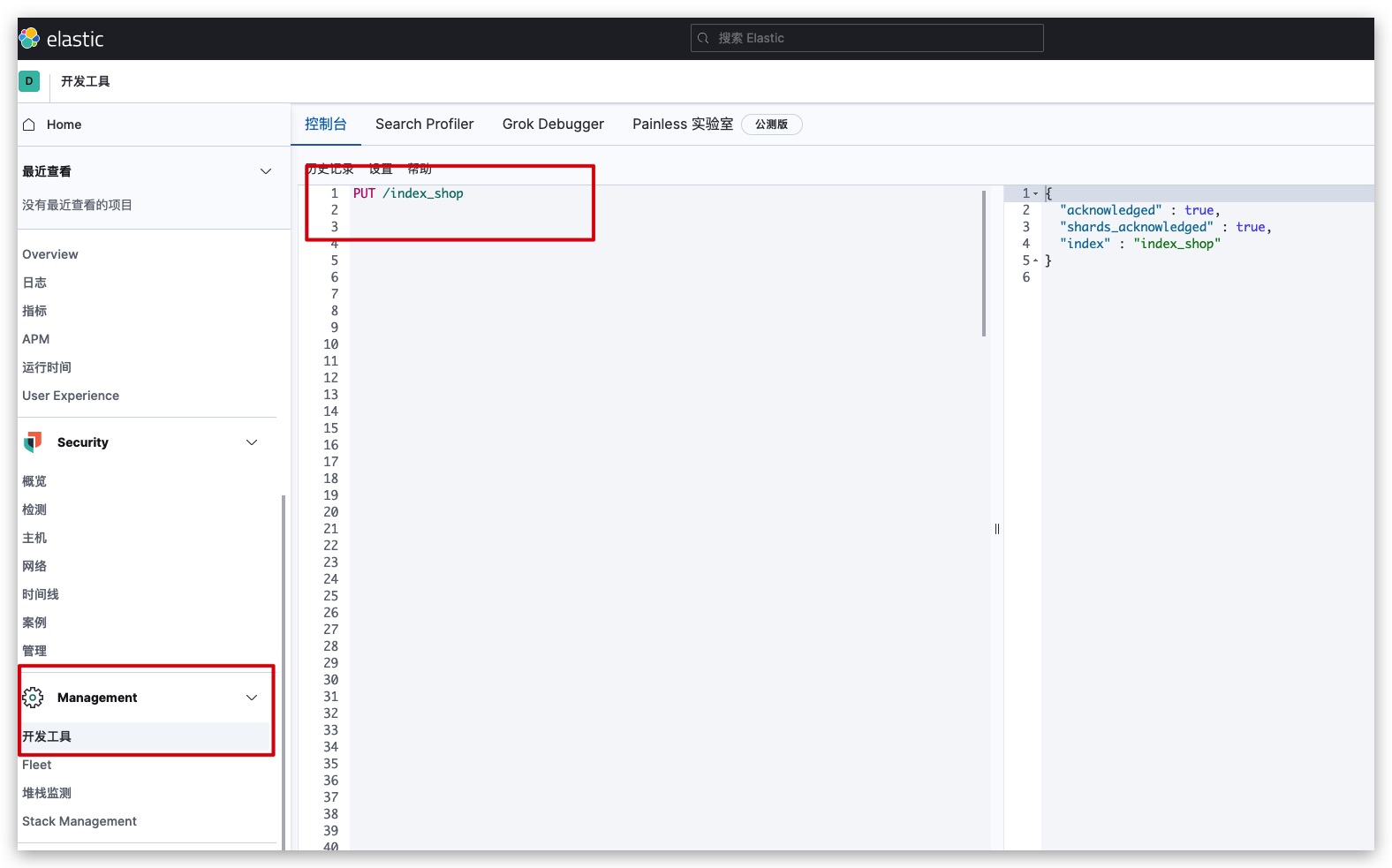
可通过如下方式发送PUT请求,创建索引
1
2
|
PUT http://127.0.0.1:9200/index_shop
|
推荐通过Kibana的开发工具发送RESTful API发送请求,可以免去ES地址、端口等信息,如下所示
索引存在
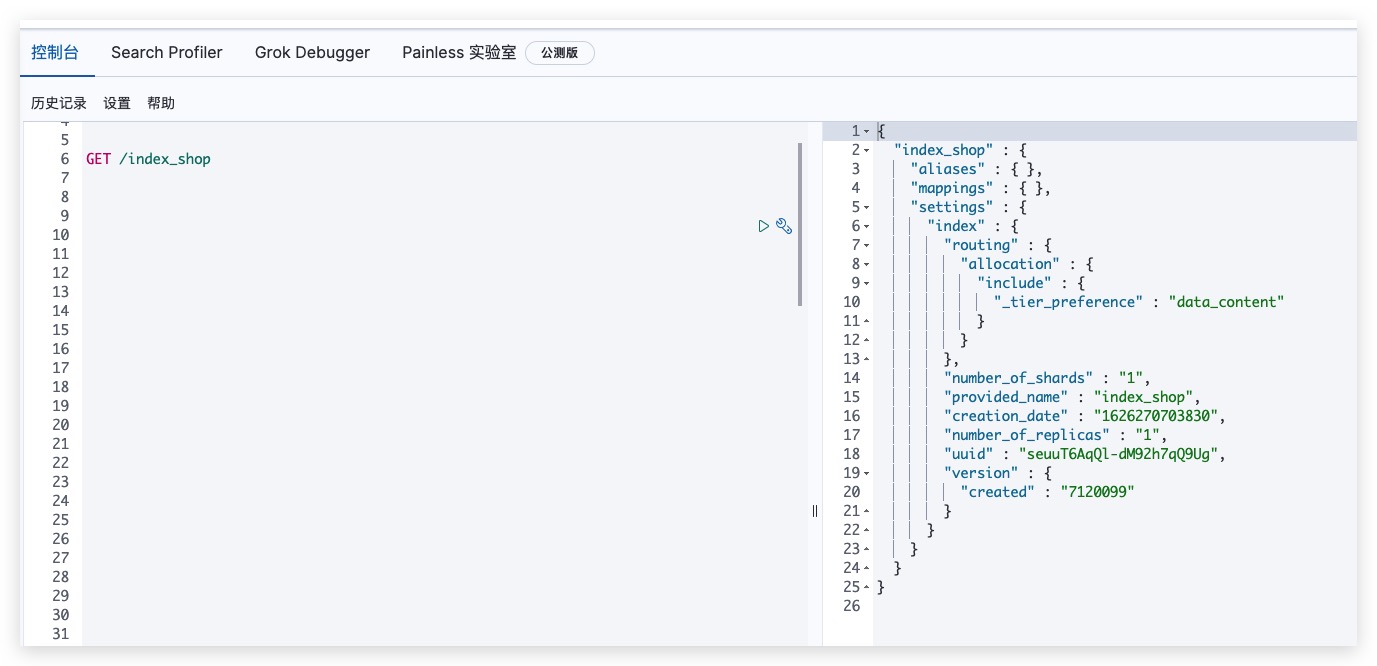
可通过如下方式发送GET请求,判断索引是否存在
Kibana测试结果如下所示
删除索引
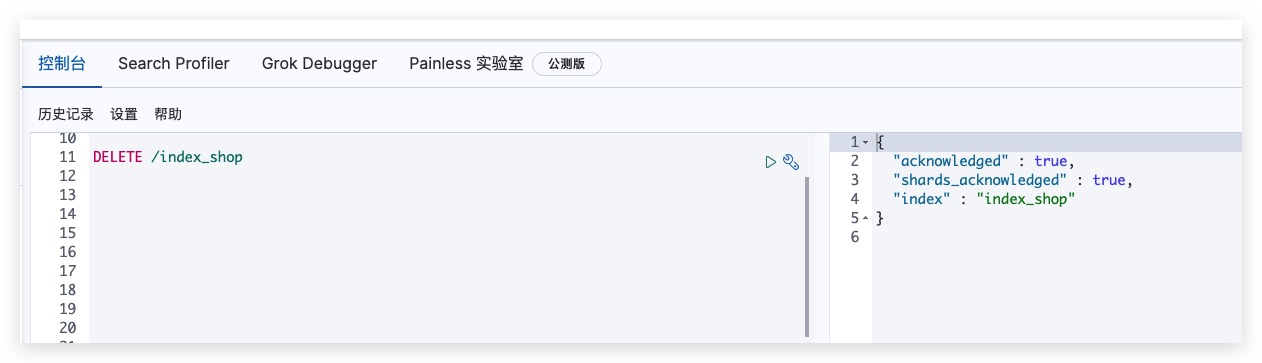
可通过如下方式发送DELETE请求,删除索引
Kibana测试结果如下所示
SpringBoot集成
SpringBoot集成过程中可以直接注入RestHighLevelClient使用,示例代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
@RunWith(SpringRunner.class)
@SpringBootTest(classes = SpringBoot1Application.class)
@FixMethodOrder(MethodSorters.NAME_ASCENDING)
public class TestESIndex {
@Autowired
private RestHighLevelClient restHighLevelClient;
private static String name = "index_shop";
@Test
public void test1CreateIndex() throws IOException {
String indexName = name;
CreateIndexRequest request = new CreateIndexRequest( indexName );
CreateIndexResponse response = restHighLevelClient.indices().create( request, RequestOptions.DEFAULT );
Boolean status = response.isAcknowledged();
System.out.println("[Test 1]: Index <" + name + "> create complete, status: " + status);
}
@Test
public void test2ExistIndex() throws IOException {
String indexName = name;
GetIndexRequest request = new GetIndexRequest(indexName);
Boolean exist = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("[Test 2]: Index <" + name + "> exist: " + exist);
}
@Test
public void test3DeleteIndex() throws IOException {
String indexName = name;
DeleteIndexRequest request = new DeleteIndexRequest(indexName);
AcknowledgedResponse response = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
Boolean status = response.isAcknowledged();
System.out.println("[Test 3]: Index <" + name + "> delete: " + status);
}
}
|
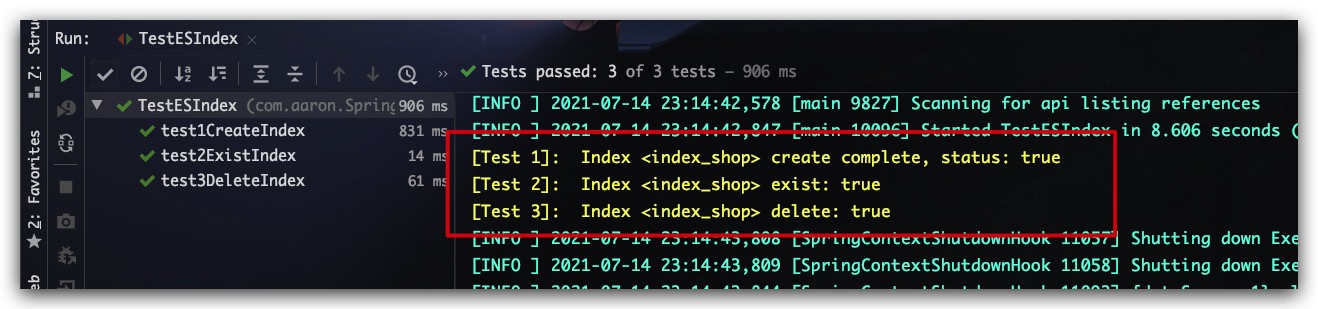
测试结果如下所示
文档管理
添加文档
可通过如下方式发送POST请求,向指定索引添加文档
1
2
3
4
5
6
7
8
|
POST /index_book2/_doc/1
{
"name": "C Primer Plus",
"price": 61.23,
"pageNum": 626,
"publishTime": "2005-02-01"
}
|
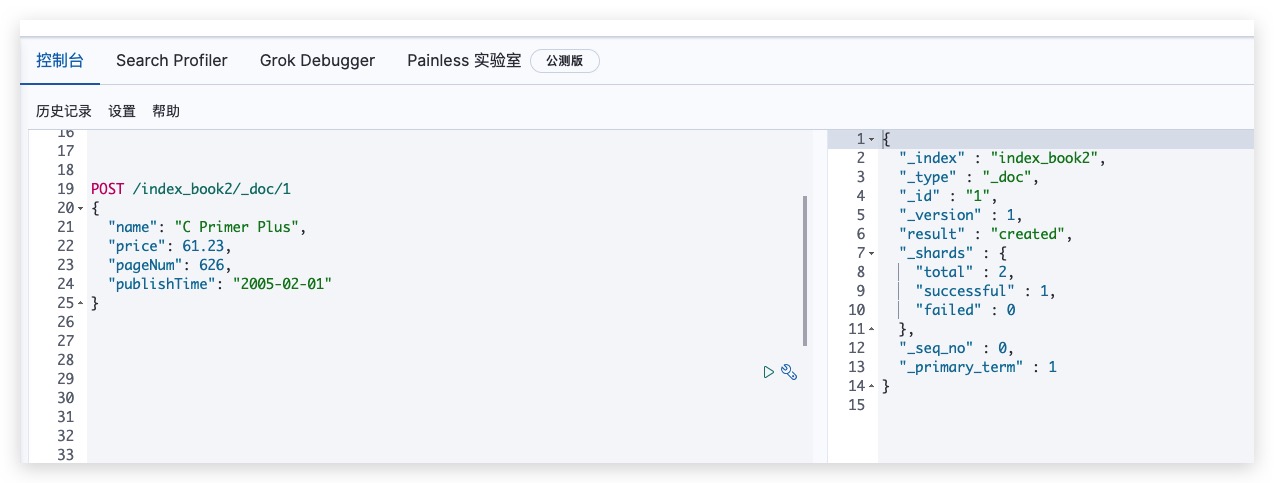
Kibana测试结果如下所示
文档存在
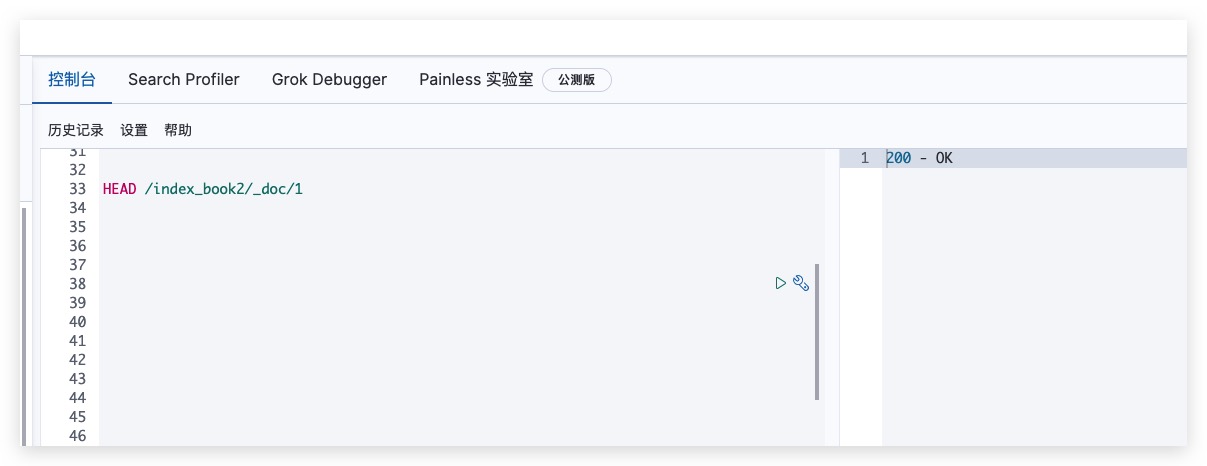
可通过如下方式发送HEAD请求,判断索引中是否存在指定文档
1
2
|
HEAD /index_book2/_doc/1
|
Kibana测试结果如下所示
获取文档
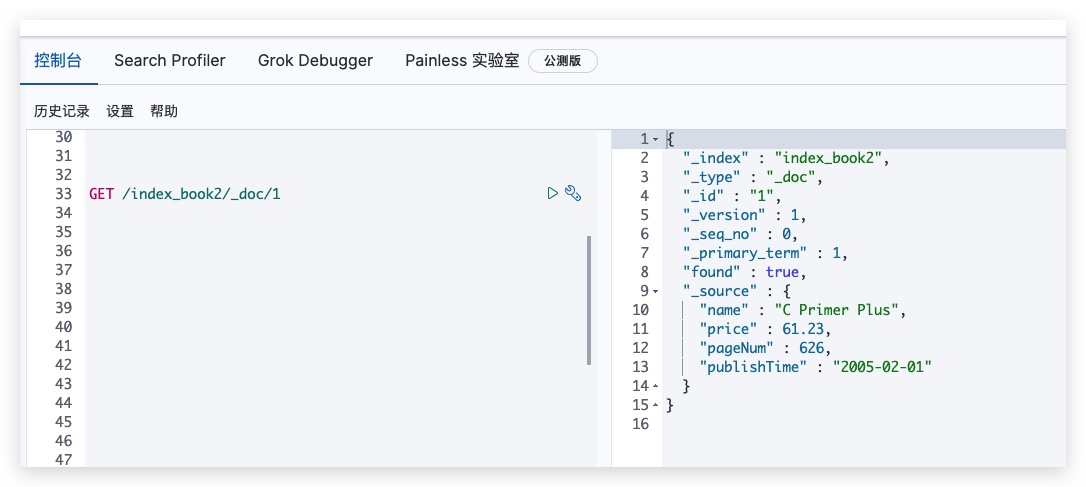
可通过如下方式发送GET请求,根据ID获取指定文档
1
2
|
GET /index_book2/_doc/1
|
Kibana测试结果如下所示
(部分)更新文档
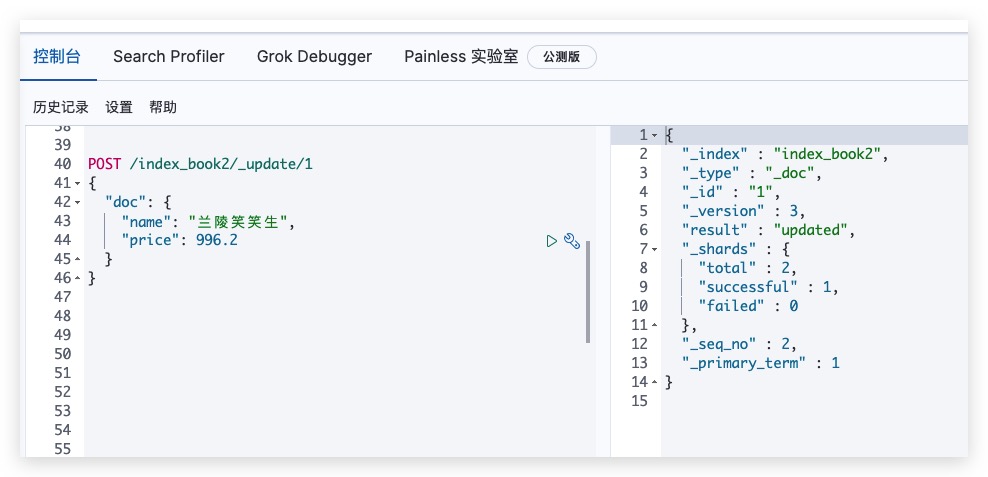
可通过如下方式发送POST请求,实现对指定文档的部分更新。值得一提的是,可通过添加文档的方式实现全部更新
1
2
3
4
5
6
7
8
|
POST /index_book2/_update/1
{
"doc": {
"name": "兰陵笑笑生",
"price": 996.2
}
}
|
Kibana测试结果如下所示
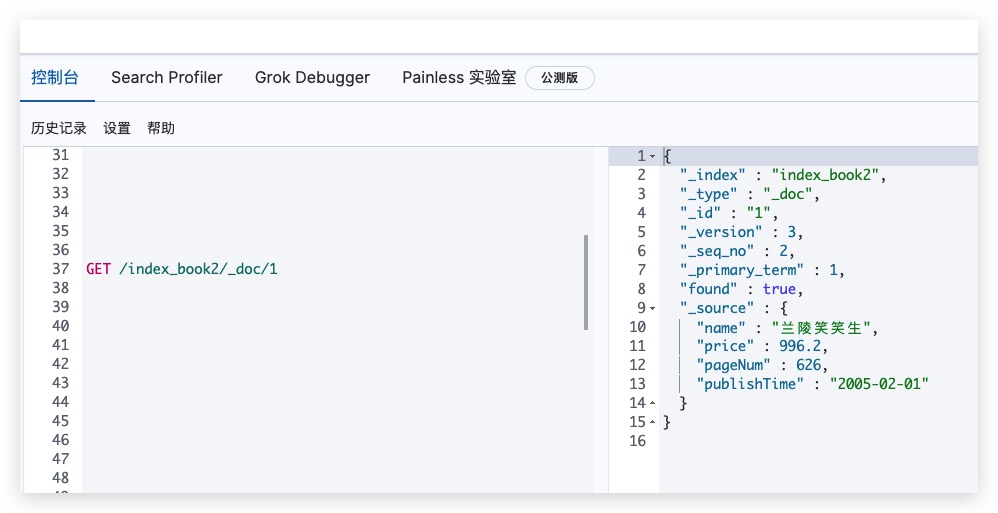
再次查看该文档,可发现已更新
删除文档
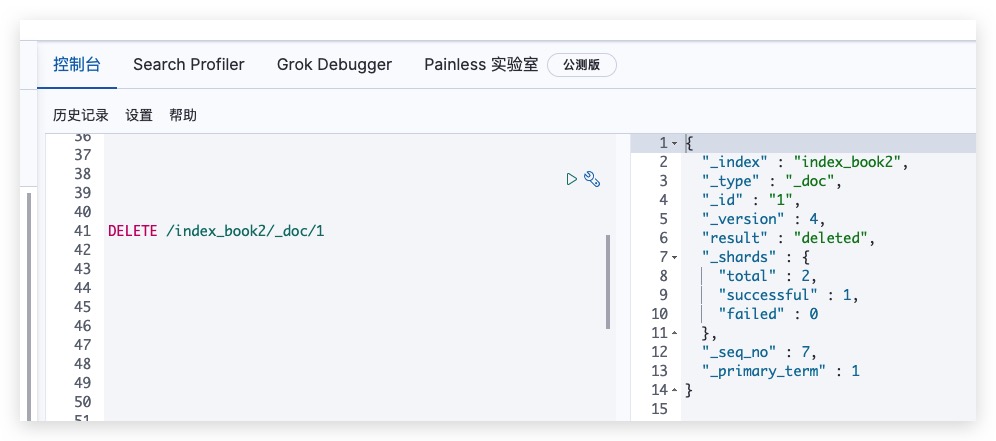
可通过如下方式发送DELETE请求,实现对指定文档的删除
1
2
|
DELETE /index_book2/_doc/1
|
Kibana测试结果如下所示
SpringBoot集成
SpringBoot集成过程中可以直接注入RestHighLevelClient使用,示例代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
|
@RunWith(SpringRunner.class)
@SpringBootTest(classes = SpringBoot1Application.class)
@FixMethodOrder(MethodSorters.NAME_ASCENDING)
public class TestESDoc {
@Autowired
private RestHighLevelClient restHighLevelClient;
private static String name = "index_book2";
@Test
public void test1AddDoc() throws IOException, ParseException {
Book book = Book.builder()
.name("C Primer Plus")
.price(61.23)
.pageNum(626)
.publishTime( new SimpleDateFormat("yyyy-MM-dd").parse("2005-02-01") )
.build();
String indexName = name;
IndexRequest request = new IndexRequest()
.index( indexName )
.id("1")
.source( JSON.toJSONString(book), XContentType.JSON );
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
RestStatus status = response.status();
System.out.println("\n===================== Test 1 =====================");
System.out.println("response: " + response);
System.out.println("status: " + status);
}
@Test
public void test2ExistDoc() throws IOException {
String indexName = name;
GetRequest request = new GetRequest(indexName, "1");
Boolean exist = restHighLevelClient.exists(request, RequestOptions.DEFAULT);
System.out.println("\n===================== Test 2 =====================");
System.out.println("doc exist: " + exist);
}
@Test
public void test3GetDoc() throws IOException {
String indexName = name;
String docId = "1";
GetRequest request = new GetRequest(indexName, docId);
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
Map map = response.getSource();
Long version = response.getVersion();
System.out.println("\n===================== Test 3 =====================");
System.out.println("map: " + map);
System.out.println("version: " + version);
}
@Test
public void test4UpdateDoc() throws IOException {
Book book = Book.builder()
.price(77.88)
.build();
String indexName = name;
String docId = "1";
UpdateRequest request = new UpdateRequest()
.index( indexName )
.id( docId )
.doc( JSON.toJSONString(book), XContentType.JSON);
UpdateResponse response = restHighLevelClient.update(request, RequestOptions.DEFAULT);
RestStatus status = response.status();
System.out.println("\n===================== Test 4 =====================");
System.out.println("response: " + response);
System.out.println("status: " + status);
}
@Test
public void test5DeleteDoc() throws IOException {
String indexName = name;
String docId = "1";
DeleteRequest request = new DeleteRequest()
.index( indexName )
.id( docId );
DeleteResponse response = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
RestStatus status = response.status();
System.out.println("\n===================== Test 5 =====================");
System.out.println("response: " + response);
System.out.println("status: " + status);
}
@Test
public void test6BatchAddDoc() throws IOException, ParseException {
List<Book> bookList = new LinkedList<>();
bookList.add( new Book("C++ Primer", 128.00, 838, null) );
bookList.add( new Book("Scala编程", 89.00, 492, null) );
AtomicLong atomicLong = new AtomicLong(10);
String indexName = name;
BulkRequest bulkRequest = new BulkRequest();
bookList.forEach( book -> {
String docId = atomicLong.toString();
IndexRequest indexRequest = new IndexRequest()
.index( indexName )
.id( docId )
.source( JSON.toJSONString(book), XContentType.JSON );
bulkRequest.add( indexRequest );
atomicLong.getAndIncrement();
});
BulkResponse response = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
Boolean success = !response.hasFailures();
System.out.println("\n===================== Test 6 =====================");
System.out.println("response: " + response);
System.out.println("success: " + success);
}
}
|
测试结果如下所示
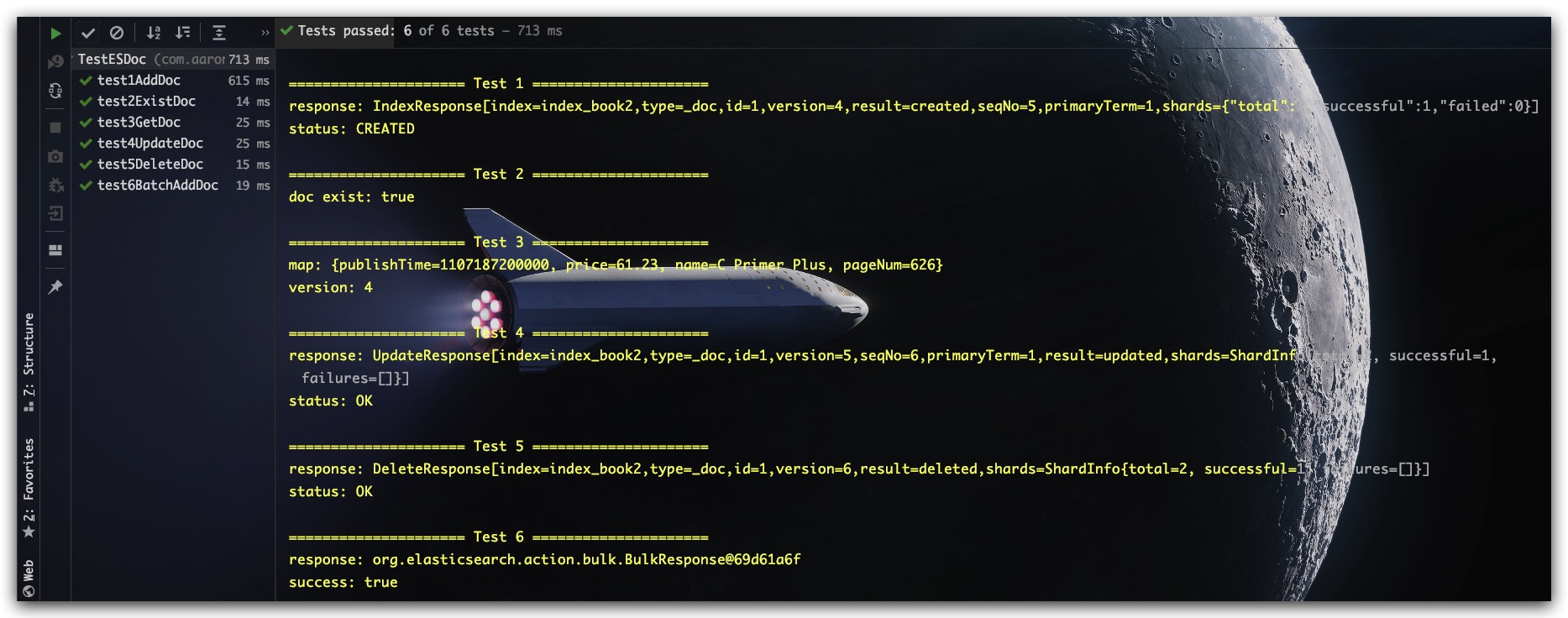
搜索文档
基于Kibana的索引数据可视化
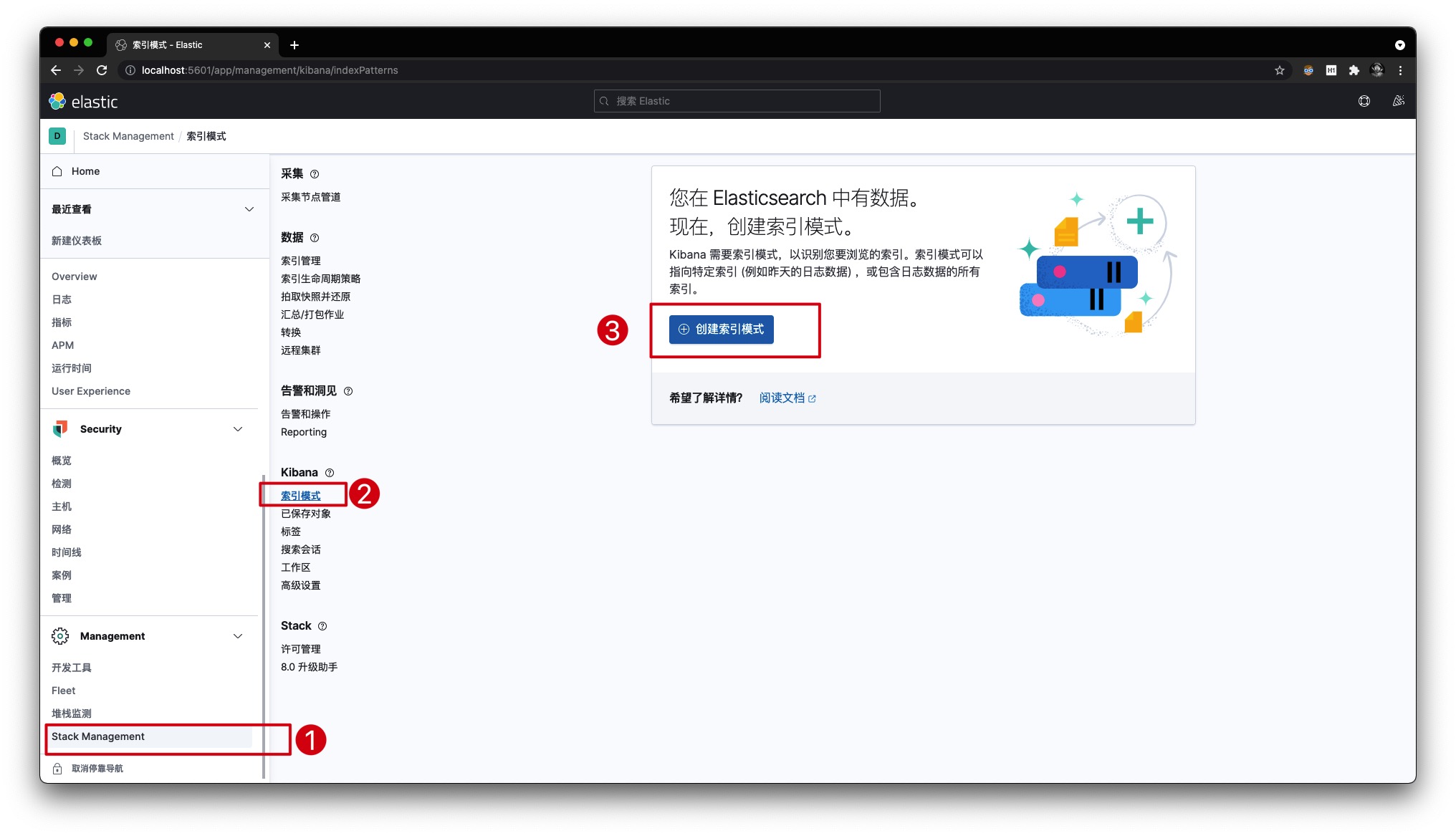
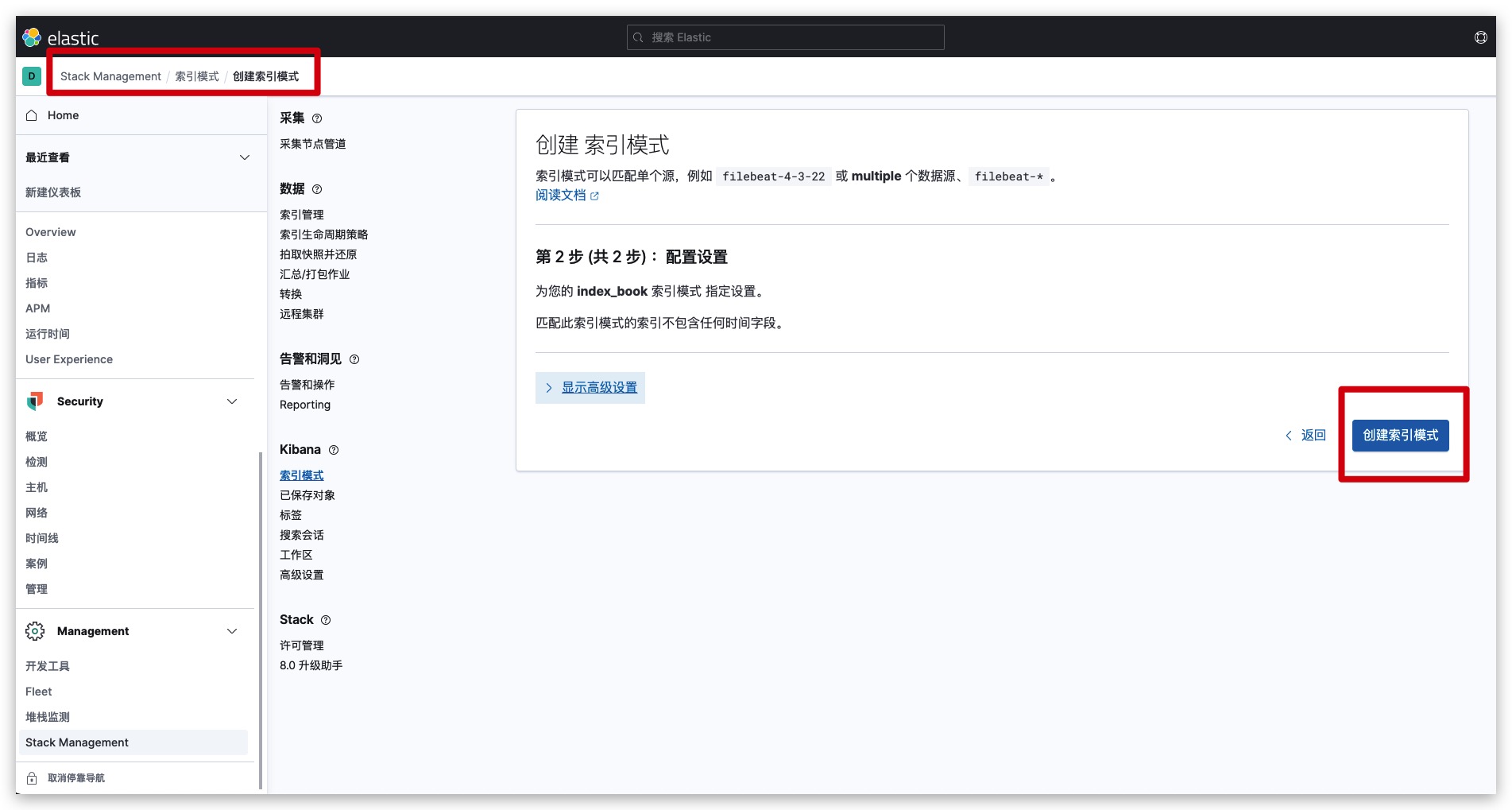
我们预先向index_book索引添加了一些数据,便于后续的文档搜索。这里我们通过Kibana查看该索引下的数据,首先按如下操作创建索引模式
同时定义索引模式的名称为index_book,通过绿框可以看到索引index_book被完全匹配了
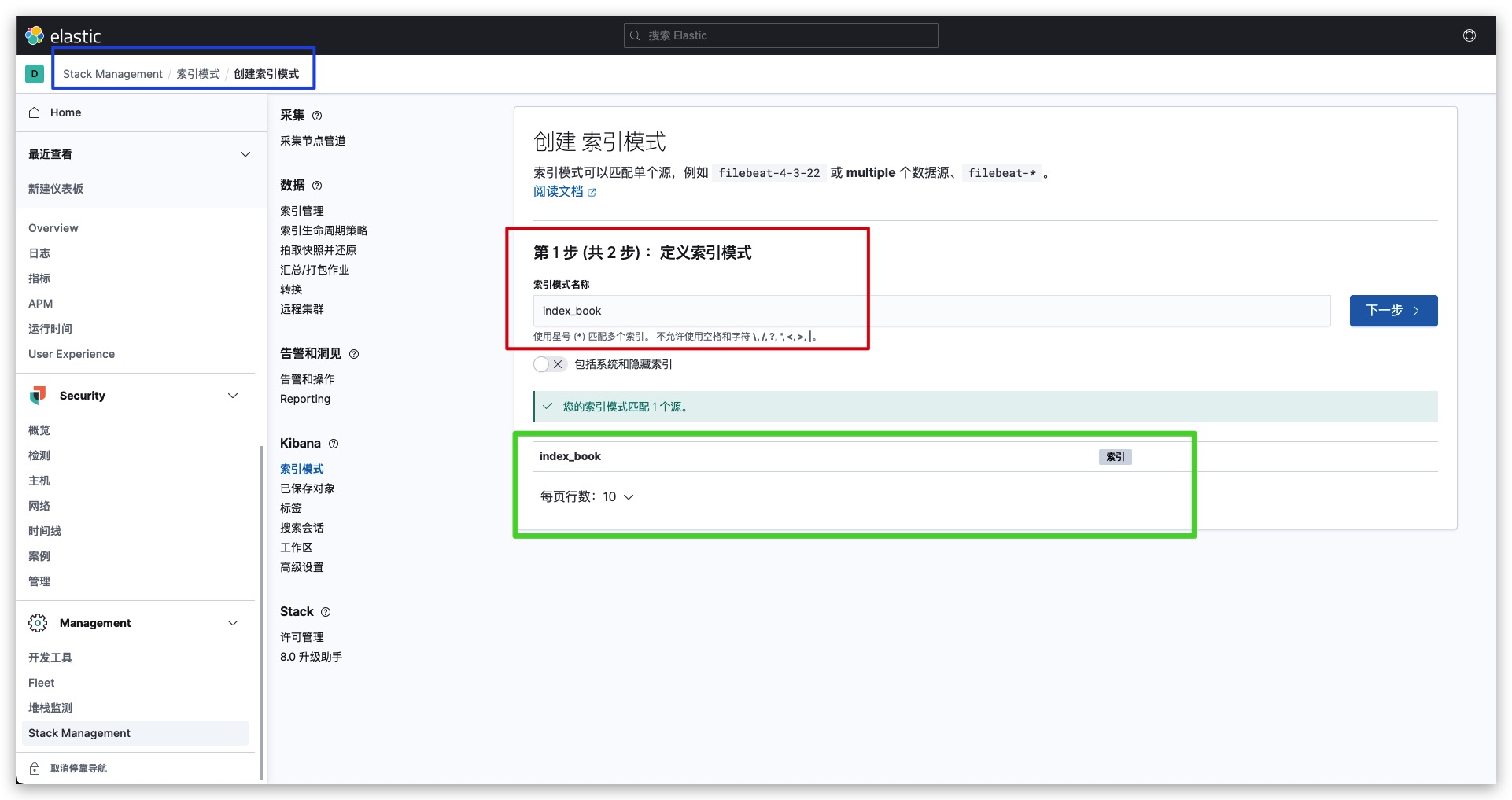
然后点击创建索引模式即可
现在我们通过Discover,选择名为index_book的索引模式。即可看到index_book索引下的所有文档数据
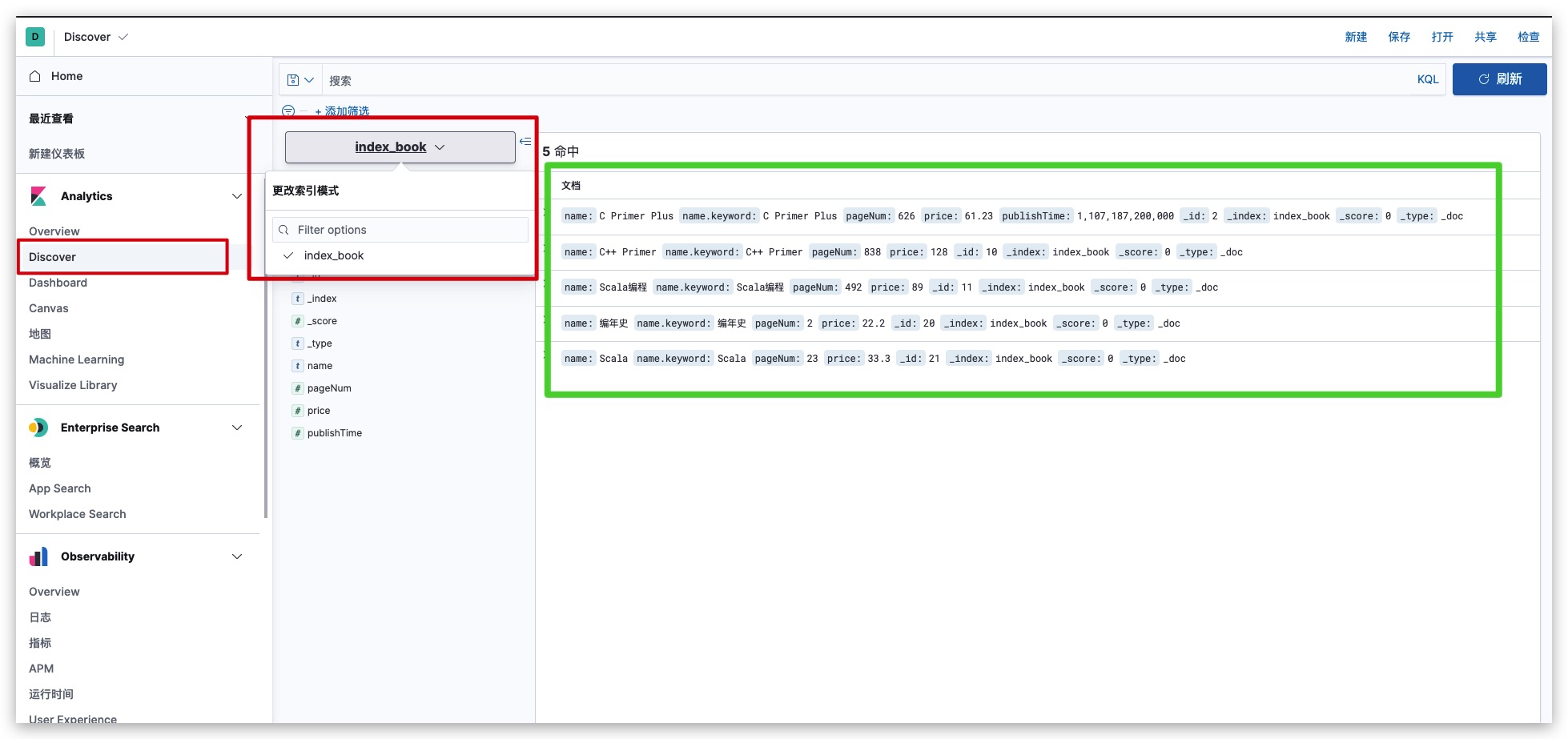
查询全部
RESTful API请求语法如下所示
1
2
3
4
5
6
7
|
POST /index_book/_search
{
"query": {
"match_all": {}
}
}
|
SpringBoot中示例代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
@RunWith(SpringRunner.class)
@SpringBootTest(classes = SpringBoot1Application.class)
public class TestESSearch {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Test
public void testMatchAll() throws IOException {
String indexName = "index_book";
QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
List<Book> resultList = gerSearchResult(indexName, queryBuilder);
resultList.forEach(System.out::println);
}
public List<Book> gerSearchResult(String indexName, QueryBuilder queryBuilder) throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(queryBuilder);
SearchRequest request = new SearchRequest()
.indices(indexName)
.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
List<Book> list = new LinkedList<>();
for (SearchHit searchHit : hits) {
String jsonStr = searchHit.getSourceAsString();
Book book = JSON.parseObject(jsonStr, Book.class);
list.add(book);
}
return list;
}
}
|
测试结果如下,符合预期

分页查询
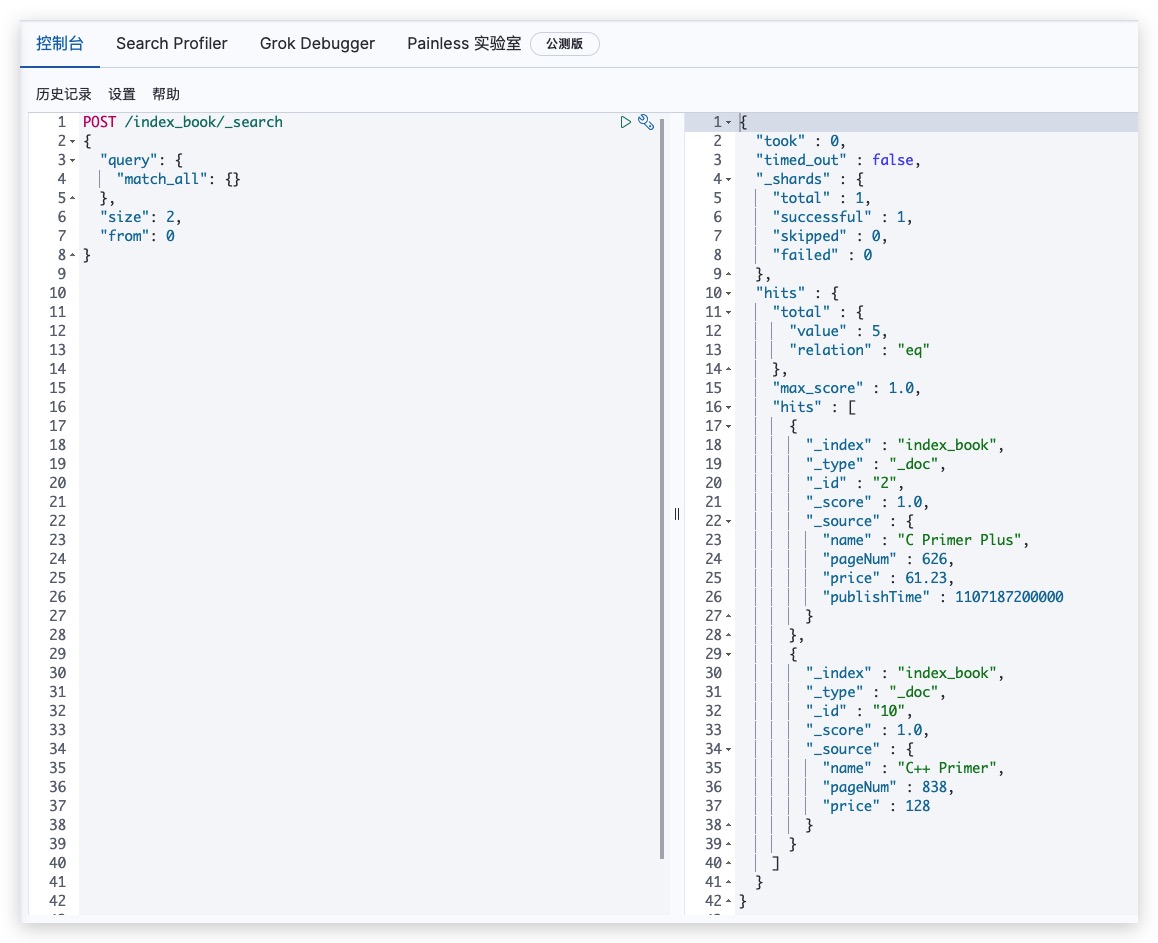
对于分页查询来说,RESTful API请求语法如下所示
1
2
3
4
5
6
7
8
9
|
POST /index_book/_search
{
"query": {
"match_all": {}
},
"size": 2,
"from": 0
}
|
测试结果如下所示,符合预期
SpringBoot中示例代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
@Test
public void testMatchAllByPage() throws IOException {
String indexName = "index_book";
QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(queryBuilder)
.size(2)
.from(0);
SearchRequest request = new SearchRequest()
.indices(indexName)
.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
List<Book> resultList = new LinkedList<>();
for (SearchHit searchHit : hits) {
String jsonStr = searchHit.getSourceAsString();
Book book = JSON.parseObject(jsonStr, Book.class);
resultList.add(book);
}
resultList.forEach(System.out::println);
}
|
测试结果如下所示,符合预期

模糊查询
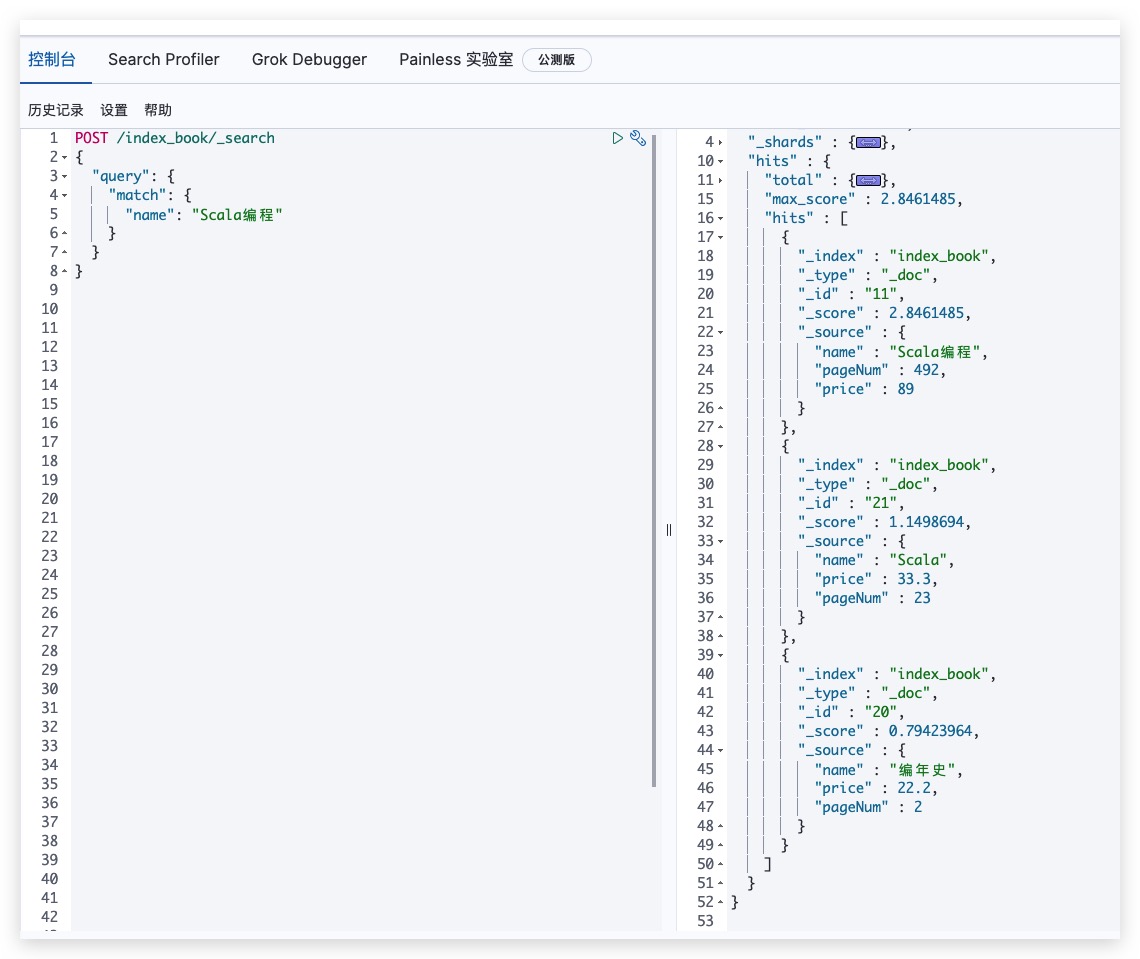
对于模糊查询来说,我们分别测试两个例子
1
2
3
4
5
6
7
8
9
|
POST /index_book/_search
{
"query": {
"match": {
"name": "Scala编程"
}
}
}
|
测试结果如下所示
1
2
3
4
5
6
7
8
9
|
POST /index_book/_search
{
"query": {
"match": {
"name.keyword": "Scala编程"
}
}
}
|
测试结果如下所示
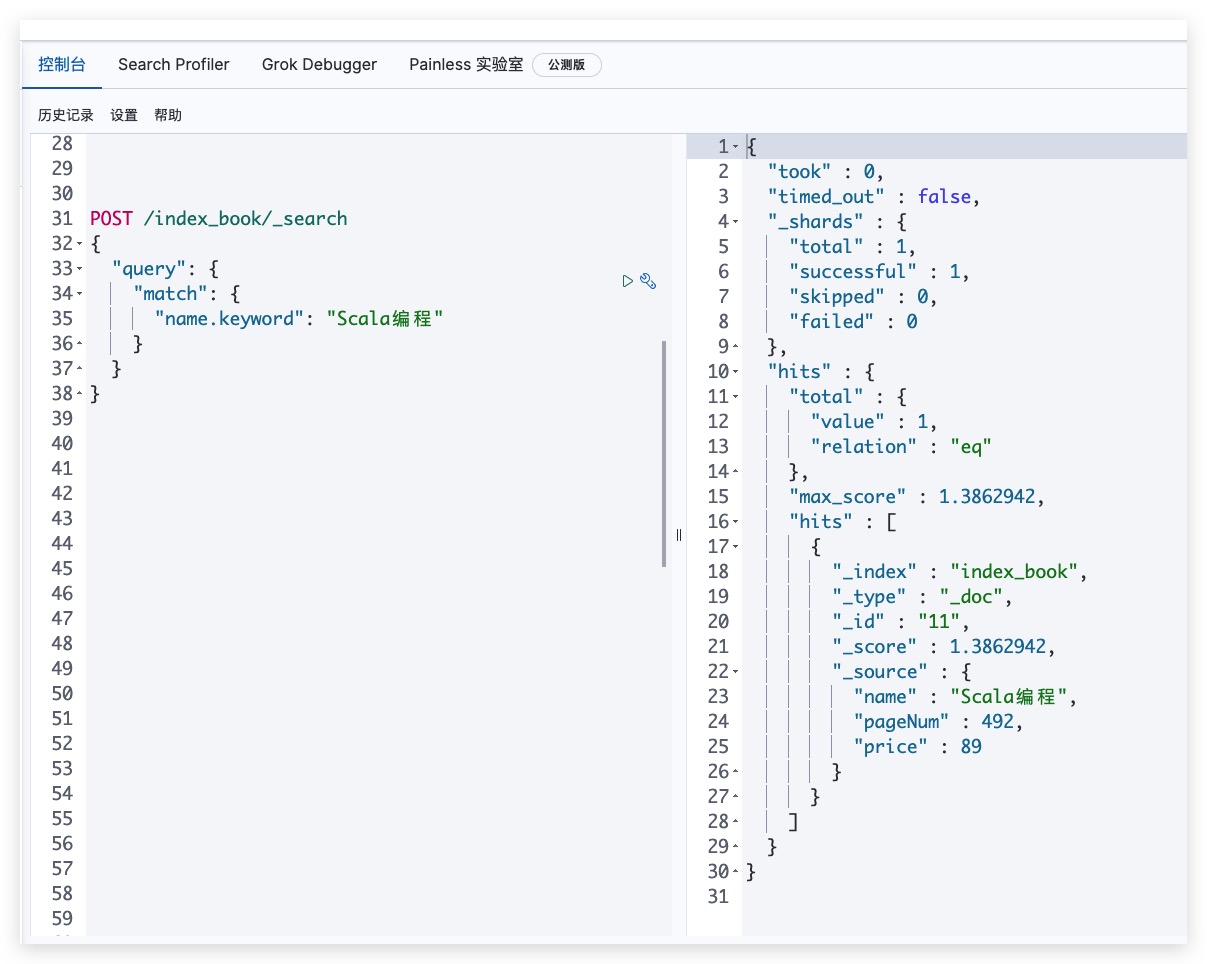
通过对比上述两个例子我们可以发现,name字段(text类型)的查询条件事实上会被进行分词处理。即 Scala编程 在ES Standard分词器下会拆分为scala、编、程。故文档的name字段只要满足任一个分词结果即会被匹配;而对于name.keyword字段而言,其由于是keyword类型,ES不会对其进行分词(包括文档数据和搜索条件),故只会查找到一条完全匹配的文档数据。SpringBoot下示例代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
@Test
public void testMatch1() throws IOException {
System.out.println("\n=============== testMatch1 ===============");
String indexName = "index_book";
QueryBuilder queryBuilder = QueryBuilders.matchQuery("name", "Scala编程");
List<Book> resultList = gerSearchResult(indexName, queryBuilder);
resultList.forEach(System.out::println);
}
@Test
public void testMatch2() throws IOException {
System.out.println("\n=============== testMatch2 ===============");
String indexName = "index_book";
QueryBuilder queryBuilder = QueryBuilders.matchQuery("name.keyword", "Scala编程");
List<Book> resultList = gerSearchResult(indexName, queryBuilder);
resultList.forEach(System.out::println);
}
|
测试结果如下,符合预期
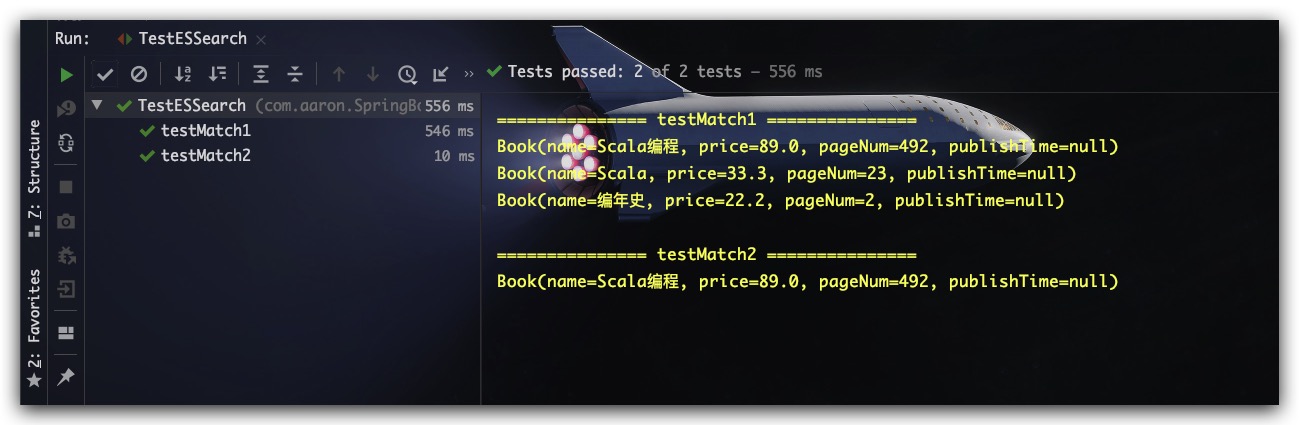
布尔查询
对于布尔查询,其支持的属性有must、should、must_not,类似于SQL中的and、or、not逻辑操作。与此同时,其还支持filter属性,可用于快速过滤掉不符合filter条件的文档。值得一提的是,filter属性之所以比must属性更快,是因为前者不计算分数而后者则会参与分数计算。该RESTful API请求示例如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
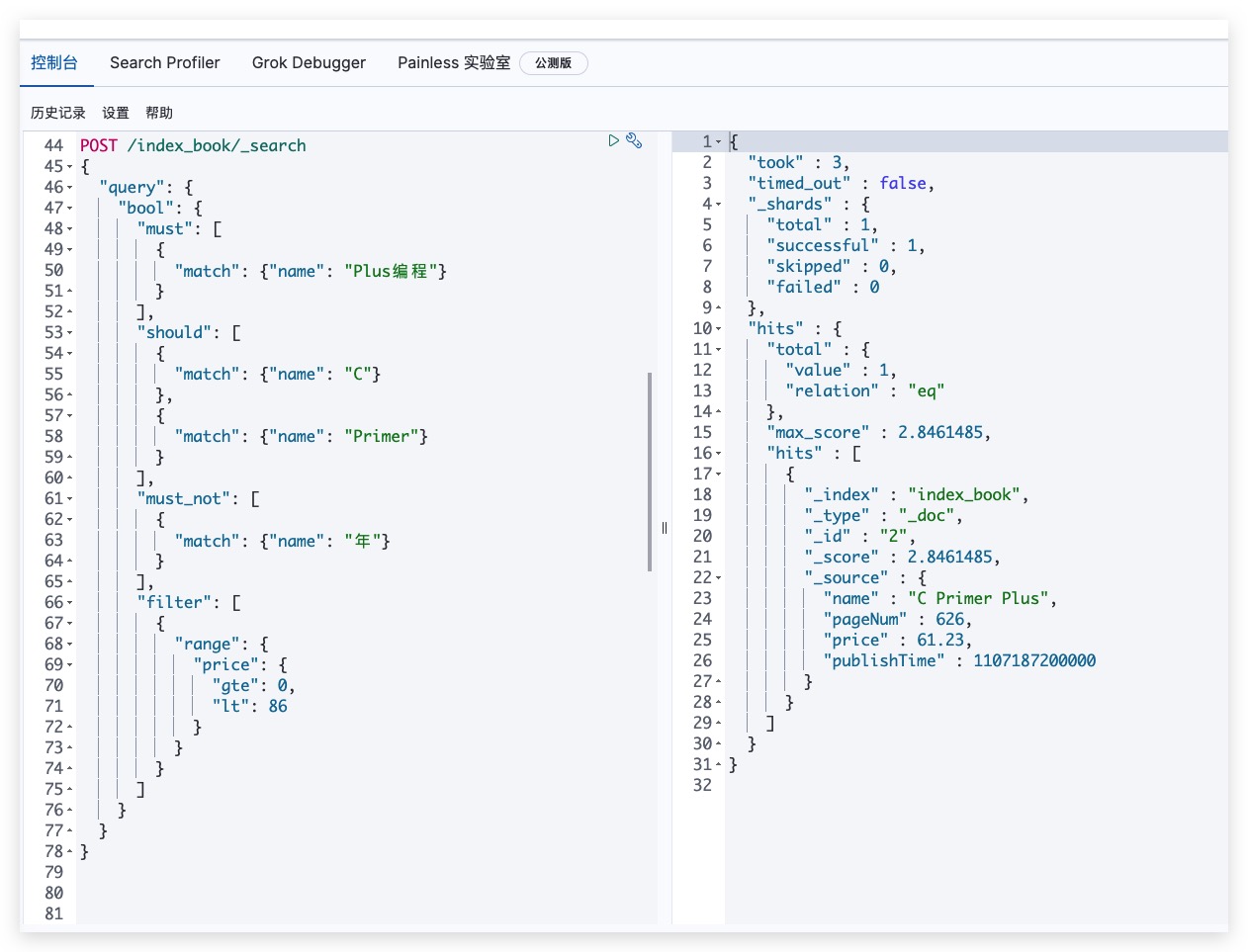
| POST /index_book/_search
{
"query": {
"bool": {
"must": [
{
"match": {"name": "Plus编程"}
}
],
"should": [
{
"match": {"name": "C"}
},
{
"match": {"name": "Primer"}
}
],
"must_not": [
{
"match": {"name": "年"}
}
],
"filter": [
{
"range": {
"price": {
"gte": 0,
"lt": 86
}
}
}
]
}
}
}
|
测试结果如下,符合预期
SpringBoot下示例代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@Test
public void testBool() throws IOException {
String indexName = "index_book";
QueryBuilder condition1 = QueryBuilders.matchQuery("name", "Plus编程");
QueryBuilder condition2 = QueryBuilders.matchQuery("name", "C");
QueryBuilder condition3 = QueryBuilders.matchQuery("name", "Primer");
QueryBuilder condition4 = QueryBuilders.matchQuery("name", "年");
QueryBuilder condition5 = QueryBuilders.rangeQuery("price")
.gte(0)
.lt(86);
QueryBuilder queryBuilder = QueryBuilders.boolQuery()
.must( condition1 )
.should( condition2 )
.should( condition3 )
.mustNot( condition4 )
.filter( condition5 );
List<Book> resultList = gerSearchResult(indexName, queryBuilder);
resultList.forEach(System.out::println);
}
|
测试结果如下,符合预期
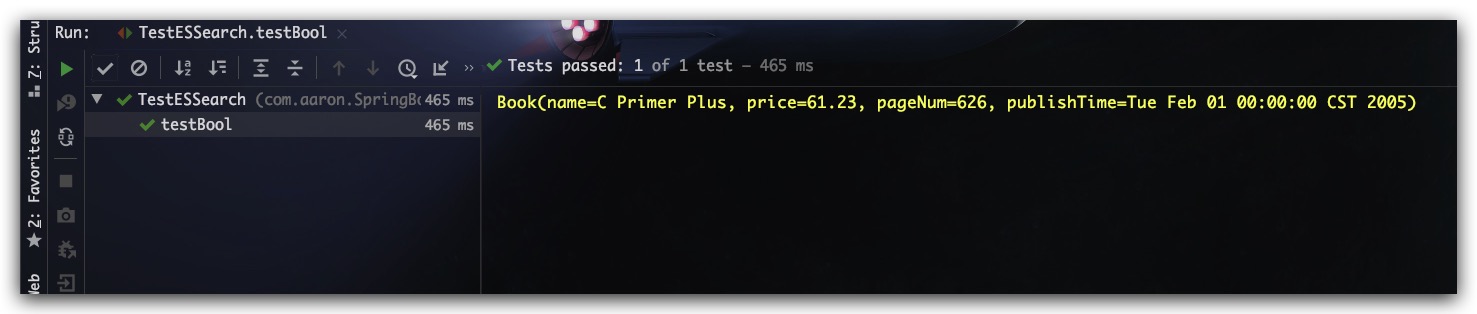
ik分词器
前面我们提到 Scala编程 在ES Standard分词器下会拆分为scala、编、程。事实上,ES也提供了RESTful API来进行分析
1
2
3
4
5
6
|
POST /_analyze
{
"analyzer": "standard",
"text": "Scala编程"
}
|
测试结果如下,符合预期
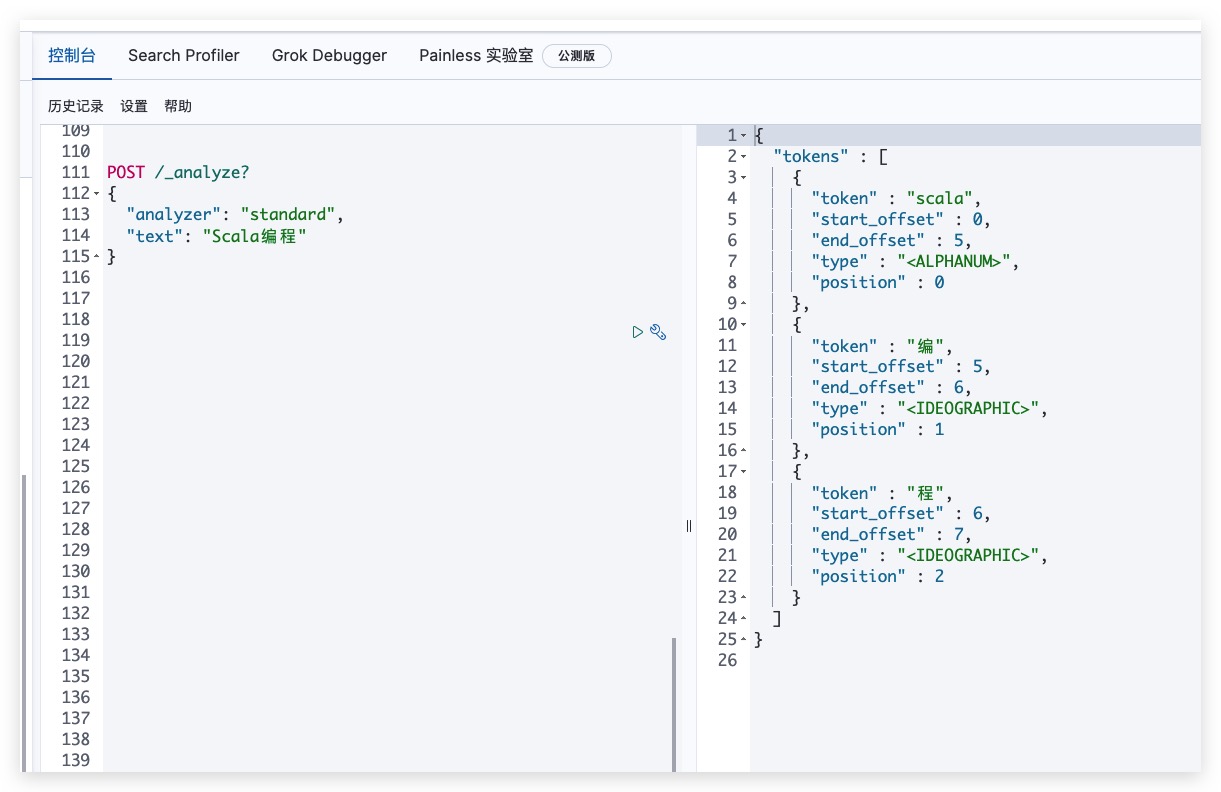
显然standard分词器对中文分词并不友好,为此这里我们安装ik分词器。值得一提的是,ik分词器版本需和ES版本保持一致。相关命令如下所示
1
2
3
4
5
6
7
8
9
10
|
docker exec -it myES /bin/bash
cd plugins
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.0/elasticsearch-analysis-ik-7.12.0.zip
exit
docker restart myES
|
操作过程如下所示
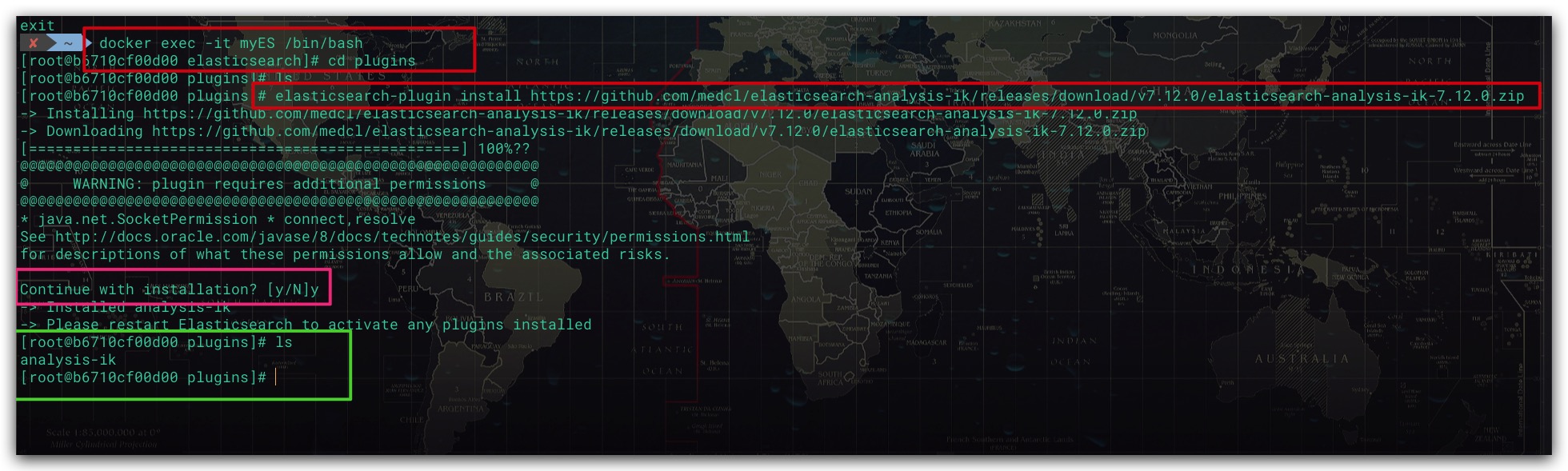
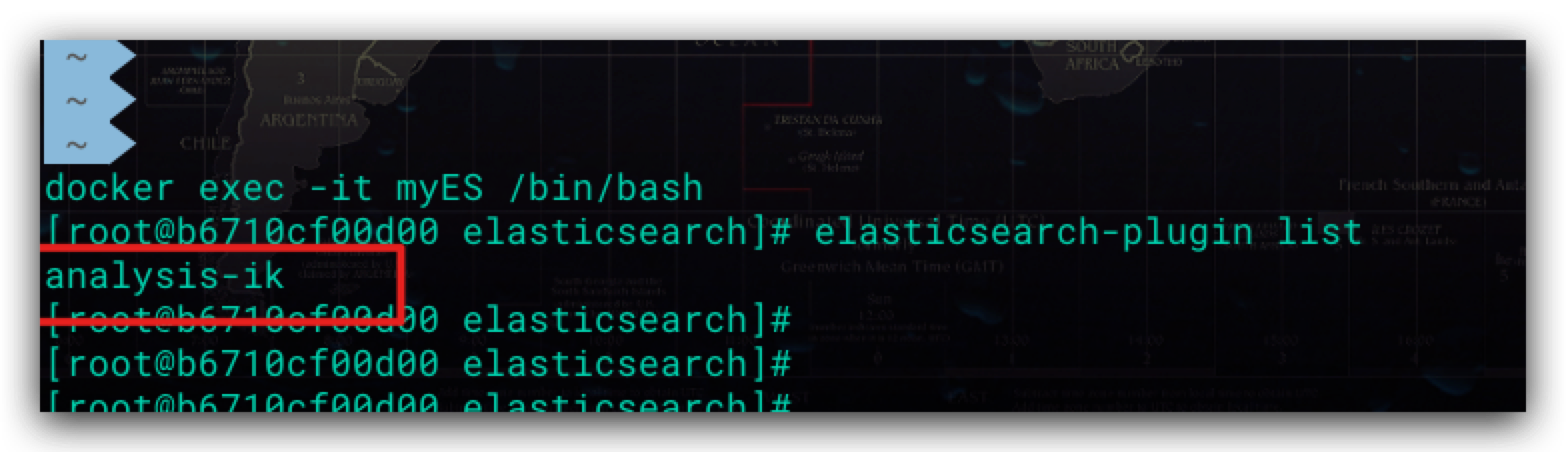
安装ik分词器并重启ES容器后,可通过如下命令验证是否安装成功
1
2
|
elasticsearch-plugin list
|
符合预期
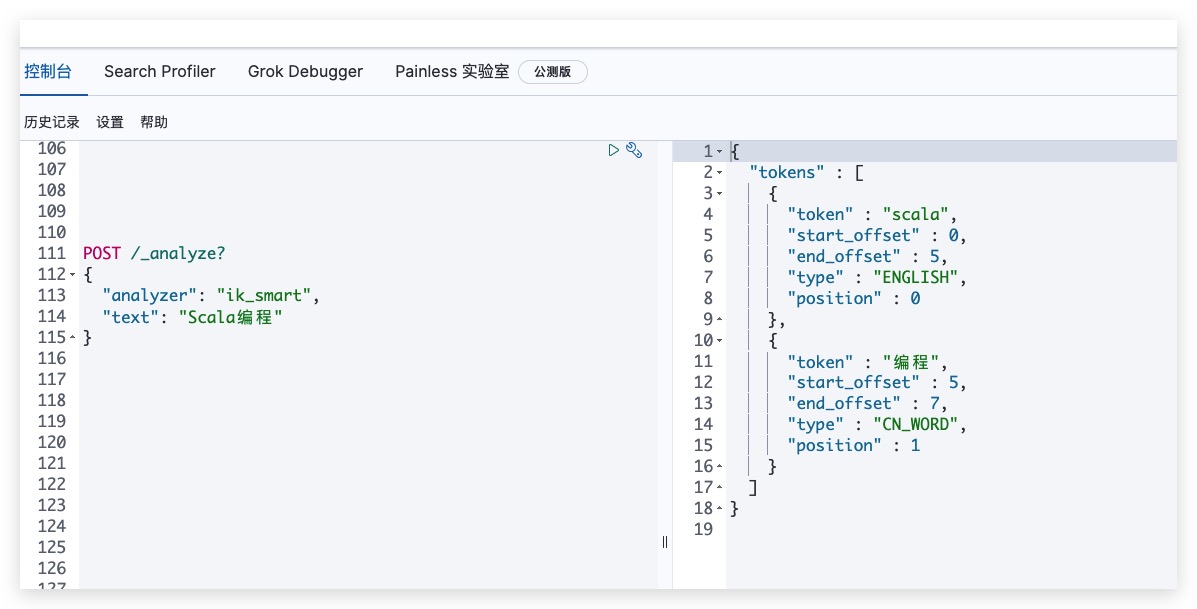
验证ik分词器的效果
1
2
3
4
5
6
|
POST /_analyze
{
"analyzer": "ik_smart",
"text": "Scala编程"
}
|
测试结果如下,符合预期
参考文献
- Elasticsearch实战 Radu Gheorghe著
