本文介绍Redis Cluster模式下集群的可用性

搭建集群
利用Docker Compose搭建一个3主3从的Redis Cluster集群,docker-compose.yml文件如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
|
version: '3.8'
services:
Redis-Service-1:
image: redis:7.0
container_name: node-1
command: [ "redis-server", "/etc/redis/redis.conf" ]
ports:
- "6371:6379"
- "16371:16379"
volumes:
- /Users/zgh/Docker/RedisCluster_3M3S/RedisConf/redis.conf:/etc/redis/redis.conf
networks:
redis_cluster_3m3s_net:
ipv4_address: 120.120.120.11
Redis-Service-2:
image: redis:7.0
container_name: node-2
command: [ "redis-server", "/etc/redis/redis.conf" ]
ports:
- "6372:6379"
- "16372:16379"
volumes:
- /Users/zgh/Docker/RedisCluster_3M3S/RedisConf/redis.conf:/etc/redis/redis.conf
networks:
redis_cluster_3m3s_net:
ipv4_address: 120.120.120.12
Redis-Service-3:
image: redis:7.0
container_name: node-3
command: [ "redis-server", "/etc/redis/redis.conf" ]
ports:
- "6373:6379"
- "16373:16379"
volumes:
- /Users/zgh/Docker/RedisCluster_3M3S/RedisConf/redis.conf:/etc/redis/redis.conf
networks:
redis_cluster_3m3s_net:
ipv4_address: 120.120.120.13
Redis-Service-4:
image: redis:7.0
container_name: node-4
command: [ "redis-server", "/etc/redis/redis.conf" ]
ports:
- "6374:6379"
- "16374:16379"
volumes:
- /Users/zgh/Docker/RedisCluster_3M3S/RedisConf/redis.conf:/etc/redis/redis.conf
networks:
redis_cluster_3m3s_net:
ipv4_address: 120.120.120.14
Redis-Service-5:
image: redis:7.0
container_name: node-5
command: [ "redis-server", "/etc/redis/redis.conf" ]
ports:
- "6375:6379"
- "16375:16379"
volumes:
- /Users/zgh/Docker/RedisCluster_3M3S/RedisConf/redis.conf:/etc/redis/redis.conf
networks:
redis_cluster_3m3s_net:
ipv4_address: 120.120.120.15
Redis-Service-6:
image: redis:7.0
container_name: node-6
command: [ "redis-server", "/etc/redis/redis.conf" ]
ports:
- "6376:6379"
- "16376:16379"
volumes:
- /Users/zgh/Docker/RedisCluster_3M3S/RedisConf/redis.conf:/etc/redis/redis.conf
networks:
redis_cluster_3m3s_net:
ipv4_address: 120.120.120.16
networks:
redis_cluster_3m3s_net:
ipam:
config:
- subnet: 120.120.120.0/24
|
Redis指定版本的配置文件redis.conf可通过下述链接下载对应版本的安装包后解压后获取
1
| http://download.redis.io/releases/
|
修改Redis配置文件redis.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| ...
protected-mode no
port 6379
daemonize no
databases 5
masterauth "52996"
requirepass 52996
cluster-enabled yes
cluster-require-full-coverage yes
...
|
这里对于集群中的6个节点,均使用上述同一个配置文件。目录结构如下所示
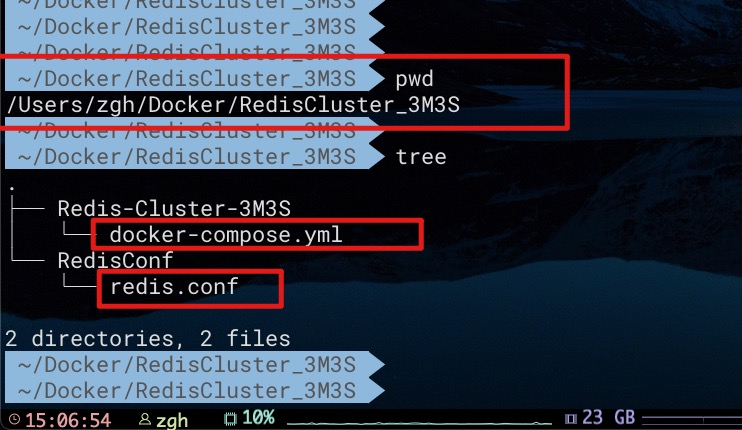
现在,进行docker-compose.yml文件所在目录,利用Docker Compose命令创建容器
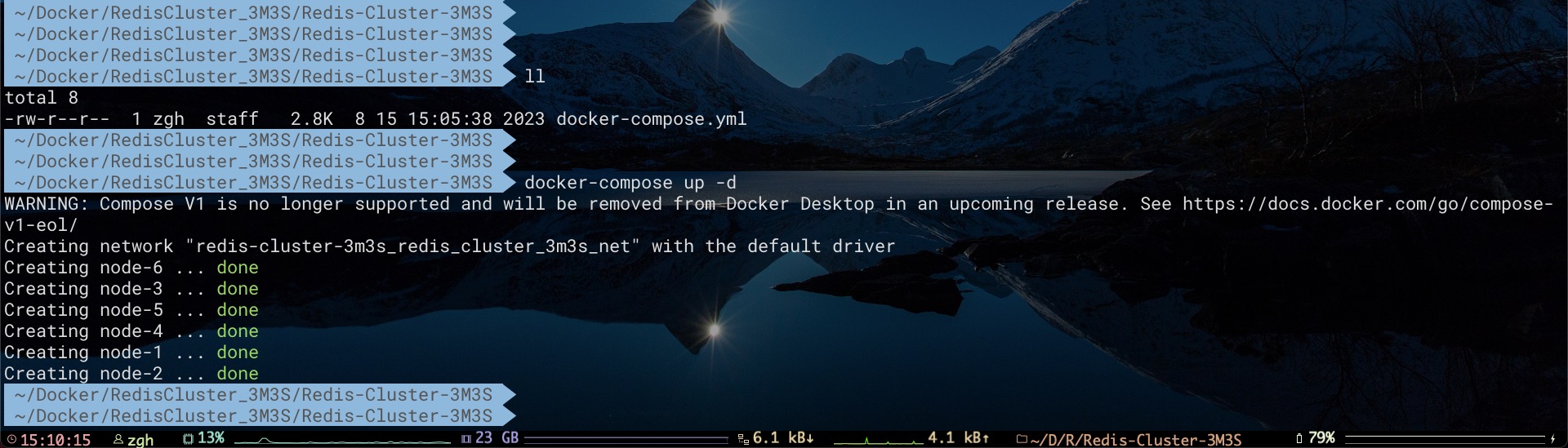
执行下述命令组建集群
1
2
3
4
5
6
| docker exec -it node-1 \
redis-cli -p 6379 -a 52996 --cluster create \
120.120.120.11:6379 120.120.120.12:6379 \
120.120.120.13:6379 120.120.120.14:6379 \
120.120.120.15:6379 120.120.120.16:6379 \
--cluster-replicas 1
|
命令输出结果如下所示,其中在分配好每个节点的槽范围后,需要输入yes进行确认,以便完成集群构建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 120.120.120.15:6379 to 120.120.120.11:6379
Adding replica 120.120.120.16:6379 to 120.120.120.12:6379
Adding replica 120.120.120.14:6379 to 120.120.120.13:6379
M: 375df7b2d433e5deeb790a665b4c71bf05351d39 120.120.120.11:6379
slots:[0-5460] (5461 slots) master
M: 9a6d9f2b8bcd3194e9aa6c3b49981b2c06cc4c2a 120.120.120.12:6379
slots:[5461-10922] (5462 slots) master
M: ee7167cfb5db69f4ade001433d93b103a5083410 120.120.120.13:6379
slots:[10923-16383] (5461 slots) master
S: 274433887a0d2e6d16c481d6d1f5e966b1394e11 120.120.120.14:6379
replicates ee7167cfb5db69f4ade001433d93b103a5083410
S: 442b5c8ed244a51150f3926992e34aa9ebee32b1 120.120.120.15:6379
replicates 375df7b2d433e5deeb790a665b4c71bf05351d39
S: a9cdb504940f70f55e1421999573beae90f38653 120.120.120.16:6379
replicates 9a6d9f2b8bcd3194e9aa6c3b49981b2c06cc4c2a
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 120.120.120.11:6379)
M: 375df7b2d433e5deeb790a665b4c71bf05351d39 120.120.120.11:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: a9cdb504940f70f55e1421999573beae90f38653 120.120.120.16:6379
slots: (0 slots) slave
replicates 9a6d9f2b8bcd3194e9aa6c3b49981b2c06cc4c2a
S: 442b5c8ed244a51150f3926992e34aa9ebee32b1 120.120.120.15:6379
slots: (0 slots) slave
replicates 375df7b2d433e5deeb790a665b4c71bf05351d39
S: 274433887a0d2e6d16c481d6d1f5e966b1394e11 120.120.120.14:6379
slots: (0 slots) slave
replicates ee7167cfb5db69f4ade001433d93b103a5083410
M: ee7167cfb5db69f4ade001433d93b103a5083410 120.120.120.13:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 9a6d9f2b8bcd3194e9aa6c3b49981b2c06cc4c2a 120.120.120.12:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
|
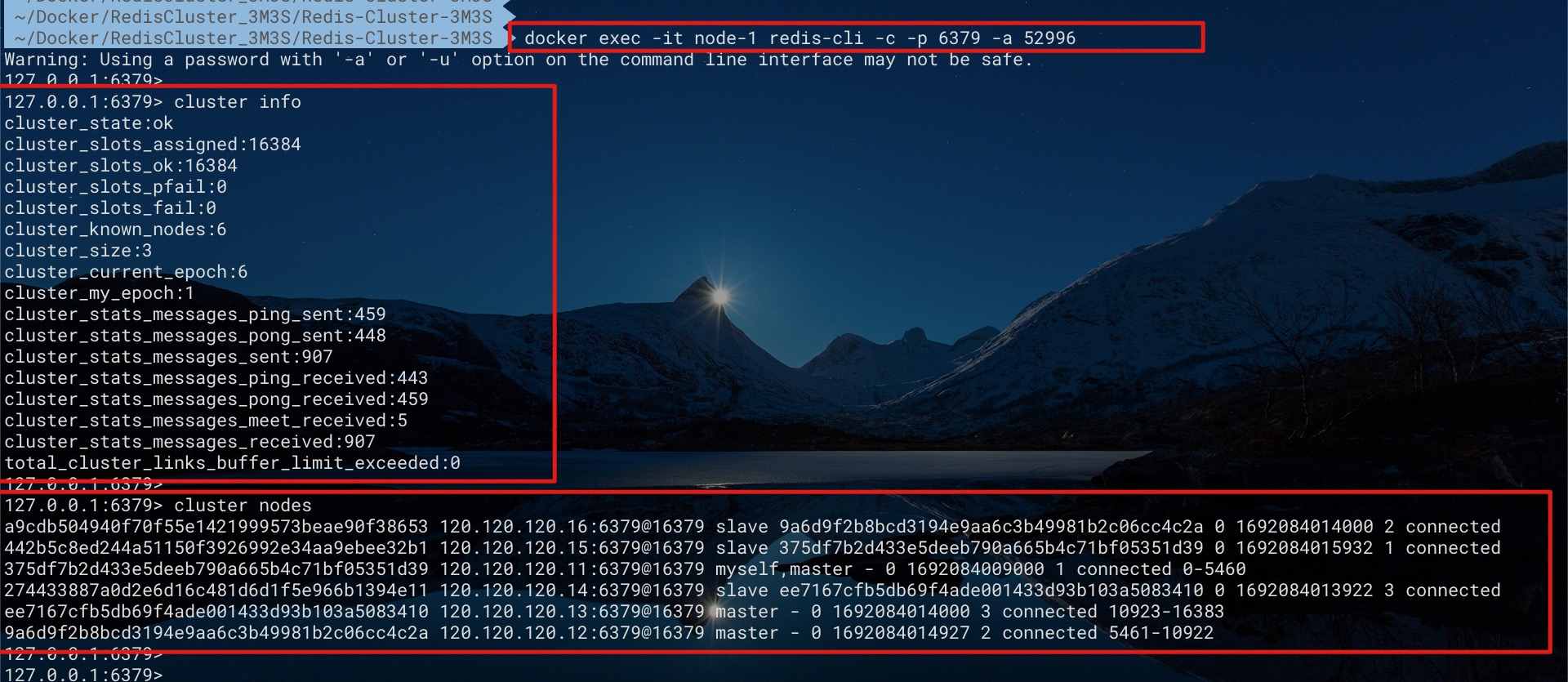
此时我们即可在任意一个节点容器中执行redis-cli命令来访问集群了
1
2
3
4
5
6
7
8
|
docker exec -it node-1 redis-cli -c -p 6379 -a 52996
cluster info
cluster nodes
|
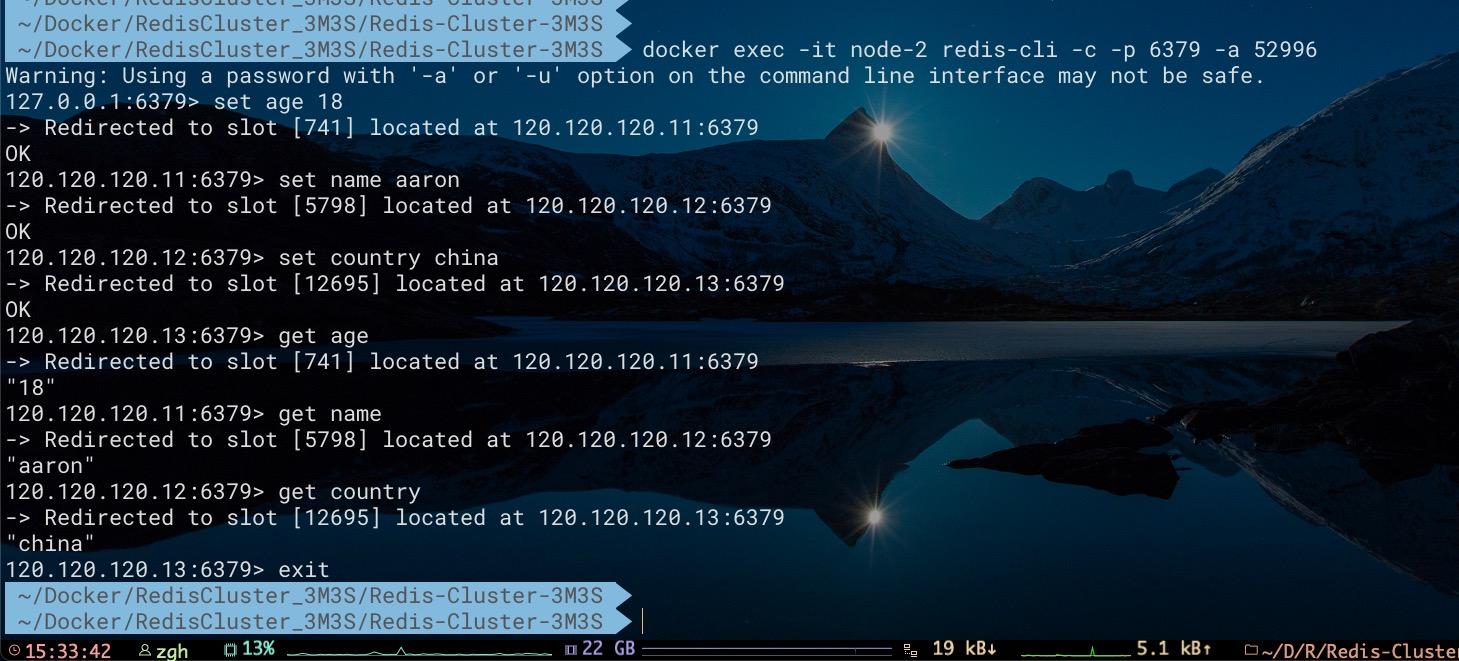
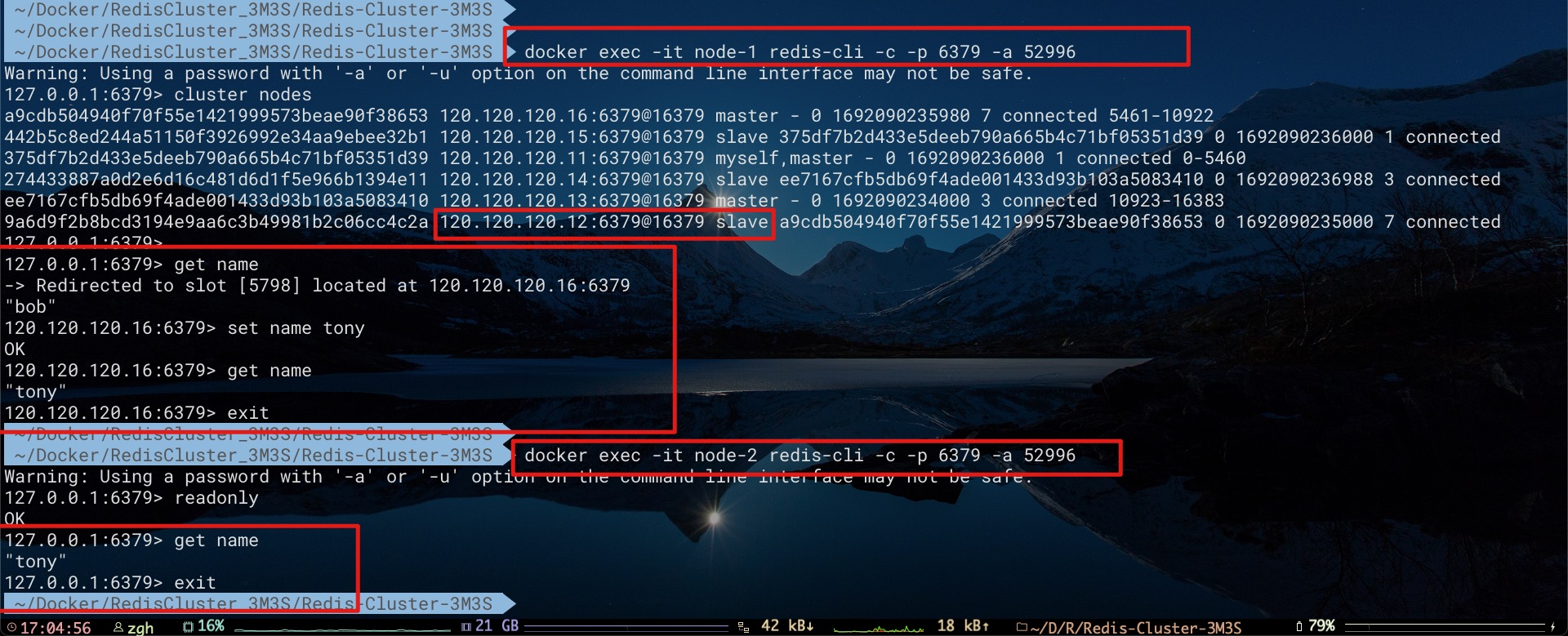
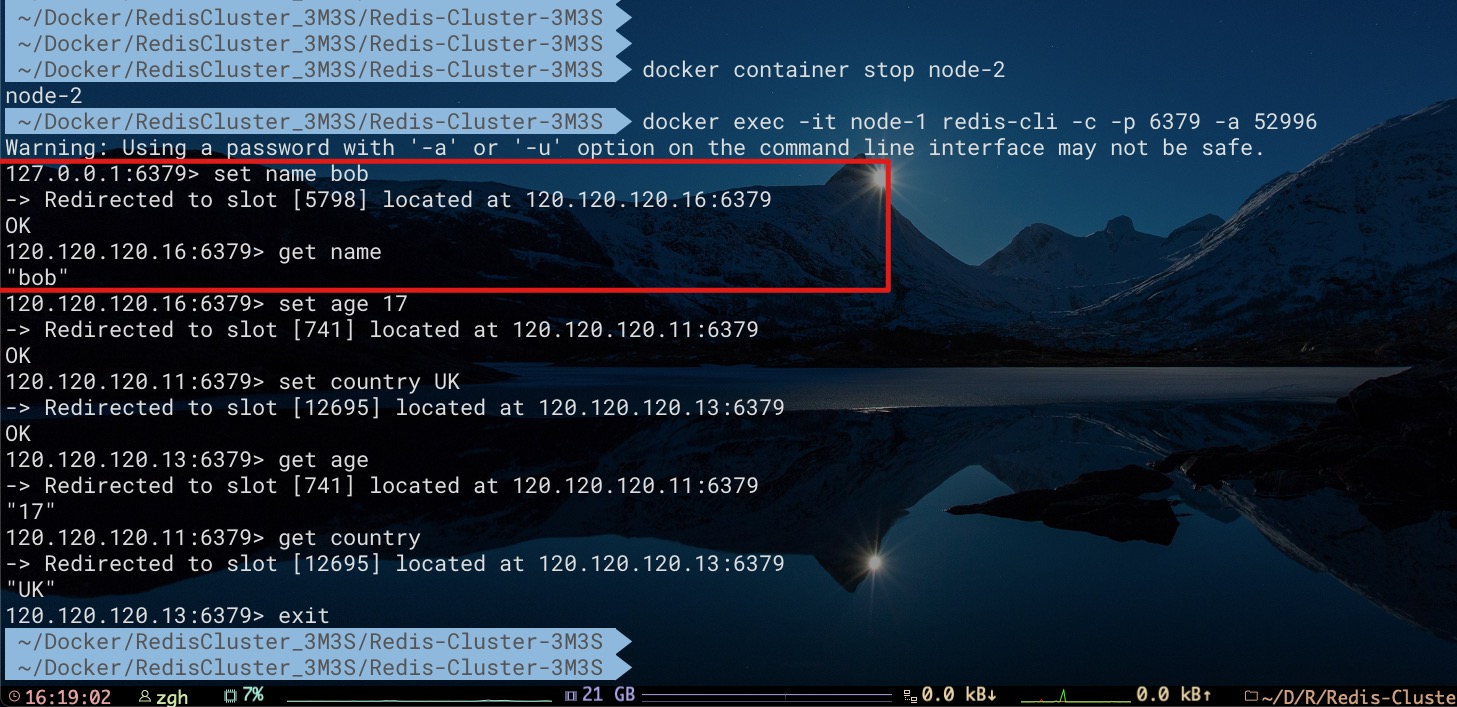
现在向集群中添加key分别为age、name、country的数据。不难看出其分别存储到Master节点node1、node2、node3当中
如果期望从某Slave节点中访问其所存储的相应数据,需先发送readonly命令。如下所示
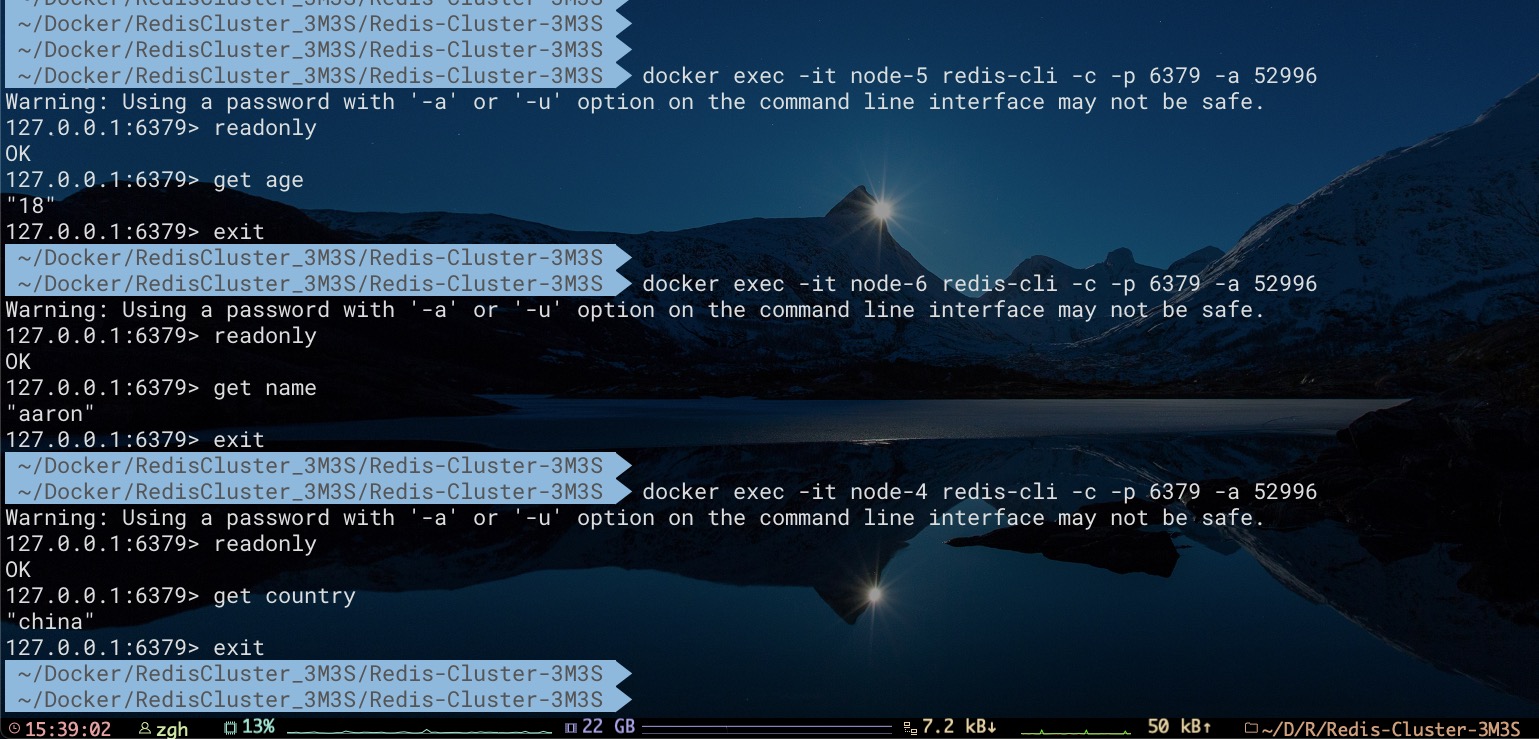
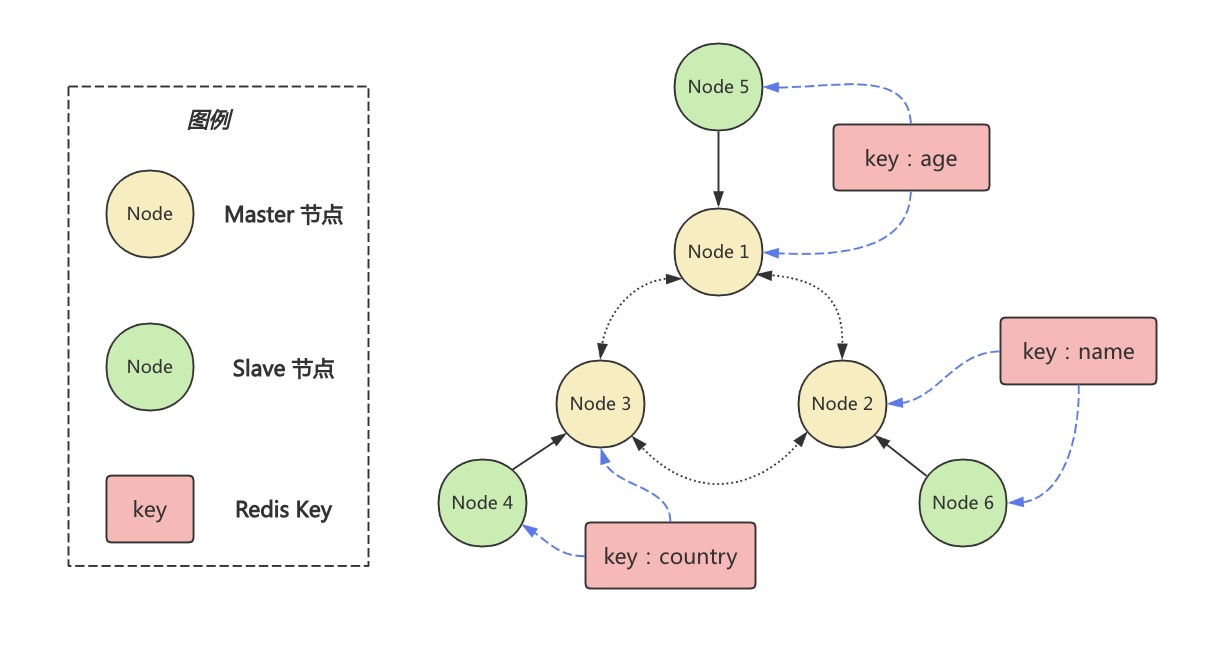
下文将会利用该集群对Redis Cluster的可用性进行探索。至此我们不难得出该集群的拓扑结构关系及部分key的分布,如下所示
Master下线
一个Master下线
Redis Cluster模式下,当某个Master被判定下线后,会进行故障转移Failover。基本流程如下:
- 从已经下线的Master节点所属的所有Slave节点中,挑选一个Slave节点作为新Master
- 让已经下线的Master节点所属的所有Slave节点,指向新Master。即从新Master进行复制
- 将已经下线的Master节点设置为新Master的从节点。这样当这个已经下线的Master节点后续重新上线时,其就会成为新Master的从节点。以避免某个槽中同时出现两个主节点的情形
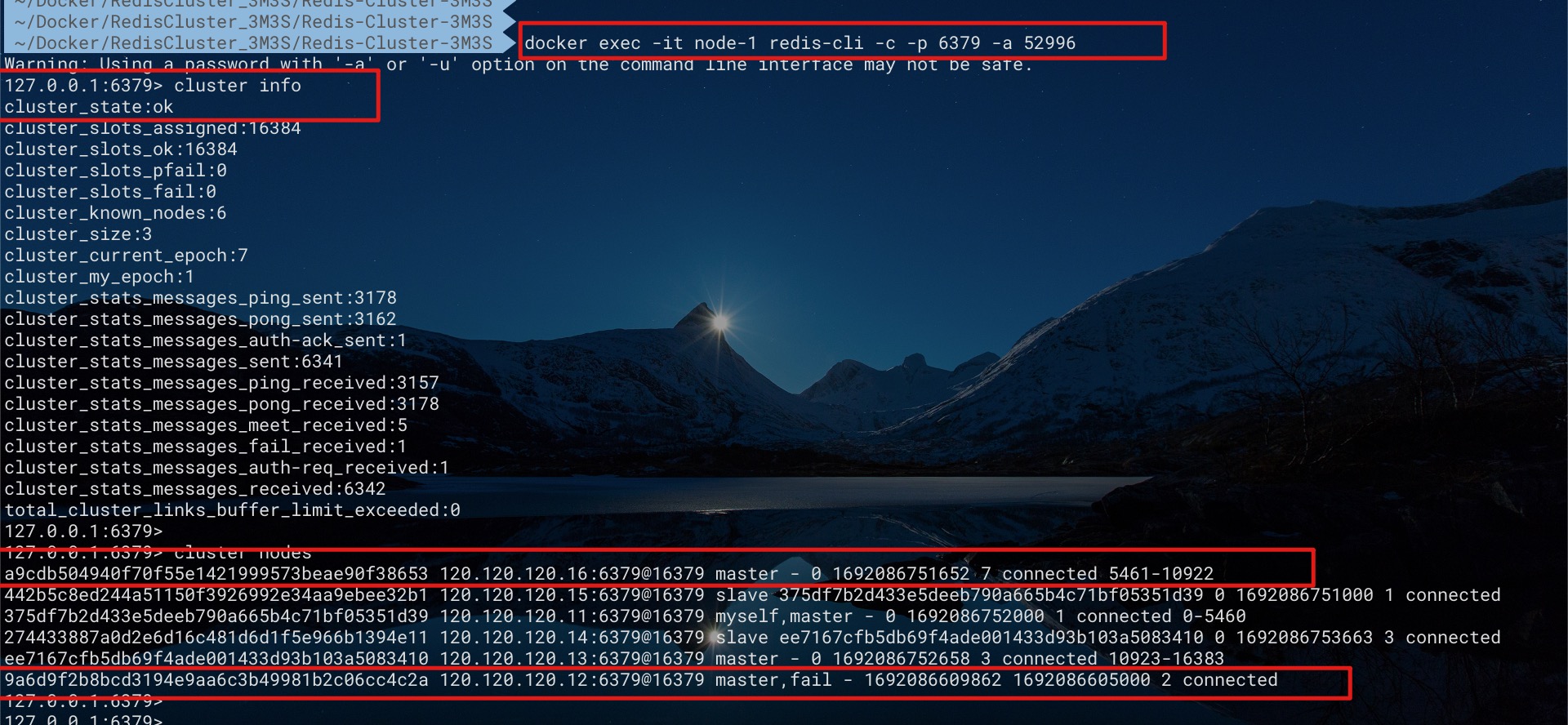
对于上面的搭建3主3从的集群而言,如果我们停止Master节点node 2的容器使其下线。从下图不难看出,集群状态依然可用。node 2节点的状态为fail。node 6节点此前是node 2节点的Slave节点,现在则成为新Master,对外提供服务了
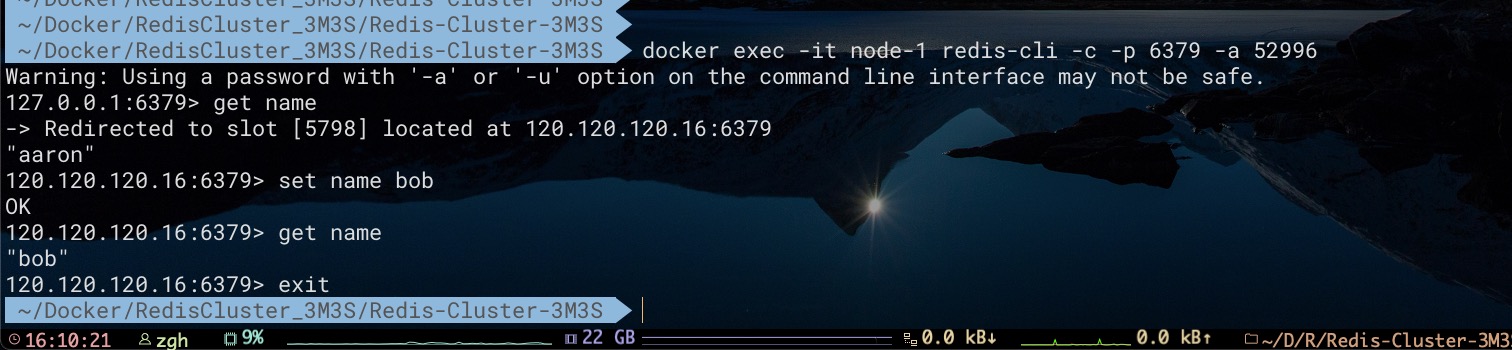
通过对key为name的数据进行访问、修改。进一步证明了node 6节点是Master节点了
此时,我们如果将node 2节点容器启动,会是什么情形呢?不难看出,node 2节点已经是新Master node 6节点的从节点了。因为当我们在node 6节点中修改key为name的数据后,可以从node 2节点中感知到变化
半数以上Master同时下线
对于上面的搭建3主3从的集群而言,如果我们将半数以上的Master同时下线,会怎么样呢?这里我们选择停止2个Master节点容器——node 2、node 3,会发生什么呢?
1
2
3
4
5
|
docker container stop node-2; docker container stop node-3
docker ps --filter status=running
|

现在我们通过node 1节点查看集群、节点状态,不仅node 2、node 3节点下线,而且整个集群都不可用。甚至对于node 1中key为age的数据都无法访问
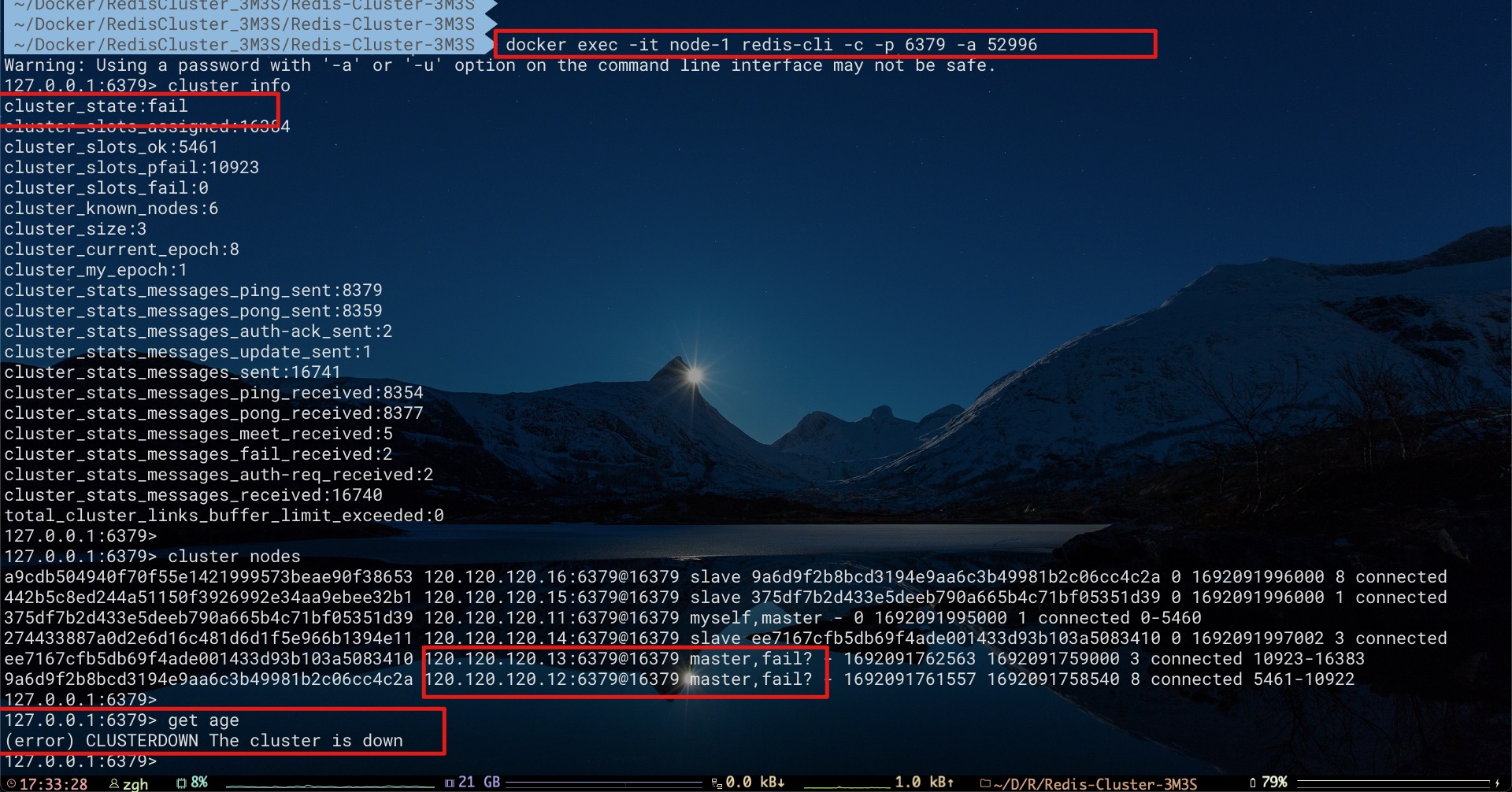
我们知道node 2、node 3节点都有各自的slave节点——node 6、node 4。为什么在该场景下未进行故障转移Failover,使node 6、node 4成为新Master呢?原因其实很简单,在Redis Cluster模式下是不需要Sentinel哨兵的。故对于一个含有N个Master的集群而言,当一个Slave提升为新Master的要求,是需要至少获得集群中 N/2+1 个Master(即半数以上的Master)的投票数。换言之,当集群中可用Master节点不足半数以上,会导致集群不可用
对于这里含有3个Master的集群而言,半数以上Master投票数的要求是 N/2+1 = 3/2+1 = 2。当我们同时停止两个Master节点容器后,集群中只剩一个Master可以进行投票。使得node 6、node 4节点均无法满足最低投票数要求。进而导致整个集群不可用
原Master在故障转移后依次下线
从上文不难看出在Redis Cluster中,节点的角色不是固定的。因为当Master节点下线后,其下的Slave节点可以被提升为新Master节点。对于上面的搭建3主3从的集群而言,如果我们对原Master节点node 1、node 2、node 3依次进行下线,但保证每次下线某个原Master节点时,之前的下线节点已经完成了故障转移
具体地:
- 先下线原Master节点node 1,等待故障转移完成,使得node 5成为新Master
- 再下线原Master节点node 2,等待故障转移完成,使得node 6成为新Master
- 最后下线原Master节点node 3,等待故障转移完成,使得node 4成为新Master
如下所示,不难看到当某个原Master下线。由于集群中可用Master的数量(包括原Master、新Master)总是可以满足半数以上的要求,故其下的Slave总是可以会被提升为新Master。例如,当原Master节点node 2下线时,集群中可用的Master有两个:原Master节点node 3、新Master节点node 5
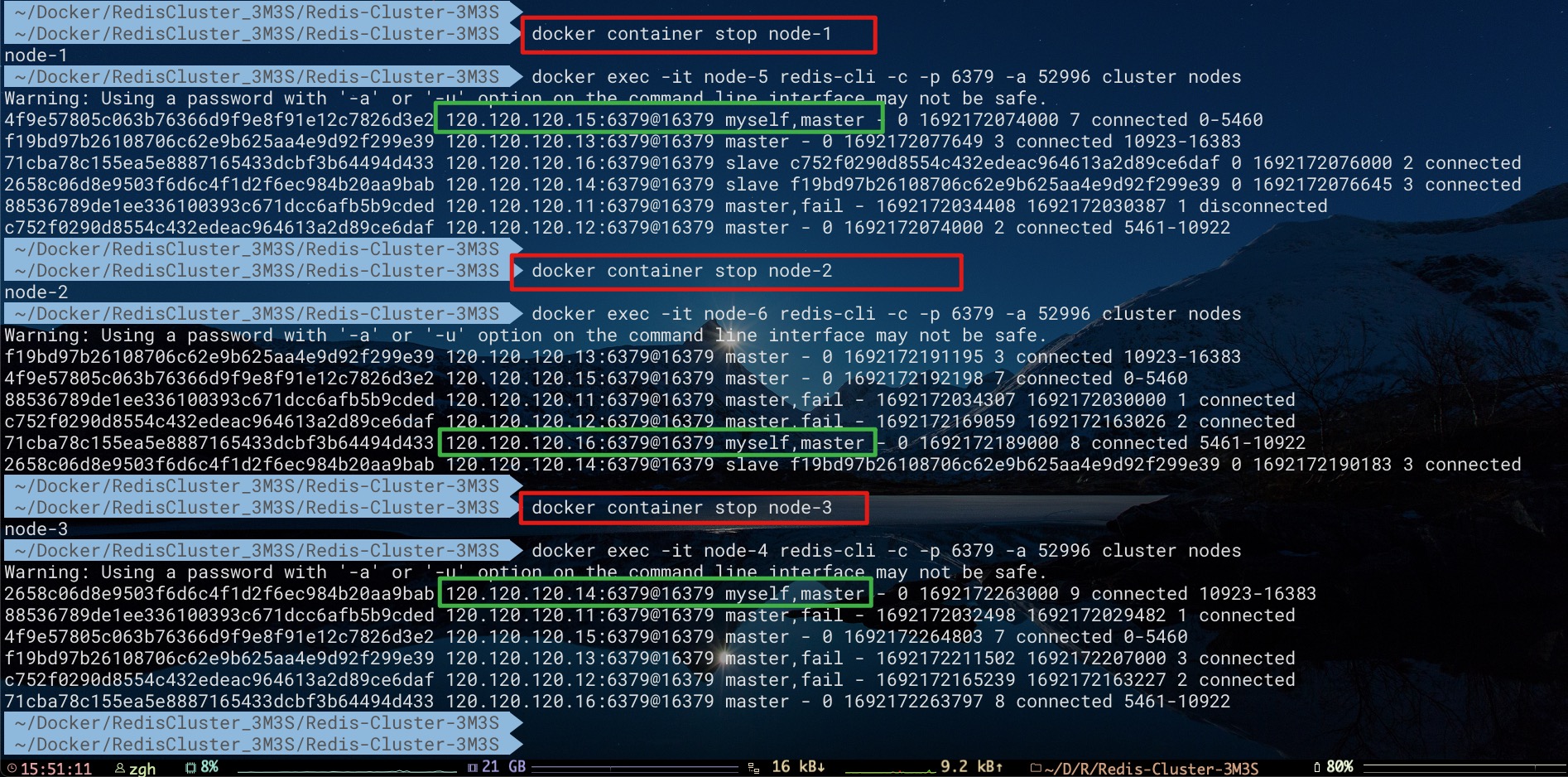
可以看到,原Master在故障转移后依次下线。此时集群中只有node 5、node 6、node 4这3个新Master节点了。自然集群依然是可用的
某个槽对应的主从节点全部下线
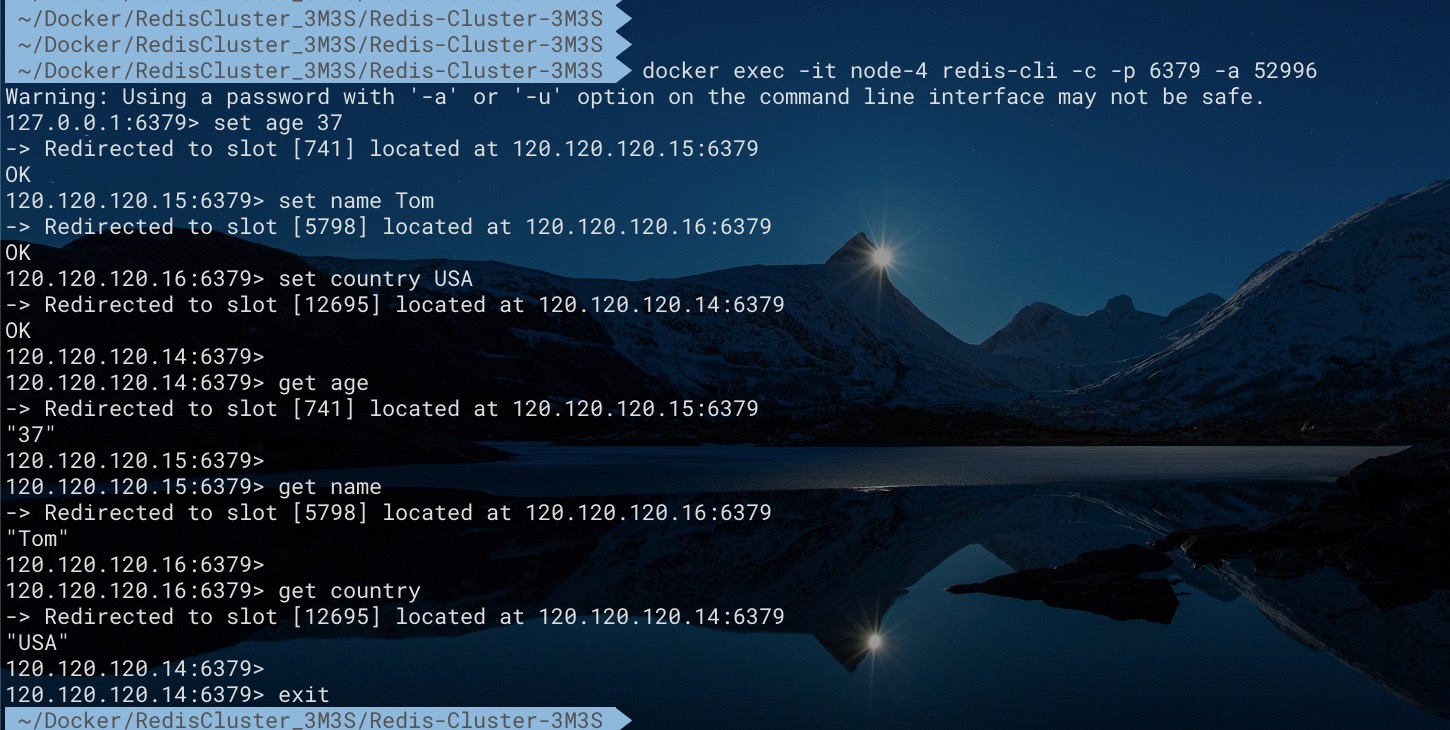
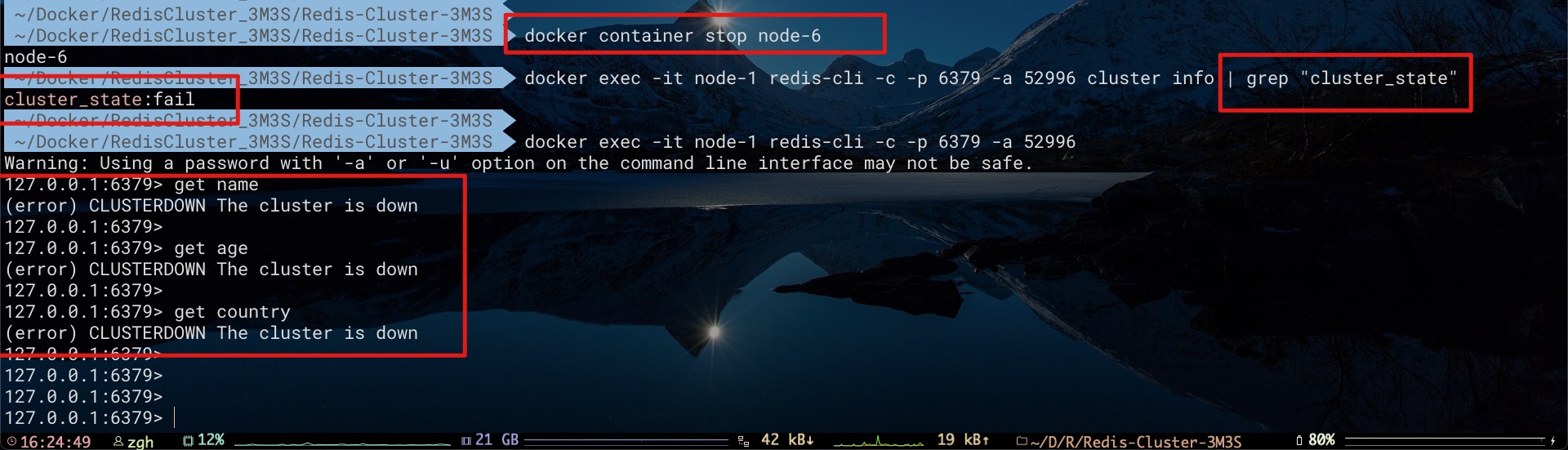
对于上面的搭建3主3从的集群而言,我们先将Master节点node 2下线,然后让node 6节点成为新Master
现在我们将node 6节点继续下线,这样该槽对应的所有节点(node 2、node 6)都已经全部下线了。此时,由于Redis集群中某个槽完全无法对外提供服务,会导致集群整体不可用。不仅无法访问存在于node 2、node 6中key为name的数据,而且对存在于node 1、node 3中key为age、country的数据也无法访问
事实上,这正是redis.conf配置文件中cluster-require-full-coverage配置项的作用。此前我们将该配置项设置为yes。即,当负责某个槽的主库下线且没有相应的从库进行故障恢复时,集群整体不可用。即使其他槽的节点未下线,也无法访问其中的数据
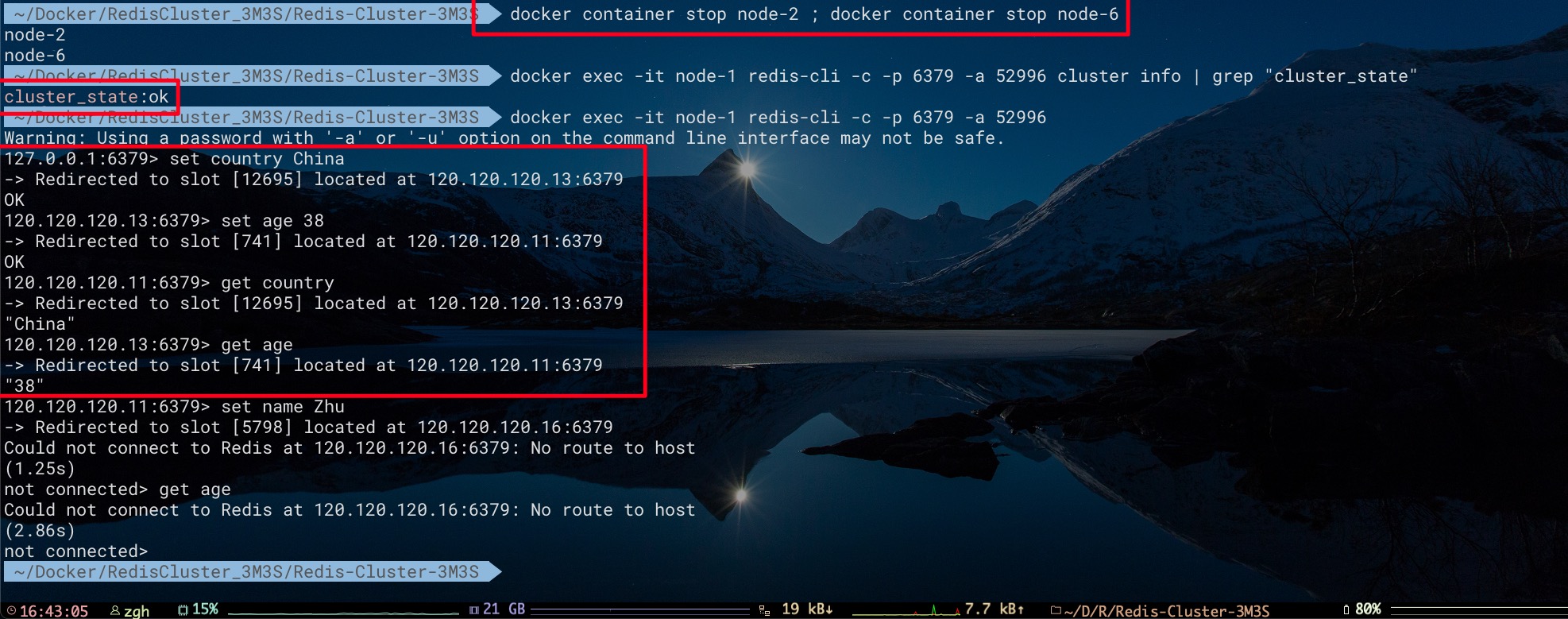
而这里,如果我们期望某个槽对应的所有节点(node 2、node 6)全部下线后。集群仍然可用,即可以访问其他槽(例如node1、node3)的数据。则可将cluster-require-full-coverage配置项修改为no,然后重启整个集群使之生效。这样当负责某个槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用。即可访问其他槽的数据
修改配置重启后,我们停止了node 2、node 6节点。此时集群状态依然可用。虽然无法访问存在于node 2、node 6中key为name的数据,但对存在于node 1、node 3中key为age、country的数据可以正常访问
总结
通过上文不难看出,Redis Cluster模式下集群不可用有两种情形:
- 当集群中可用Master节点不足半数以上,会导致集群不可用
- 当cluster-require-full-coverage配置项为yes时,某个槽对应的主从节点全部下线,会导致集群不可用;当cluster-require-full-coverage配置项为no时,某个槽对应的主从节点全部下线,集群中其他槽的数据可以正常访问
