这里就Redis的发布订阅、事务、排序、位图、慢查询、监视器等方面进行介绍

发布与订阅
基本实践
Redis在发布与订阅方面提供了以下命令
1 | # 发布消息到指定频道 |
在A、B两个客户端订阅了某个频道后,当其他客户端向该频道发送消息后,A、B两个客户端均会收到这条消息。测试结果如下所示
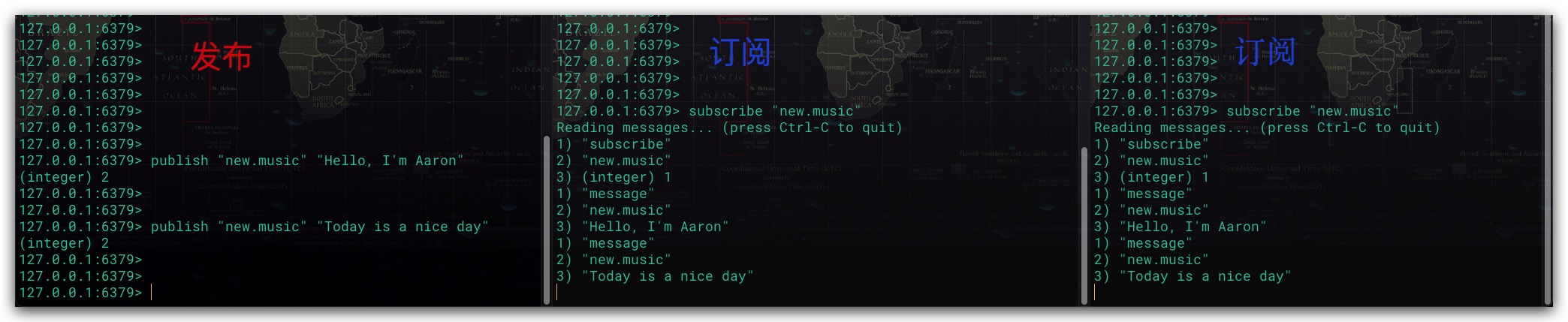
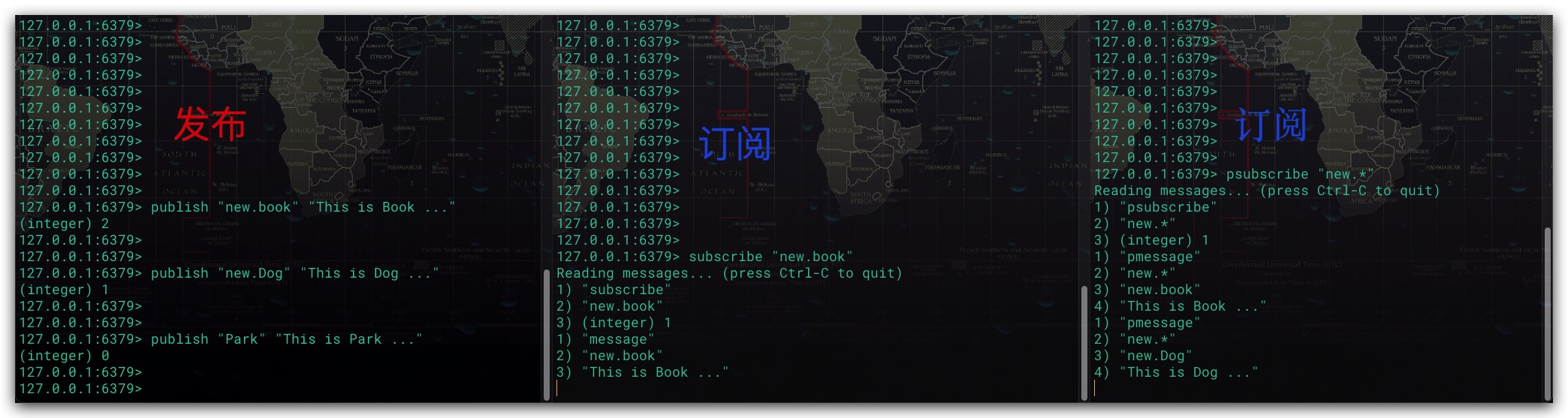
当其他客户端向某个频道发送消息时,不仅订阅了该频道的客户端会收到该消息。与此同时,该消息也会被发送给所有与该频道相匹配的模式订阅者。值得一提的是,这里的模式规则为Glob模式
实现原理
对于频道订阅而言。Redis服务端内部会通过一个dict字典来进行记录维护。具体地,字典的Key为频道名,字典的Value则是一个所有订阅该频道的客户端链表。这样向某频道发送消息时,即可通过字典获取相应的客户端链表。然后遍历该链表依次推送消息即可
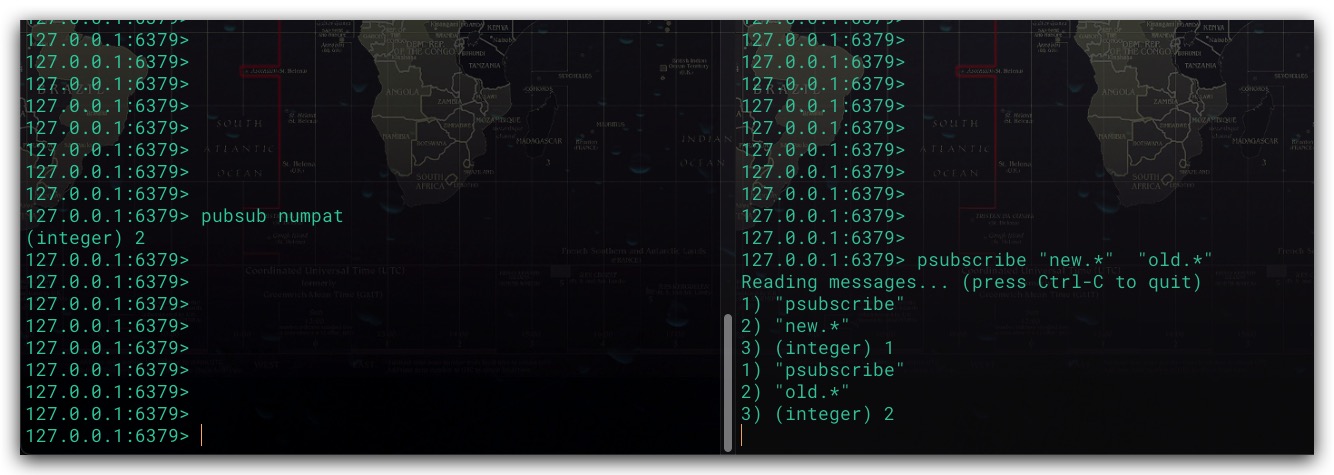
对于模式订阅而言,Redis服务端内部则是通过一个链表进行维护的。其中链表节点中仅包含一个模式和客户端信息。注意在一个链表节点中仅仅包含一个模式。换言之,如果某客户端发送 psubscribe “new.“ “old.“ 命令。即该客户端同时订阅了”new.“、”old.“这两个模式。则Redis服务端会针对这两个模式分别创建两个链表节点,然后依次加入链表中。这样向某频道发送消息时,即可遍历该链表。判断该频道名称是否匹配当前链表节点中的模式,如果匹配就把消息推送给相应的客户端
PUBSUB命令
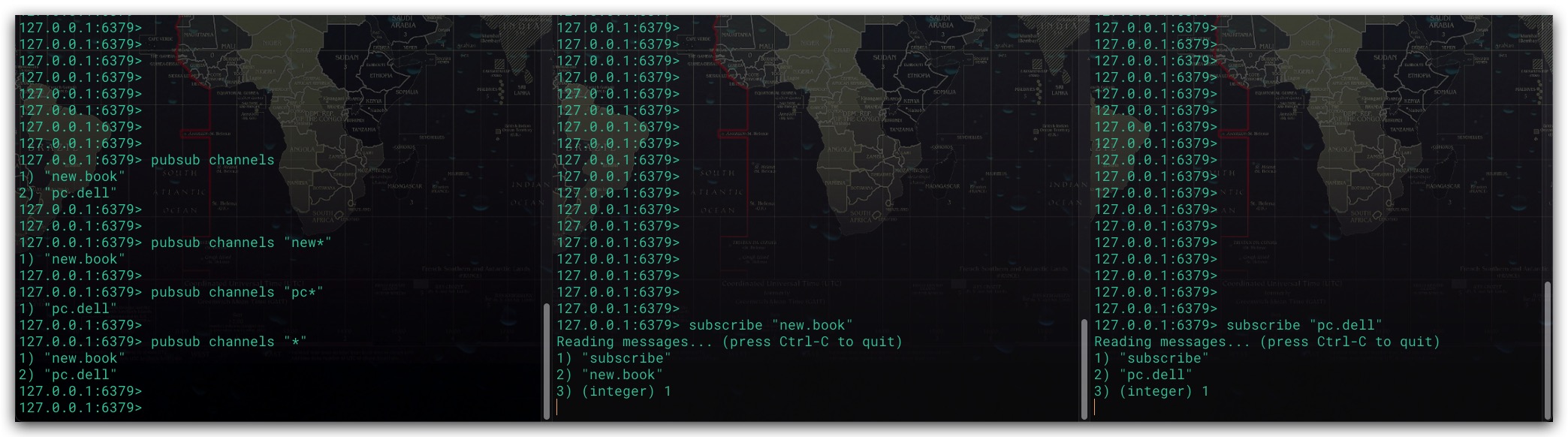
Redis从2.8版本开始引入了PUBSUB命令,用于查看订阅信息。具体地,其提供了三个子命令
1. PUBSUB CHANNELS [pattern]
该子命令用于查看Redis服务端当前被订阅的频道。其中patter模式参数是可选的。如果不给定patter模式参数,则会返回服务端当前被订阅的所有频道;反之,只会返回与模式相匹配的频道
2. PUBSUB NUMSUB <channel> [channel …]
该子命令用于查看Redis服务端订阅指定的若干个频道的订阅者数量

3. PUBSUB NUMPAT
该子命令用于查看Redis服务端被订阅模式的数量
事务
基本实践
Redis同样支持事务,具体地
- MULTI :该命令表示一个事务的开始
- EXEC :提交事务
- Discard :取消事务
- WATCH <key> [key …] :监视若干个指定Key
- UNWATCH :取消对所有Key的监视
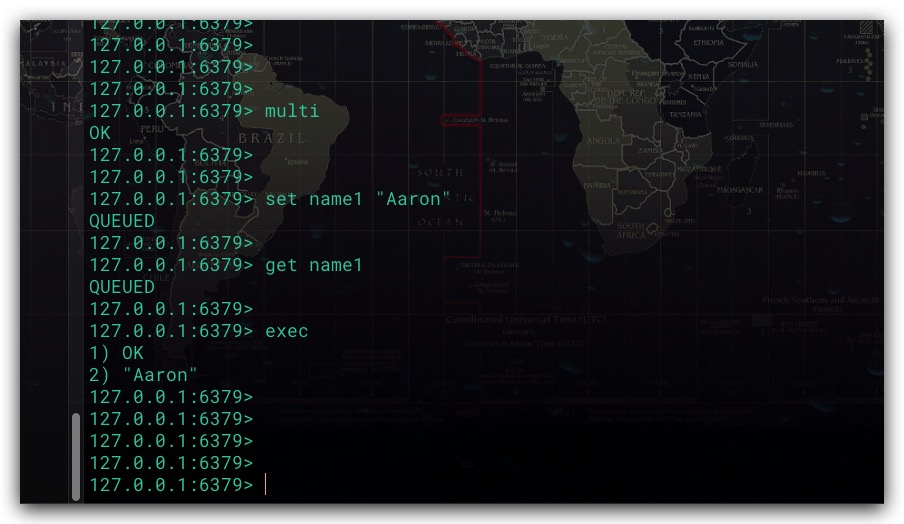
特别地,Redis中还提供了WATCH命令,其本质上是一个乐观锁。该命令用于在EXEC命令之前执行,用于对若干个指定的Key进行监视。这样EXEC执行过程中即会对所有被监视的Key进行检查。只要有一个被监视的Key被修改过了,则Redis服务端将会拒绝执行事务;反之,如果所有被监视的Key均未被修改过,则Redis将会执行该事务。示例如下所示
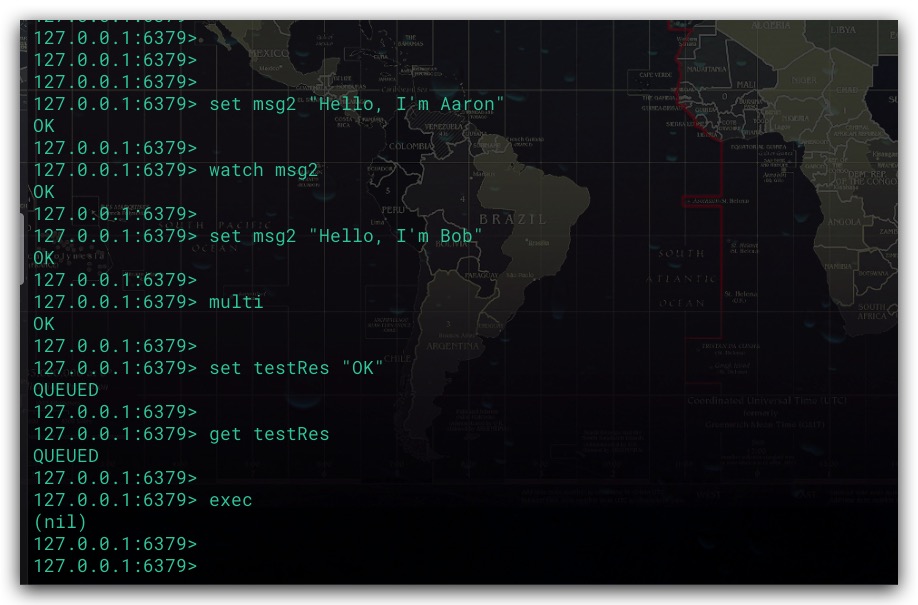
而UNWATCH命令则用于取消对所有Key的监视
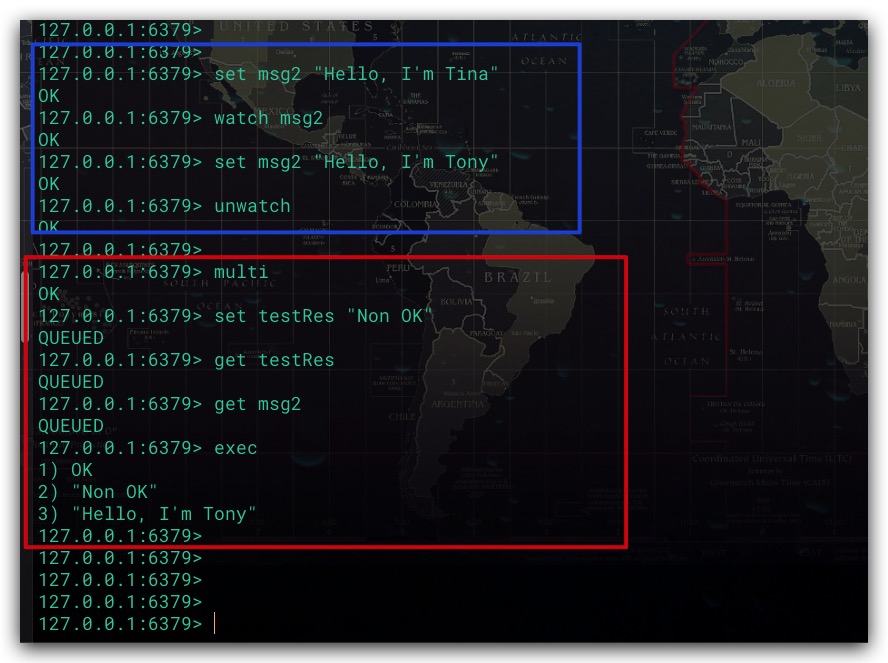
这里对Redis的乐观锁实现进行一定的补充说明。在Redis各数据库内部均会维护以一个字典。其中,字典的Key为被监视的Key;字典的Value则是一个所有监视该Key的客户端链表。这样后续每次对Redis执行写命令后,可以快速通过该字典判断被修改的Key是否有客户端在监视。如果有,即可直接获取监视该Key的客户端链表。遍历该链表、打开客户端节点中的相应标志位。这样Redis服务端在收到EXEC命令准备执行事务之前,只需检查该客户端的相应标志位是否被打开即可。如果提交事务的客户端的相应标志位被打开,则服务端将会拒绝执行事务;反之则执行事务
ACID
1. Atomicity 原子性
关于事务的原子性的含义非常简单。即一个事务中的所有操作要么全部执行、要么一个也不执行。但对于Redis而言,这个问题我们要一分为二来看
- 存在语法错误(例如命令不存在、命令参数非法等)的情况下,事务中的所有命令都不会执行
- 存在运行错误(例如对String类型的Key执行RPUSH操作命令)的情况下,除执行中出现错误的命令外,其他命令都能正常执行
从上不难看出,Redis与传统的关系型数据库事务的最大区别在于:Redis事务不支持Rollback回滚机制。即事务在执行过程中如果某条命令执行失败,整个事务依然会继续执行下去。而不会回滚。而之所以Redis的事务不支持回滚,是因为Redis的作者认为运行错误应该在开发环境中就应该被测试出来,而不应该在生产环境中发生。故从这个角度来说,Redis是具有原子性的
2. Consistency 一致性
一致性则是指数据符合约束、要求,没有错误的、非法的数据。总的来说,Redis具有一致性。具体地,我们从几个方面进行分析
- 存在语法错误的事务,Redis会拒绝执行该事务。故Redis一致性不会被该事务影响
- 存在运行错误的事务,Redis会继续执行事务中不存在错误的命令,且执行结果不会被出错的命令影响。故Redis一致性不会被该事务影响
- 事务执行过程中Redis服务发生宕机。如果没有相应的持久化文件(RDB/AOF),则服务重启后数据库为空。而空库总是一致性的;而如果存在相应的持久化文件(RDB/AOF),服务在重启后将会根据持久化文件恢复数据。故同样也是符合一致性的
3. Isolation 隔离性
由于Redis采用单线程的方式执行事务,且保证在执行事务过程中不会对其进打断。故Redis的事务总是以串行的方式执行。所以Redis天然具有隔离性
4. Durability 持久性
在持久性方面,需要分类进行讨论
- 如果服务端未启用持久化,则显然此时事务不具备持久性
- 如果服务端采用RDB进行持久化,服务端只会在特定条件下才会执行BGSAVE命令。并且BGSAVE命令是异步的,不能在第一时间保证事务执行结果被存储到硬盘中。故RDB持久化模式下不具备持久性
- 如果服务端采用AOF进行持久化,当appendfsync配置为always时,则服务端每次执行完命令即会进行同步。故此时是具有持久性的。需要注意的是,no-appendfsync-on-rewrite配置项也必须设置no、而不能使用yes。否则此时事务将不具有持久性。其默认值为no
- 如果服务端采用AOF进行持久化,当appendfsync配置为everysec、no时,由于不能保证事务执行结果被立即同步。故此时不具有持久性
排序
基本实践
Redis的SORT命令可以对列表、集合、有序集合等类型的数据进行排序。默认按升序排列
1 | # 对指定Key中的元素进行升序排序 |
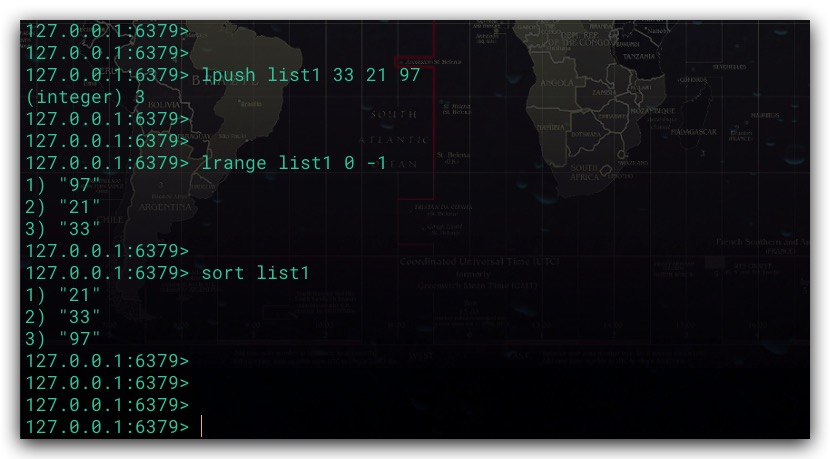
1. ALPHA 选项
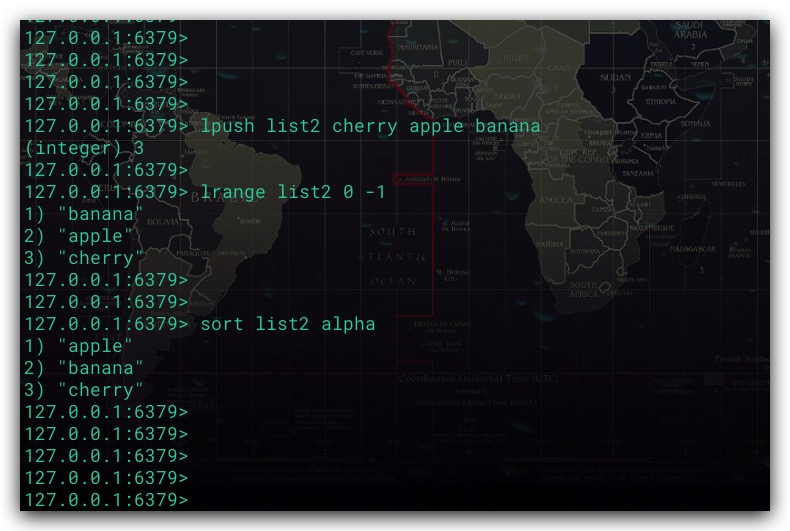
如果元素值不是数字,而是字符串。则可以使用 ALPHA 选项,实现按字典序排序
1 | # 对指定Key中的元素按字典序进行升序排序 |
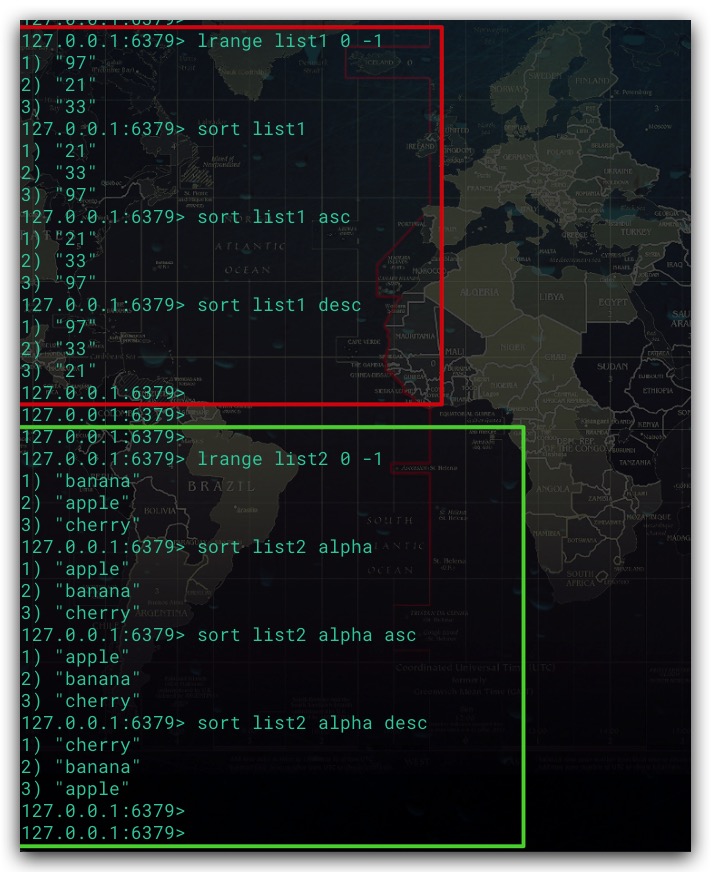
2. ASC、DESC 选项
SORT命令默认进行升序,当然也可以通过 ASC 选项显式指定;而降序则可以通过 DESC 选项实现
1 | # 对指定Key中的元素进行升序排序 |
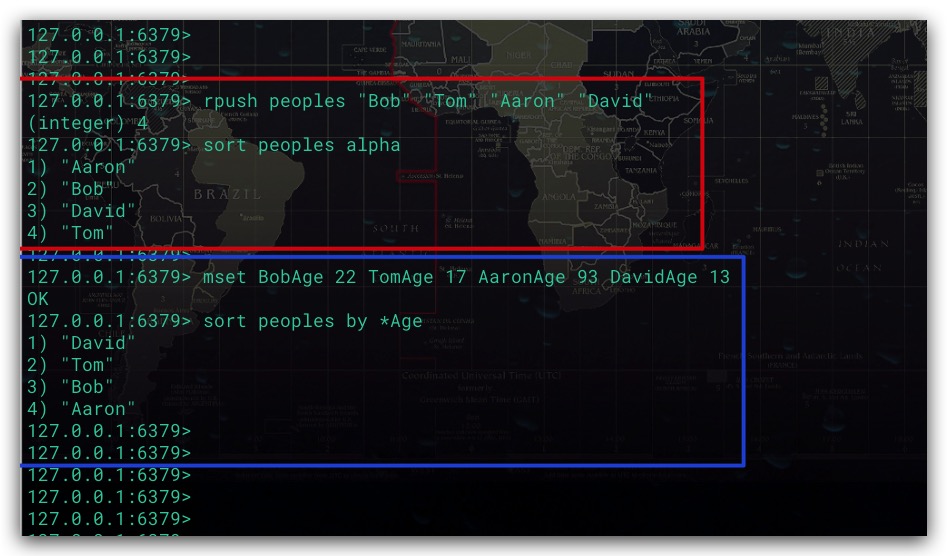
3. BY 选项
SORT命令默认使用被排序元素的值作为排序的权重。但其同时支持通过BY选择指定外部Key作为排序的权重
1 | # 对指定Key中的元素, 按外部Key进行排序 |
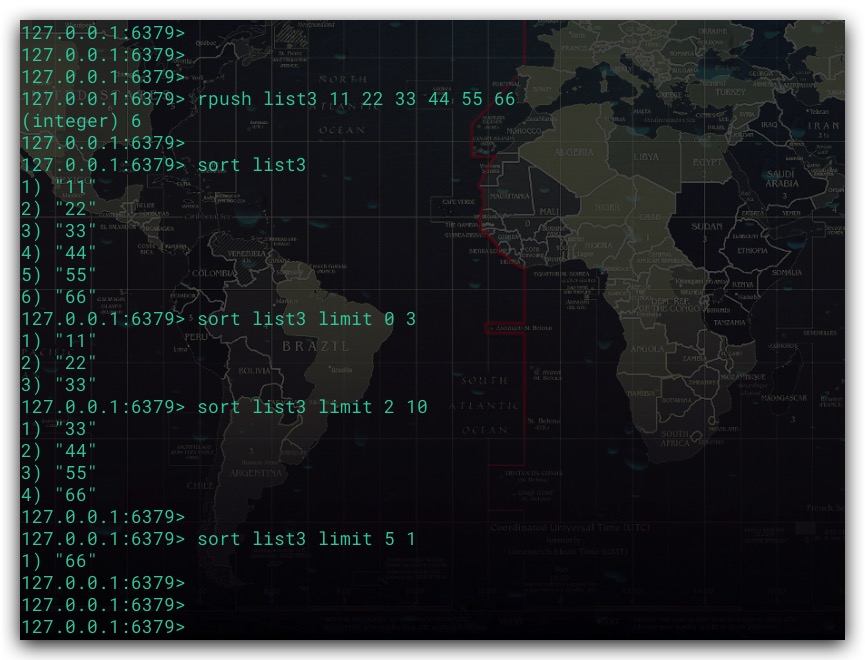
外部Key可以为String类型的数据。其中在pattern模式中*表示占位符,用于指代被排序元素的值。例如下面我们使用mset命令设置多个String类型的数据。然后通过*Age模式来获取相应的外部Key
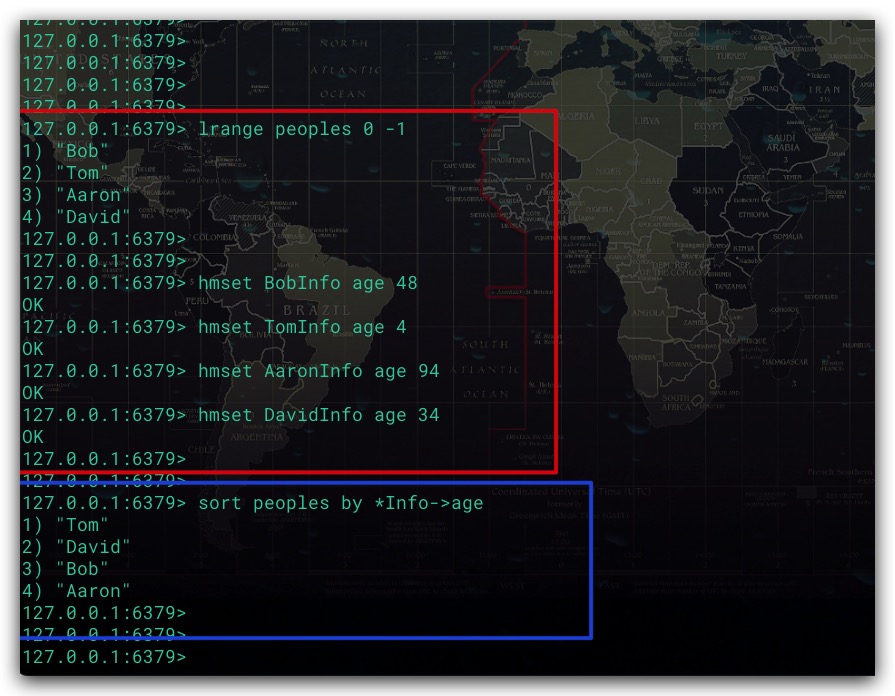
此外还可以使用Hash类型的数据作为外部Key。其中,可以使用 key->field 格式来获取Hash键中域的值,其中key表示键,而 field则表示域。具体地,我们可以通过不同的Hash键分别保存各外部Key的值
4. LIMIT 选项
SORT命令会返回排序的全部结果,故可以LIMIT选项实现返回部分排序结果。其中,offset参数表示返回结果时跳过前offset个;count参数表示返回结果时跳过指定数量后,要返回排序结果的最大数量
1 | # 对指定Key中的元素进行升序排序,返回结果时跳过前offset个元素,并且返回结果的数量最大为count |
5. GET 选项
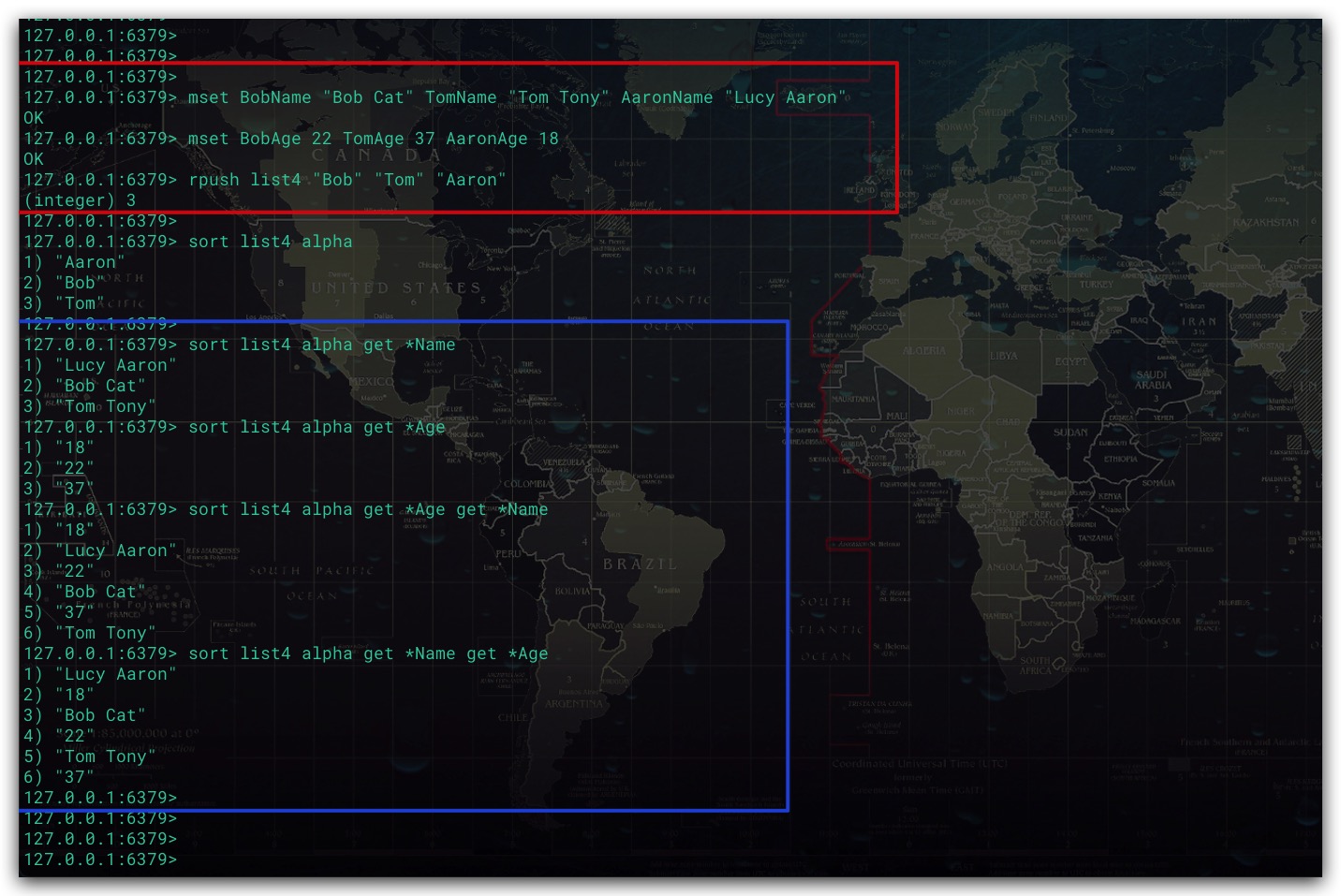
SORT命令在排序后,默认会返回被排序元素自身。但通过GET选项可以实现在排序后,将 被排序元素、GET选项指定的模式 作为新Key。并将新Key的值作为结果返回。其中pattern模式中*表示占位符,用于指代被排序元素的值。此外支持使用多个GET选项
1 | # 对指定Key中的元素进行升序排序,并根据GET选项的模式返回相应键的值 |
6. STORE 选项
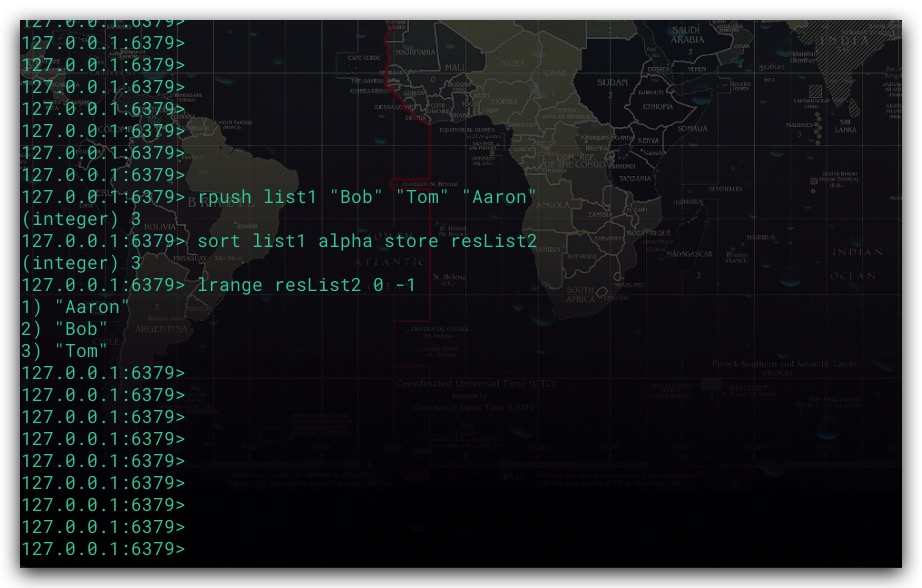
SORT命令只会向客户端返回排序结果,而不会进行保存。故可通过STORE选项保存排序结果到指定键,以便后续再次利用该排序结果
1 | # 对指定Key中的元素进行升序排序,并将排序结果保存到指定的key2当中 |
综上所述,对于SORT命令完整格式如下所示
1 | SORT <key> [ALPHA] [ASC|DESC] [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [STORE key2] |
故在实际实践中,我们可以按需自由组合、选用上面的其各种选项。并且除了GET选项外,改变其他各选项在SORT命令中的摆放位置。并不会影响SORT命令执行这些选项的先后顺序。因为SORT命令中各选项在Redis内部是有固定的执行顺序、流程规则。故Sort命令的大体流程顺序如下所示:
- 排序:其会利用ALPHA、ASC、DESC、BY选项,对指定Key进行排序以得到一个排序结果集
- 截取:其会利用LIMIT选项,对上一步获得的排序结果集进行截取,并作为新的排序结果集
- 获取外部键:其会利用GET选项,根据上一步获得的排序结果集的元素、GET选项的模式获取相应相应外部键的值。并将外部键的值作为新的排序结果集
- 保存:其会利用STORE选项,将上一步获得对排序结果集保存到指定Key当中
位图
Redis 2.2.0版本开始引入了位图这一数据类型,其使用位数组进行存储。这里补充说明下Redis内部对于位图采用SDS简单动态字符串进行实现。其支持以下命令
1 | # 针对指定位图,将指定偏移量的二进制位设置为指定值。其中,offset从0开始计数;value为0或1 |
这里对于bitcount命令进行一些补充说明,其目的在于统计一个位图中非零二进制的数量。换言之,即计算它的汉明重量。朴素的思想是直接暴力遍历位图进行统计,但对于特别大的位图来说,效率太低。而另外一种改进方法是查表法,比如表中记录8个二进制位的各种排列情况所对应的非零二进制的数量。即典型的以空间换时间,但问题在于这个表该多大?比如表中记录8个二进制位的各种排列情况所对应的非零二进制的数量,还是表中记录16个二进制位的各种排列情况所对应的非零二进制的数量,甚至更多呢?因为仅仅记录8个二进制位,效率相比暴力法也仅仅提升了8倍。对于大位图提升不明显。但表一旦过大,又会造成严重的内存消耗
幸运地是统计一个位图中非零二进制的数量。在数学上该问题可以被称之为计算汉明重量。由于汉明重量被广泛应用于信息论、密码学当中。故学届针对该问题提出了很多算法,目前已知效率最好的通用算法是variable-precision SWAR算法。该算法可以以常数时间复杂度计算多个字节的汉明重量。同时该算法的空间复杂度也是常数
故在Redis当中,bitcount命令的实现方式是将variable-precision SWAR算法、查表法有机结合起来
- 对于前者而言,每128个二进制位时,即会调用四次32位版本的variable-precision SWAR算法来计算这128个二进制位的汉明重量
- 对于后者而言,通过表存储、记录8个二进制位的各种排列情况所对应的非零二进制的数量
这样在bitcount命令的实现中:当位图中剩余未计算的二进制位数量大于等于128时,使用variable-precision SWAR算法。这样每次即可计算128个二进制位的汉明重量;当位图中剩余未计算的二进制位数量小于128时,再去使用查表法
慢查询日志
Redis的慢查询日志可以记录执行时间超过指定阈值的命令请求。用户可以据此进行监控、分析。故Redis的配置文件提供了如下相关的配置项
- slowlog-log-slower-than :命令执行时间的阈值。超过该值的即会被视为慢查询,并被记录到日志当中。单位:微秒
- slowlog-max-len :慢查询日志记录日志的数量上限。因为Redis使用FIFO的方式保存慢查询记录。故当数量超过上限后,即会移除最久的一条慢查询日志记录
当然还可以通过config set/get命令,实现对上述两个配置项的实时修改/查看
1 | # 设置慢查询的时间阈值:10000微秒=10毫秒 |
为此Redis通过SLOWLOG命令提供了三个子命令
1. SLOWLOG GET [count]
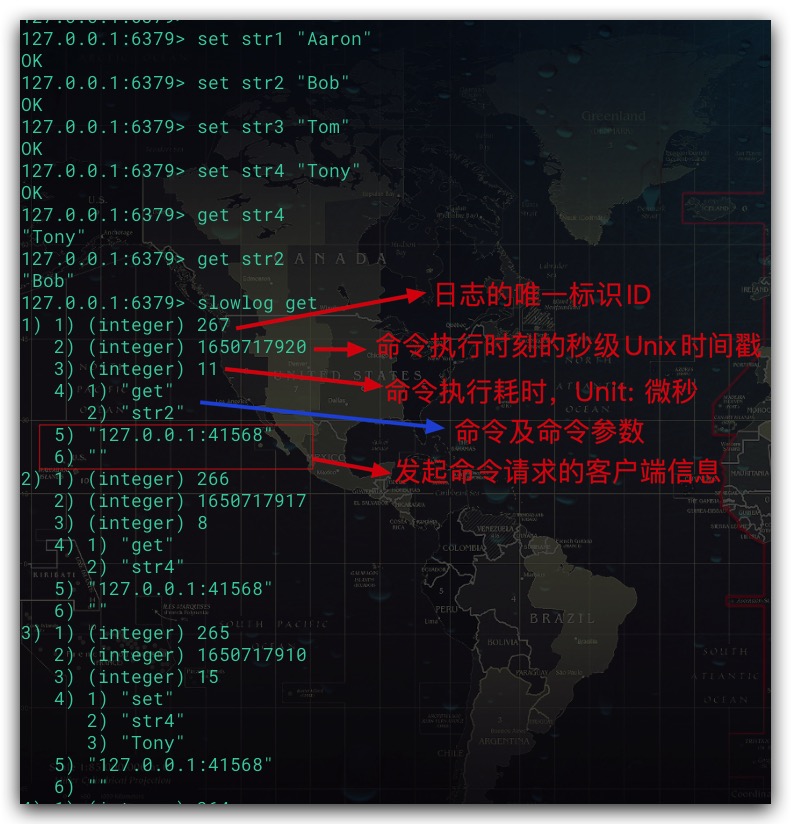
查看当前最新的慢日志记录,其中可选参数count用于指定返回的最大记录数量。如下图所示,其返回了3条慢查询记录。并对其中一条日志为例,对内容含义进行介绍
2. SLOWLOG LEN
获取当前慢日志记录的总数
3. SLOWLOG RESET
清空所有慢日志记录
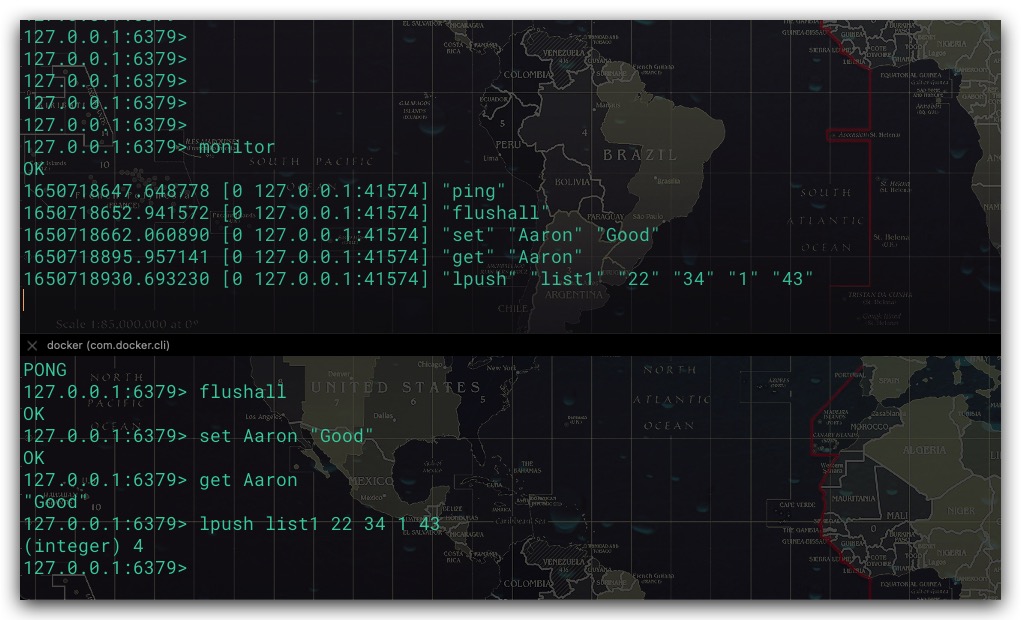
监视器
客户端可以通过执行MONITOR命令,将其自身变为一个监视器。实时接收、打印Redis服务端当前处理来自其他客户端的命令请求。具体地,Redis内部通过一个链表来维护所有的监视器。这样当服务端收到其他客户端的命令请求后,即可遍历该链表将命令请求转发给正在监视该服务端的所有监视器
参考文献
- Redis设计与实现 黄健宏著
