分布式系统中ID生成方案,比较简单的是UUID(Universally Unique Identifier,通用唯一识别码),但是其存在两个明显的弊端:一、UUID是128位的,长度过长;二、UUID是完全随机的,无法生成递增有序的UUID。而现在流行的基于 Snowflake 雪花算法的ID生成方案就可以很好的解决了UUID存在的这两个问题

原理
Snowflake 雪花算法,由Twitter提出并开源,可在分布式环境下用于生成唯一ID的算法。该算法生成的是一个64位的ID,故在Java下正好可以通过8字节的long类型存放。所生成的ID结构如下所示

最高位是符号位,为保证生成的ID是正数,故不使用,其值恒为0
用来记录时间戳的毫秒数。一般地,我们会选用系统上线的时间作为时间戳的相对起点,而不使用JDK默认的时间戳起点(1970-01-01 00:00:00)。41位长度的时间戳可以保证使用69年。对于一般的项目而言,这个时间长度绝对是够用了

数据中心(机房)ID、机器ID一共10位,用于标识工作的计算机,在这里数据中心ID、机器ID各占5位。实际上,数据中心ID的位数、机器ID位数可根据实际情况进行调整,没有必要一定按1:1的比例分配来这10位
最低的12位为序列号,可用于标识、区分同一个计算机在相同毫秒时间内的生产的ID
综上所述,Snowflake 雪花算法生成的ID不是随机的,而是按时间顺序升序排列的;且可以保证在分布式高并发环境下生成的ID不会发生重复
Java实现
这里使用Java来实现一个基于 Snowflake 雪花算法的ID生成器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
|
public class SnowflakeIdGenerator {
private final long startPoint = 1577808000000L;
private final long sequenceBits = 12L;
private final long workerIdBits = 5L;
private final long dataCenterIdBits = 5L;
private final long sequenceMask = -1L^(-1L<<sequenceBits);
private final long maxWorkerId = -1L^(-1L<<workerIdBits);
private final long maxDataCenterId = -1L^(-1L<<dataCenterIdBits);
private final long workerIdShift = sequenceBits;
private final long dataCenterIdShift = sequenceBits + workerIdBits;
private final long timeStampShift = sequenceBits + workerIdBits + dataCenterIdBits;
private long dataCenterId;
private long workerId;
private long sequence = 0L;
private long lastTimeStamp = -1L;
public SnowflakeIdGenerator(Long dataCenterId, Long workerId) {
if(dataCenterId==null || dataCenterId<0 || dataCenterId>maxDataCenterId
|| workerId==null || workerId<0 || workerId>maxWorkerId) {
throw new IllegalArgumentException("输入参数错误");
}
this.dataCenterId = dataCenterId;
this.workerId = workerId;
}
public synchronized long nextId() {
long currentTimeStamp = System.currentTimeMillis();
if( currentTimeStamp < lastTimeStamp ) {
throw new RuntimeException("系统时钟被回拨");
}
if( currentTimeStamp == lastTimeStamp ) {
sequence = (sequence + 1) & sequenceMask;
if(sequence == 0) {
currentTimeStamp = getNextMs(lastTimeStamp);
}
} else {
sequence = 0;
}
lastTimeStamp = currentTimeStamp;
long nextId = ((currentTimeStamp-startPoint) << timeStampShift)
| (dataCenterId << dataCenterIdShift)
| (workerId << workerIdShift)
| sequence;
return nextId;
}
private long getNextMs(long lastTimeStamp) {
long timeStamp = System.currentTimeMillis();
while(timeStamp<=lastTimeStamp) {
timeStamp = System.currentTimeMillis();
}
return timeStamp;
}
}
|
上述代码比较简单,这里对其中涉及到的位运算部分作解释说明
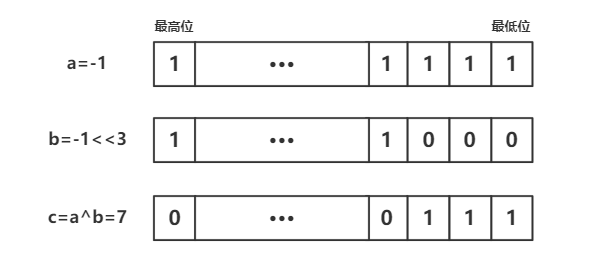
1. 计算X位Bit能表示的最大值
计算X位Bit能表示的最大值,最简单的是 Math.pow(2,X)-1,不过还可以通过位运算来提高速度,即 -1^(-1<<X)。这里以X等于3为例作图解说明
Note:
在计算机的二进制下 -1 使用全1进行表示
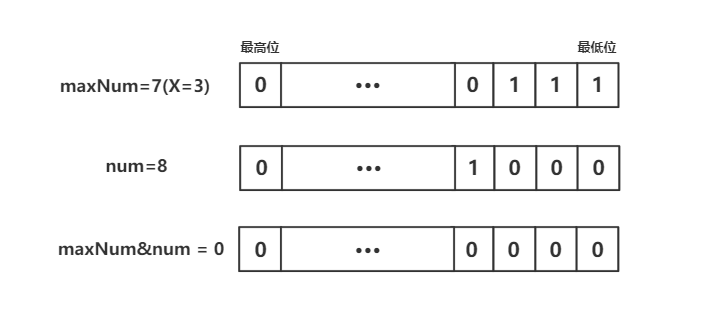
2. 判定某个值是否大于X位Bit所能表示的最大值
判定一个数num是否大于X位Bit所能表示的最大值maxNum,可以直接用关系运算符进行比较。但是由于maxNum的低X位均为1,故我们还可以将其看作是一个掩码,用于将num中除低X位外的其余位全部清零。在num从1逐渐递增的过程中,当 num&maxNum 的结果恰好为0时,则表明num已经开始大于maxNum。这里以X等于3为例作图解说明