缓存作为实际开发中高频出现的基础组件,这里简单谈谈使用缓存的几种典型模式

Cache Aside Pattern
Cache Aside模式,是我们日常开发中经常使用的缓存模式。该模式的目的在于保证并发的前提下尽可能减少(缓存与数据库间)数据不一致的可能,其是对AP模型下Base理论的体现。具体来说,在该模式下对于数据的读操作,步骤如下:
- 首先从缓存中读取数据
- 如果命中缓存Cache Hit,则直接进入步骤4
- 如果未命中缓存Cache Miss,则从数据库读取数据,并放入缓存中
- 返回数据结果
而对于数据的写操作,其步骤流程就很简单了
- 更新数据库,即将数据写入数据库
- 删除缓存中相应的数据
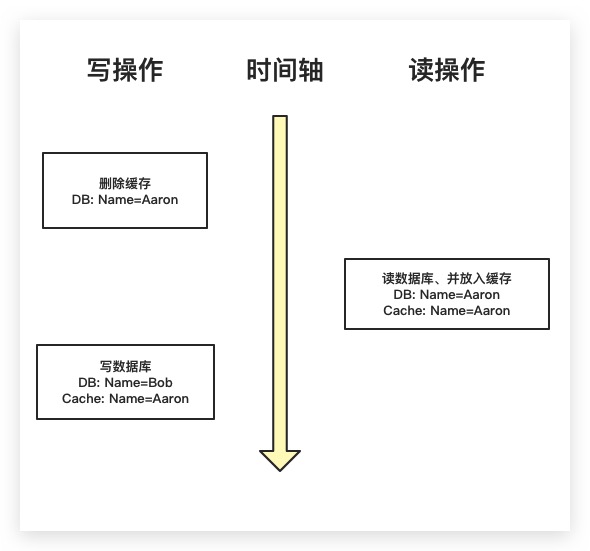
显然这里对于读操作的流程步骤没有什么争议。问题在于写操作中为什么是先写数据库、再删缓存?能不能先删除缓存再写数据库?答案显然是不能。如下图所示,当写操作刚删除完缓存中的数据时,恰好此时有一个新的读请求。其读取数据库,并设置缓存。此时缓存中Name的值为Aaron。然后写操作开始写数据库,将数据库中的Name修改为Bob。可以看到此时缓存与数据库中的数据发生不一致
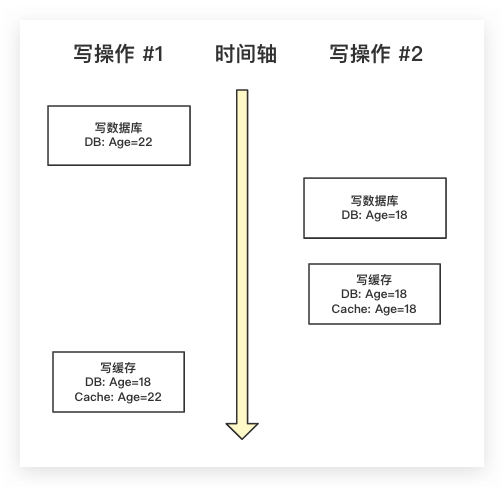
还有人可能会问,为什么在Cache Aside模式的写操作过程中,为什么不在写完数据库后、再去写缓存呢?这样不是可以提高下一次读操作的效率么?一方面,有些场景下计算缓存值的成本可能较高,如果本次写缓存后。下次又是一次写操作,则会浪费之前所计算的缓存。故缓存的写入放在读操作中进行,即所谓的懒加载。另一方面,其同样会导致数据的一致性问题。如下图所示,有两个请求分别进行写操作。当写操作#1刚刚写完数据库,此时DB中Age的值为22。此时另外一个写操作#2则将数据库、缓存均更新为18。现在写操作#1开始写缓存,可以看到当其操作结束后。数据库、缓存中Age的值出现了不一致
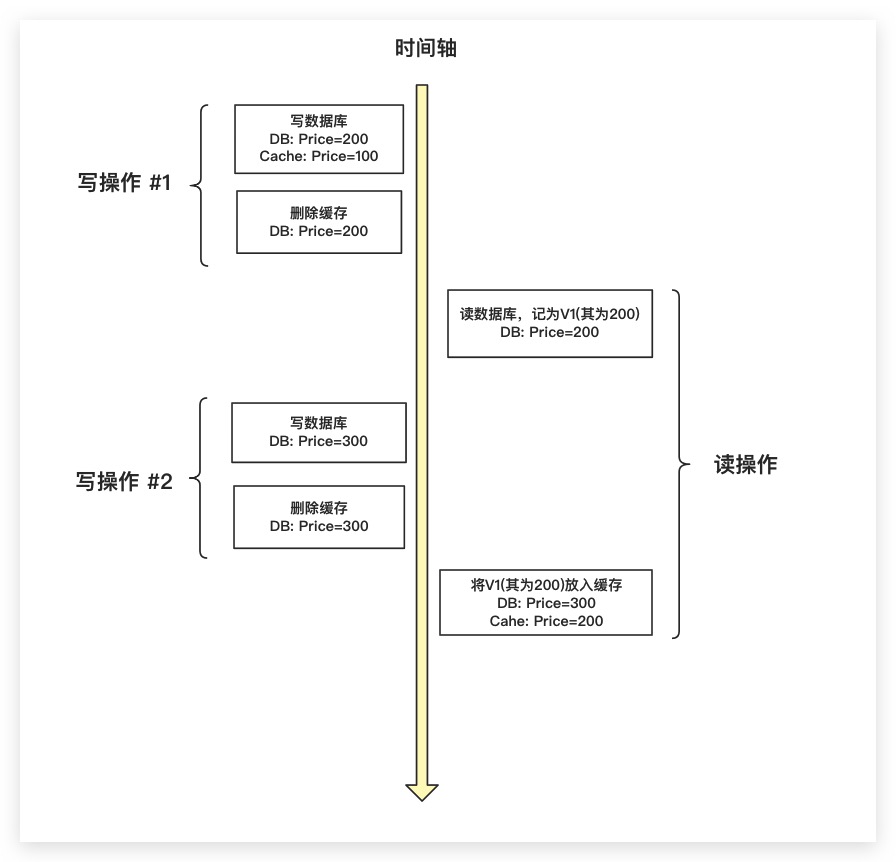
前面提到了Cache Aside模式只能尽可能地减少发生数据不一致的问题,其在极端情况下依然有可能会出现数据不一致。如下图所示,比如在某请求在进行读操作时,缓存中并无相应数据。造成该现象的原因有可能是因为此前刚刚完成了一次写操作,把缓存删掉了;也有可能是因为是第一次访问,缓存无数据所导致的。总之该请求的读操作需要从数据库中读取,这里记为200。这时突然有另外一个请求,即写操作#2。其迅速完成了数据库的写入将其更新为300,并同时删除了缓存。而此时读操作才开始将其此前读到的200写入缓存。显然此时缓存与数据库的数据发生了不一致
甚至可以说,在数据库使用主从架构时,如果从库的同步延迟较高,即虽然针对主库的写请求很快完成了写数据库、删除缓存的操作;但此时从库的数据依然还没有被同步更新过来,导致对从库的读操作访问到了旧值并回写到了缓存当中。此时同样出现了数据的不一致性问题。故针对类似这种极端场景,可以考虑在基础的Cache Aside(即写数据库、删缓存)完成后,经过一定的延迟时间后再进行一次缓存删除操作,以解决读操作把旧值写入缓存的问题。即所谓的延迟双删。当然这里第二次删除所需的延迟时间,需要根据实际业务场景来决策
Read/Write Through Pattern
在Cache Aside模式中,我们需要同时操作数据库和缓存,以保持二者间数据的同步。而在Read/Write Through模式下,则简单很多。我们只需对缓存服务进行读、写即可。由缓存服务内部实现与数据库数据的同步。换言之,在该模式下可以将缓存服务视为数据库的门面/代理。典型地,Ehcache支持该缓存模式
Write Behind Pattern
在Write Through模式中,当进行写入操作时,缓存服务内部是先写入缓存、再同步到数据库中。此举显然大大降低了性能,故提出了Write Behind模式,其不同点就在于。执行写操作时,缓存服务是先写入缓存,然后通过异步的方式写入数据库。典型地,数据库的Buffer Pool缓冲池中就使用了该缓存模式
参考文献
- 凤凰架构: 构建可靠的大型分布式系统 周志明著
