GeoHash作为地理空间编码中常见的算法,其目标是对二维平面进行网格划分,同时对每个网格使用一个编码进行表示。该算法下可以大大提高我们对位置信息的检索及查询的效率
基本原理
通过一个给定的经纬度坐标(经度146.842813452468、纬度-54.9432909847213)来介绍该算法的基本原理及流程
基于二分查找的经纬度编码
众所周知,经度范围-180~180,纬度范围-90~90。这里利用二分查找分别计算该经纬度坐标下经度、纬度的编码。其中,位于左区间、右区间的值分别记为0、1。下面即是对经度146.842813452468进行区间二分的过程。这里左区间是左闭右开区间、右区间是左闭右闭区间
1 | ------------------------------------------------------------------------------------------------------------ |
我们将每次二分的结果汇总起来,则该经度编码即为:11101000011010111110。同理,我们对纬度-54.9432909847213进行编码,二分过程如下所示
1 | ------------------------------------------------------------------------------------------------------------ |
故,该纬度编码即为:00110001110110111100
合并
对于经度、纬度的编码,我们按照经度、纬度、经度、纬度…顺序,分别依次取一位进行合并。合并结果如下所示

Base32编码
利用下述Base32编码表,对合并后的经纬度编码按5位一组进行编码
| 10进制数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 编码值 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g |
| 10进制数 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 编码值 | h | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |
编码过程如下所示
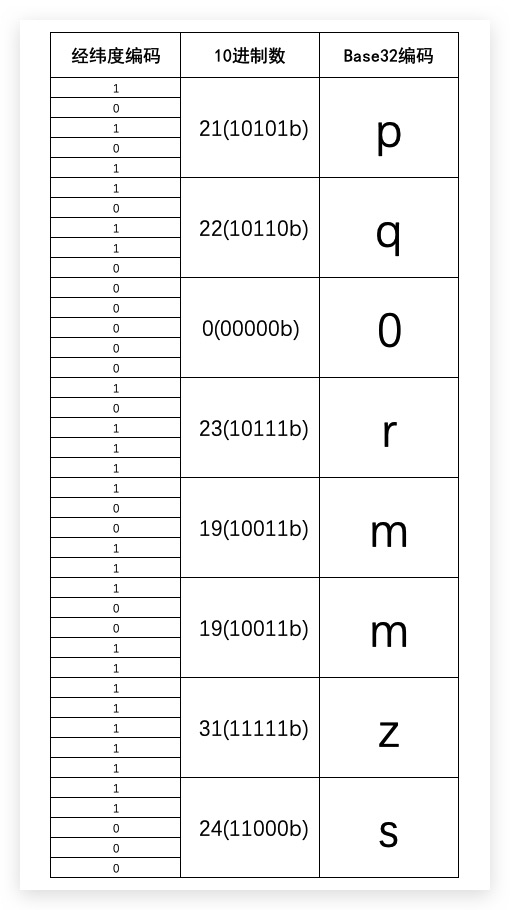
故,最终该经纬度(经度146.842813452468、纬度-54.9432909847213)的GeoHash值即为pq0rmmzs
Note
上文我们提到GeoHash算法计算出来的值实际上表示的是一个矩形网格的区域范围。所以在上述区间二分的过程中,事实上可以不断的持续下去,以获得该经(或纬)度更多位数的编码值,进而缩小该GeoHash值所表示的区域范围,从而能更准确的反映出该经纬度坐标的位置
如果两个网格的GeoHash值共同前缀越长,说明这两个网格区域越接近。这也是为什么在地理信息空间通常将经纬度坐标转换为GeoHash值可以提高查询、检索效率(前缀匹配)。但反之并不成立,即两个很接近的网格区域,可能GeoHash值的共同前缀很短甚至完全没有共同前缀。即所谓的边缘场景,例如两个很邻近的区域如果分别在格林威治子午线(经度为0)的两侧,显然它们的GeoHash值完全没有共同的前缀
GeoHash算法,事实上是空间填充曲线中Z阶曲线(Z-Order Curve)的一种典型应用
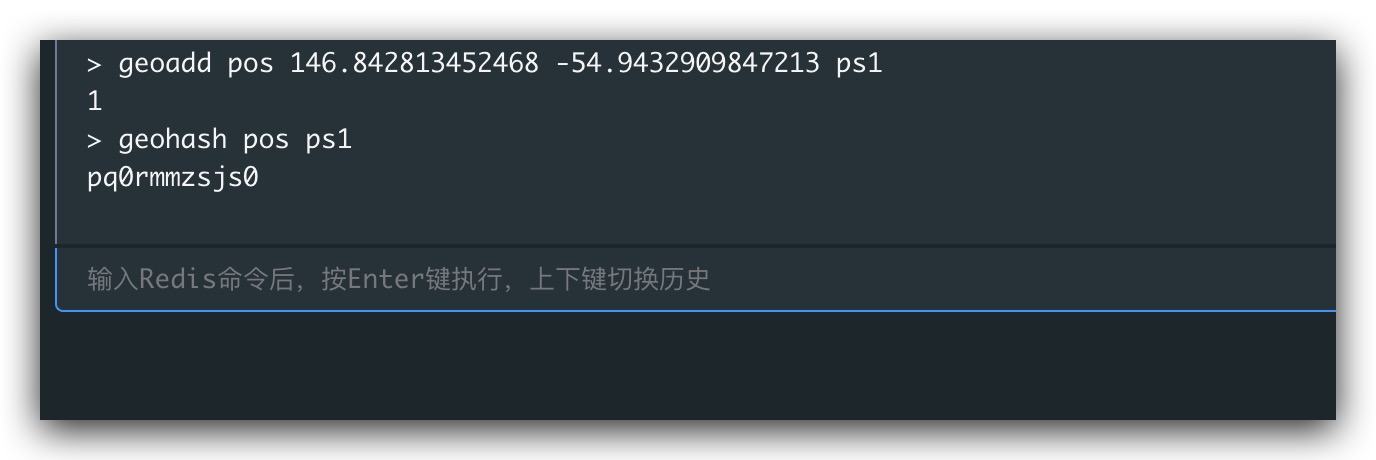
对于Redis而言,其从3.2开始增加了对空间地理位置的支持,提供了GeoHash数据类型。下面即是一个利用geoadd、geohash命令计算经纬度坐标的GeoHash值示例